 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning in Real-World Fraud Detection: Challenges and Perspectives
Jul 03, 2023


Data economy relies on data-driven systems and complex machine learning applications are fueled by them. Unfortunately, however, machine learning models are exposed to fraudulent activities and adversarial attacks, which threaten their security and trustworthiness. In the last decade or so, the research interest on adversarial machine learning has grown significantly, revealing how learning applications could be severely impacted by effective attacks. Although early results of adversarial machine learning indicate the huge potential of the approach to specific domains such as image processing, still there is a gap in both the research literature and practice regarding how to generalize adversarial techniques in other domains and applications. Fraud detection is a critical defense mechanism for data economy, as it is for other applications as well, which poses several challenges for machine learning. In this work, we describe how attacks against fraud detection systems differ from other applications of adversarial machine learning, and propose a number of interesting directions to bridge this gap.
Towards automated feature engineering for credit card fraud detection using multi-perspective HMMs
Sep 03, 2019

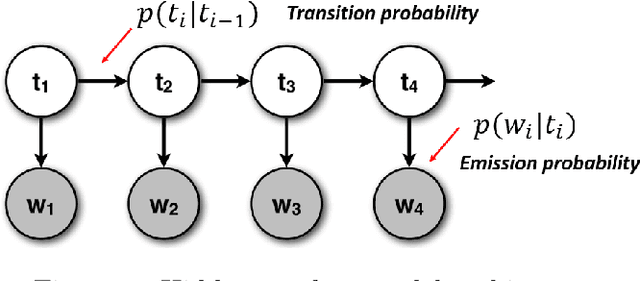

Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this framework, we model a sequence of credit card transactions from three different perspectives, namely (i) The sequence contains or doesn't contain a fraud (ii) The sequence is obtained by fixing the card-holder or the payment terminal (iii) It is a sequence of spent amount or of elapsed time between the current and previous transactions. Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sequences is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. Our multiple perspectives HMM-based approach offers automated feature engineering to model temporal correlations so as to improve the effectiveness of the classification task and allows for an increase in the detection of fraudulent transactions when combined with the state of the art expert based feature engineering strategy for credit card fraud detection. In extension to previous works, we show that this approach goes beyond ecommerce transactions and provides a robust feature engineering over different datasets, hyperparameters and classifiers. Moreover, we compare strategies to deal with structural missing values.
Multiple perspectives HMM-based feature engineering for credit card fraud detection
May 15, 2019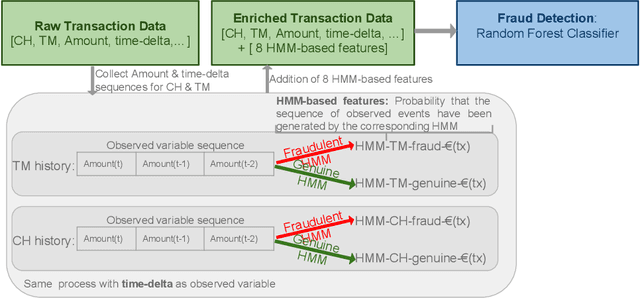
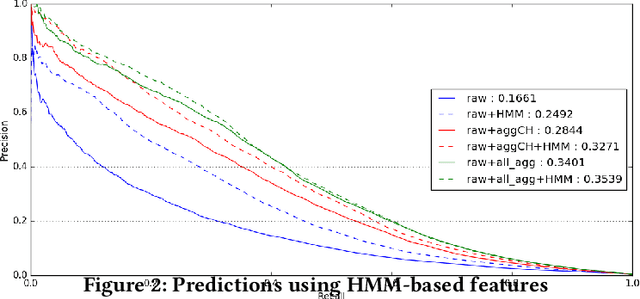
Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this article, we model a sequence of credit card transactions from three different perspectives, namely (i) does the sequence contain a Fraud? (ii) Is the sequence obtained by fixing the card-holder or the payment terminal? (iii) Is it a sequence of spent amount or of elapsed time between the current and previous transactions? Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sets is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. This multiple perspectives HMM-based approach enables an automatic feature engineering in order to model the sequential properties of the dataset with respect to the classification task. This strategy allows for a 15% increase in the precision-recall AUC compared to the state of the art feature engineering strategy for credit card fraud detection.
Streaming Active Learning Strategies for Real-Life Credit Card Fraud Detection: Assessment and Visualization
Apr 20, 2018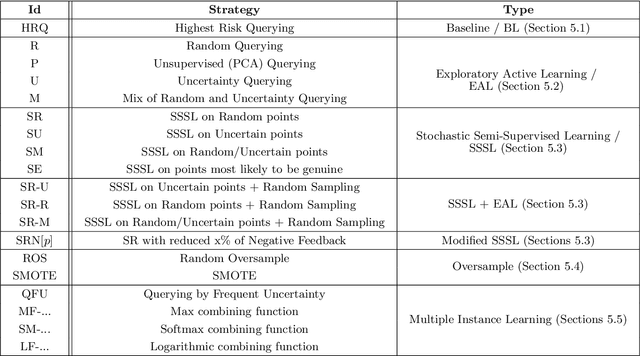
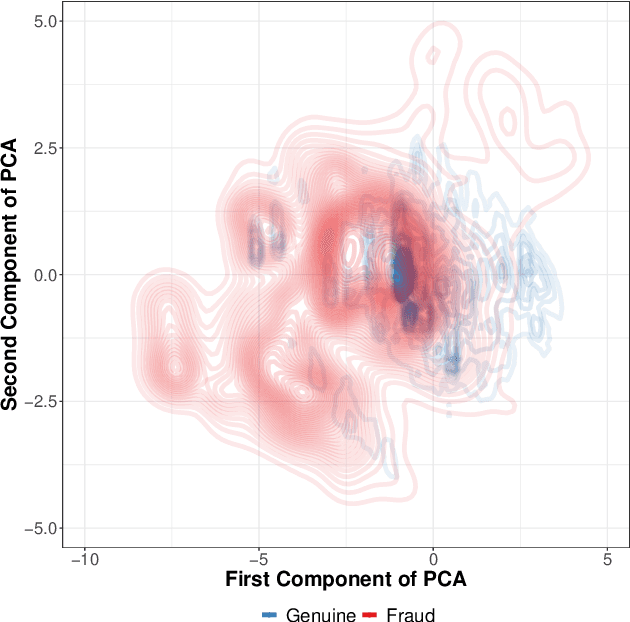

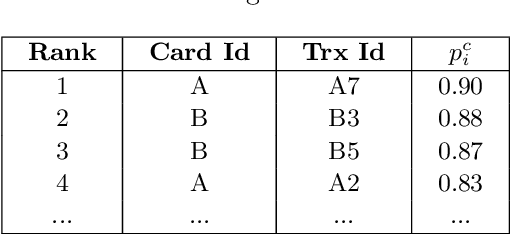
Credit card fraud detection is a very challenging problem because of the specific nature of transaction data and the labeling process. The transaction data is peculiar because they are obtained in a streaming fashion, they are strongly imbalanced and prone to non-stationarity. The labeling is the outcome of an active learning process, as every day human investigators contact only a small number of cardholders (associated to the riskiest transactions) and obtain the class (fraud or genuine) of the related transactions. An adequate selection of the set of cardholders is therefore crucial for an efficient fraud detection process. In this paper, we present a number of active learning strategies and we investigate their fraud detection accuracies. We compare different criteria (supervised, semi-supervised and unsupervised) to query unlabeled transactions. Finally, we highlight the existence of an exploitation/exploration trade-off for active learning in the context of fraud detection, which has so far been overlooked in the literature.