 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards automated feature engineering for credit card fraud detection using multi-perspective HMMs
Sep 03, 2019

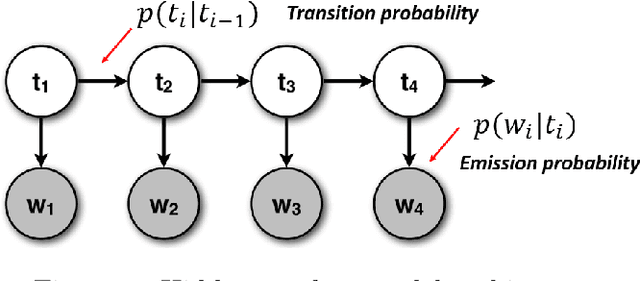

Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this framework, we model a sequence of credit card transactions from three different perspectives, namely (i) The sequence contains or doesn't contain a fraud (ii) The sequence is obtained by fixing the card-holder or the payment terminal (iii) It is a sequence of spent amount or of elapsed time between the current and previous transactions. Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sequences is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. Our multiple perspectives HMM-based approach offers automated feature engineering to model temporal correlations so as to improve the effectiveness of the classification task and allows for an increase in the detection of fraudulent transactions when combined with the state of the art expert based feature engineering strategy for credit card fraud detection. In extension to previous works, we show that this approach goes beyond ecommerce transactions and provides a robust feature engineering over different datasets, hyperparameters and classifiers. Moreover, we compare strategies to deal with structural missing values.
Dataset shift quantification for credit card fraud detection
Jun 17, 2019

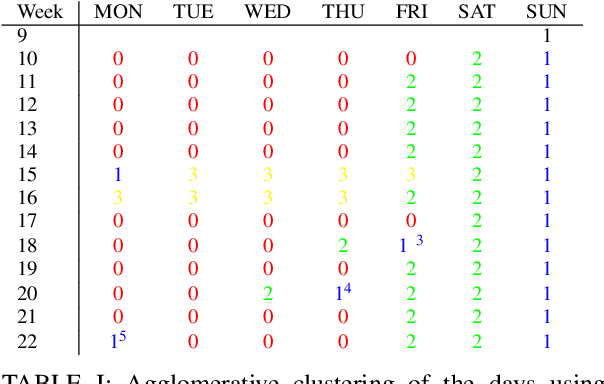
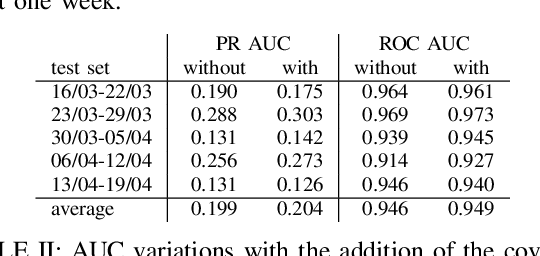
Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However purchase behaviour and fraudster strategies may change over time. This phenomenon is named dataset shift or concept drift in the domain of fraud detection. In this paper, we present a method to quantify day-by-day the dataset shift in our face-to-face credit card transactions dataset (card holder located in the shop) . In practice, we classify the days against each other and measure the efficiency of the classification. The more efficient the classification, the more different the buying behaviour between two days, and vice versa. Therefore, we obtain a distance matrix characterizing the dataset shift. After an agglomerative clustering of the distance matrix, we observe that the dataset shift pattern matches the calendar events for this time period (holidays, week-ends, etc). We then incorporate this dataset shift knowledge in the credit card fraud detection task as a new feature. This leads to a small improvement of the detection.
Multiple perspectives HMM-based feature engineering for credit card fraud detection
May 15, 2019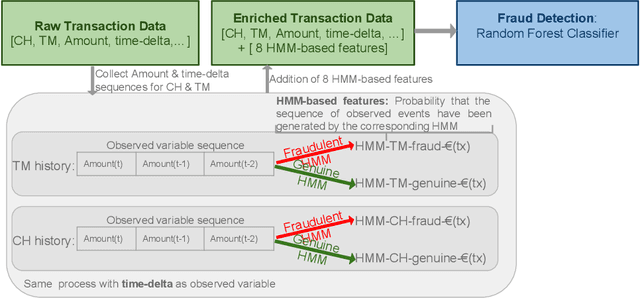
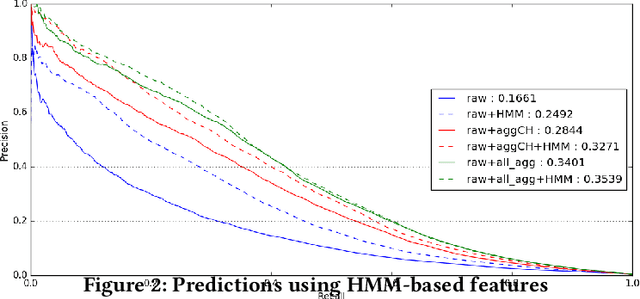
Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this article, we model a sequence of credit card transactions from three different perspectives, namely (i) does the sequence contain a Fraud? (ii) Is the sequence obtained by fixing the card-holder or the payment terminal? (iii) Is it a sequence of spent amount or of elapsed time between the current and previous transactions? Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sets is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. This multiple perspectives HMM-based approach enables an automatic feature engineering in order to model the sequential properties of the dataset with respect to the classification task. This strategy allows for a 15% increase in the precision-recall AUC compared to the state of the art feature engineering strategy for credit card fraud detection.
Ordonnancement d'entités pour la rencontre du web des documents et du web des données
Feb 19, 2016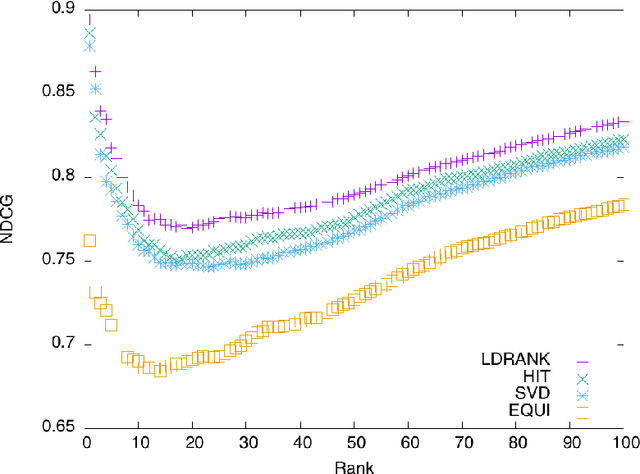


The advances of the Linked Open Data (LOD) initiative are giving rise to a more structured web of data. Indeed, a few datasets act as hubs (e.g., DBpedia) connecting many other datasets. They also made possible new web services for entity detection inside plain text (e.g., DBpedia Spotlight), thus allowing for new applications that will benefit from a combination of the web of documents and the web of data. To ease the emergence of these new use-cases, we propose a query-biased algorithm for the ranking of entities detected inside a web page. Our algorithm combine link analysis with dimensionality reduction. We use crowdsourcing for building a publicly available and reusable dataset on which we compare our algorithm to the state of the art. Finally, we use this algorithm for the construction of semantic snippets for which we evaluate the usability and the usefulness with a crowdsourcing-based approach.