 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANINE: Coaching Visually Impaired Users for Interactive Navigation with a Robot Guide Dog
May 19, 2026Robot guide dogs offer navigation assistance that greatly expands the independent mobility of the visually impaired, but their effective use requires subtle human-robot coordination that is difficult for users to learn from generic verbal instructions. To tackle this challenge, we present CANINE, an automated coaching system that trains users for interactive navigation with a robot guide dog, through personalized, adaptive verbal feedback. CANINE decomposes a complex coordination task into sub-skills and operates at two levels. At the high level, it decides what to train by tracking the learner's proficiency across sub-skills using knowledge tracing and prioritizing training on the weakest areas. At the low level, CANINE decides how to train each sub-skill by observing each human practice episode, using foundation models to infer the underlying causes of errors, and generating targeted verbal corrections adaptively. A controlled study with blindfolded participants, treated as a proxy population for quantitative evaluation, demonstrates that CANINE significantly improves both learning efficiency and final navigation performance compared to generic verbal instructions. We further validate CANINE through a retention study and an exploratory case study. The retention study shows lasting skill improvement after two weeks. The case study confirms CANINE's effectiveness in training a visually impaired user, while revealing additional design considerations for real-world deployment. Both are well aligned with the findings of the controlled study. Project page: https://cunjunyu.github.io/project/canine/
TwinLoop: Simulation-in-the-Loop Digital Twins for Online Multi-Agent Reinforcement Learning
Apr 08, 2026Decentralised online learning enables runtime adaptation in cyber-physical multi-agent systems, but when operating conditions change, learned policies often require substantial trial-and-error interaction before recovering performance. To address this, we propose TwinLoop, a simulation-in-the-loop digital twin framework for online multi-agent reinforcement learning. When a context shift occurs, the digital twin is triggered to reconstruct the current system state, initialise from the latest agent policies, and perform accelerated policy improvement with simulation what-if analysis before synchronising updated parameters back to the agents in the physical system. We evaluate TwinLoop in a vehicular edge computing task-offloading scenario with changing workload and infrastructure conditions. The results suggest that digital twins can improve post-shift adaptation efficiency and reduce reliance on costly online trial-and-error.
SignScene: Visual Sign Grounding for Mapless Navigation
Feb 13, 2026Navigational signs enable humans to navigate unfamiliar environments without maps. This work studies how robots can similarly exploit signs for mapless navigation in the open world. A central challenge lies in interpreting signs: real-world signs are diverse and complex, and their abstract semantic contents need to be grounded in the local 3D scene. We formalize this as sign grounding, the problem of mapping semantic instructions on signs to corresponding scene elements and navigational actions. Recent Vision-Language Models (VLMs) offer the semantic common-sense and reasoning capabilities required for this task, but are sensitive to how spatial information is represented. We propose SignScene, a sign-centric spatial-semantic representation that captures navigation-relevant scene elements and sign information, and presents them to VLMs in a form conducive to effective reasoning. We evaluate our grounding approach on a dataset of 114 queries collected across nine diverse environment types, achieving 88% grounding accuracy and significantly outperforming baselines. Finally, we demonstrate that it enables real-world mapless navigation on a Spot robot using only signs.
TiFRe: Text-guided Video Frame Reduction for Efficient Video Multi-modal Large Language Models
Feb 09, 2026With the rapid development of Large Language Models (LLMs), Video Multi-Modal Large Language Models (Video MLLMs) have achieved remarkable performance in video-language tasks such as video understanding and question answering. However, Video MLLMs face high computational costs, particularly in processing numerous video frames as input, which leads to significant attention computation overhead. A straightforward approach to reduce computational costs is to decrease the number of input video frames. However, simply selecting key frames at a fixed frame rate (FPS) often overlooks valuable information in non-key frames, resulting in notable performance degradation. To address this, we propose Text-guided Video Frame Reduction (TiFRe), a framework that reduces input frames while preserving essential video information. TiFRe uses a Text-guided Frame Sampling (TFS) strategy to select key frames based on user input, which is processed by an LLM to generate a CLIP-style prompt. Pre-trained CLIP encoders calculate the semantic similarity between the prompt and each frame, selecting the most relevant frames as key frames. To preserve video semantics, TiFRe employs a Frame Matching and Merging (FMM) mechanism, which integrates non-key frame information into the selected key frames, minimizing information loss. Experiments show that TiFRe effectively reduces computational costs while improving performance on video-language tasks.
MUSON: A Reasoning-oriented Multimodal Dataset for Socially Compliant Navigation in Urban Environments
Dec 28, 2025Socially compliant navigation requires structured reasoning over dynamic pedestrians and physical constraints to ensure safe and interpretable decisions. However, existing social navigation datasets often lack explicit reasoning supervision and exhibit highly long-tailed action distributions, limiting models' ability to learn safety-critical behaviors. To address these issues, we introduce MUSON, a multimodal dataset for short-horizon social navigation collected across diverse indoor and outdoor campus scenes. MUSON adopts a structured five-step Chain-of-Thought annotation consisting of perception, prediction, reasoning, action, and explanation, with explicit modeling of static physical constraints and a rationally balanced discrete action space. Compared to SNEI, MUSON provides consistent reasoning, action, and explanation. Benchmarking multiple state-of-the-art Small Vision Language Models on MUSON shows that Qwen2.5-VL-3B achieves the highest decision accuracy of 0.8625, demonstrating that MUSON serves as an effective and reusable benchmark for socially compliant navigation. The dataset is publicly available at https://huggingface.co/datasets/MARSLab/MUSON
MAction-SocialNav: Multi-Action Socially Compliant Navigation via Reasoning-enhanced Prompt Tuning
Dec 25, 2025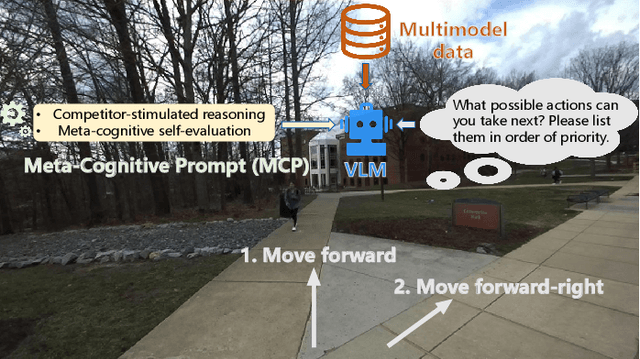
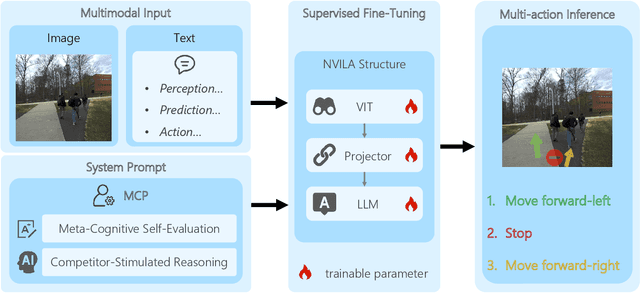


Socially compliant navigation requires robots to move safely and appropriately in human-centered environments by respecting social norms. However, social norms are often ambiguous, and in a single scenario, multiple actions may be equally acceptable. Most existing methods simplify this problem by assuming a single correct action, which limits their ability to handle real-world social uncertainty. In this work, we propose MAction-SocialNav, an efficient vision language model for socially compliant navigation that explicitly addresses action ambiguity, enabling generating multiple plausible actions within one scenario. To enhance the model's reasoning capability, we introduce a novel meta-cognitive prompt (MCP) method. Furthermore, to evaluate the proposed method, we curate a multi-action socially compliant navigation dataset that accounts for diverse conditions, including crowd density, indoor and outdoor environments, and dual human annotations. The dataset contains 789 samples, each with three-turn conversation, split into 710 training samples and 79 test samples through random selection. We also design five evaluation metrics to assess high-level decision precision, safety, and diversity. Extensive experiments demonstrate that the proposed MAction-SocialNav achieves strong social reasoning performance while maintaining high efficiency, highlighting its potential for real-world human robot navigation. Compared with zero-shot GPT-4o and Claude, our model achieves substantially higher decision quality (APG: 0.595 vs. 0.000/0.025) and safety alignment (ER: 0.264 vs. 0.642/0.668), while maintaining real-time efficiency (1.524 FPS, over 3x faster).
BATseg: Boundary-aware Multiclass Spinal Cord Tumor Segmentation on 3D MRI Scans
Dec 09, 2024Spinal cord tumors significantly contribute to neurological morbidity and mortality. Precise morphometric quantification, encompassing the size, location, and type of such tumors, holds promise for optimizing treatment planning strategies. Although recent methods have demonstrated excellent performance in medical image segmentation, they primarily focus on discerning shapes with relatively large morphology such as brain tumors, ignoring the challenging problem of identifying spinal cord tumors which tend to have tiny sizes, diverse locations, and shapes. To tackle this hard problem of multiclass spinal cord tumor segmentation, we propose a new method, called BATseg, to learn a tumor surface distance field by applying our new multiclass boundary-aware loss function. To verify the effectiveness of our approach, we also introduce the first and large-scale spinal cord tumor dataset. It comprises gadolinium-enhanced T1-weighted 3D MRI scans from 653 patients and contains the four most common spinal cord tumor types: astrocytomas, ependymomas, hemangioblastomas, and spinal meningiomas. Extensive experiments on our dataset and another public kidney tumor segmentation dataset show that our proposed method achieves superior performance for multiclass tumor segmentation.
SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
Oct 08, 2024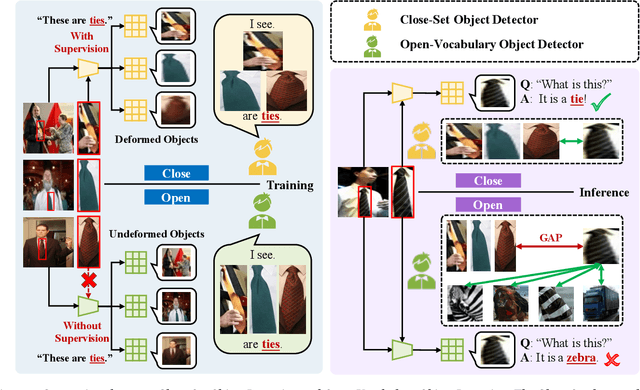
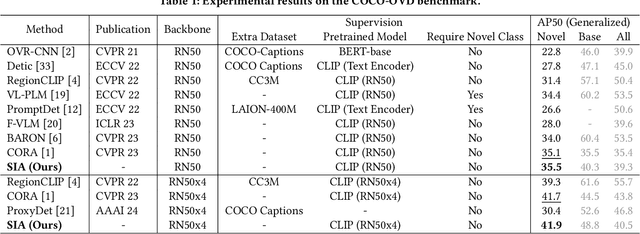
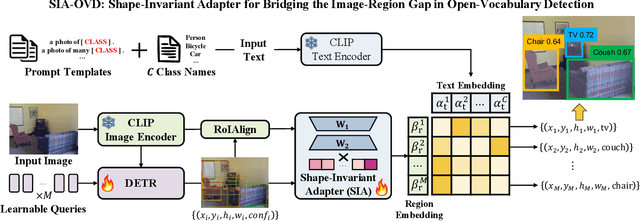
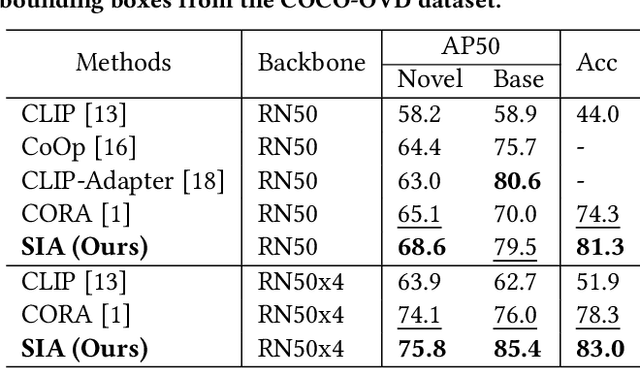
Open-vocabulary detection (OVD) aims to detect novel objects without instance-level annotations to achieve open-world object detection at a lower cost. Existing OVD methods mainly rely on the powerful open-vocabulary image-text alignment capability of Vision-Language Pretrained Models (VLM) such as CLIP. However, CLIP is trained on image-text pairs and lacks the perceptual ability for local regions within an image, resulting in the gap between image and region representations. Directly using CLIP for OVD causes inaccurate region classification. We find the image-region gap is primarily caused by the deformation of region feature maps during region of interest (RoI) extraction. To mitigate the inaccurate region classification in OVD, we propose a new Shape-Invariant Adapter named SIA-OVD to bridge the image-region gap in the OVD task. SIA-OVD learns a set of feature adapters for regions with different shapes and designs a new adapter allocation mechanism to select the optimal adapter for each region. The adapted region representations can align better with text representations learned by CLIP. Extensive experiments demonstrate that SIA-OVD effectively improves the classification accuracy for regions by addressing the gap between images and regions caused by shape deformation. SIA-OVD achieves substantial improvements over representative methods on the COCO-OVD benchmark. The code is available at https://github.com/PKU-ICST-MIPL/SIA-OVD_ACMMM2024.
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment
May 11, 2024Existing action quality assessment (AQA) methods mainly learn deep representations at the video level for scoring diverse actions. Due to the lack of a fine-grained understanding of actions in videos, they harshly suffer from low credibility and interpretability, thus insufficient for stringent applications, such as Olympic diving events. We argue that a fine-grained understanding of actions requires the model to perceive and parse actions in both time and space, which is also the key to the credibility and interpretability of the AQA technique. Based on this insight, we propose a new fine-grained spatial-temporal action parser named \textbf{FineParser}. It learns human-centric foreground action representations by focusing on target action regions within each frame and exploiting their fine-grained alignments in time and space to minimize the impact of invalid backgrounds during the assessment. In addition, we construct fine-grained annotations of human-centric foreground action masks for the FineDiving dataset, called \textbf{FineDiving-HM}. With refined annotations on diverse target action procedures, FineDiving-HM can promote the development of real-world AQA systems. Through extensive experiments, we demonstrate the effectiveness of FineParser, which outperforms state-of-the-art methods while supporting more tasks of fine-grained action understanding. Data and code are available at \url{https://github.com/PKU-ICST-MIPL/FineParser_CVPR2024}.