 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
TopoPerception: A Shortcut-Free Evaluation of Global Visual Perception in Large Vision-Language Models
Nov 14, 2025Large Vision-Language Models (LVLMs) typically align visual features from an encoder with a pre-trained Large Language Model (LLM). However, this makes the visual perception module a bottleneck, which constrains the overall capabilities of LVLMs. Conventional evaluation benchmarks, while rich in visual semantics, often contain unavoidable local shortcuts that can lead to an overestimation of models' perceptual abilities. Here, we introduce TopoPerception, a benchmark that leverages topological properties to rigorously evaluate the global visual perception capabilities of LVLMs across various granularities. Since topology depends on the global structure of an image and is invariant to local features, TopoPerception enables a shortcut-free assessment of global perception, fundamentally distinguishing it from semantically rich tasks. We evaluate state-of-the-art models on TopoPerception and find that even at the coarsest perceptual granularity, all models perform no better than random chance, indicating a profound inability to perceive global visual features. Notably, a consistent trend emerge within model families: more powerful models with stronger reasoning capabilities exhibit lower accuracy. This suggests that merely scaling up models is insufficient to address this deficit and may even exacerbate it. Progress may require new training paradigms or architectures. TopoPerception not only exposes a critical bottleneck in current LVLMs but also offers a lens and direction for improving their global visual perception. The data and code are publicly available at: https://github.com/Wenhao-Zhou/TopoPerception.
SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
Oct 08, 2024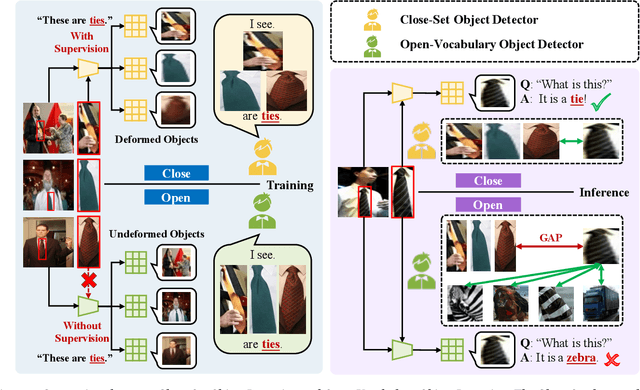
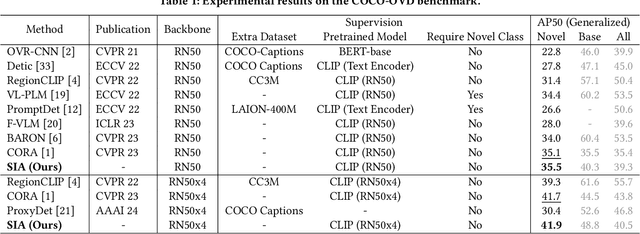
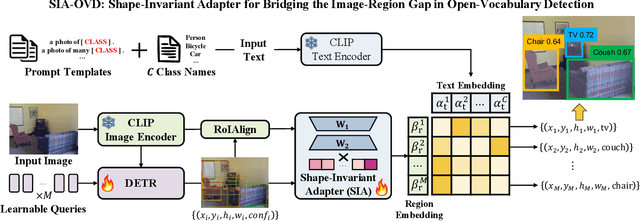
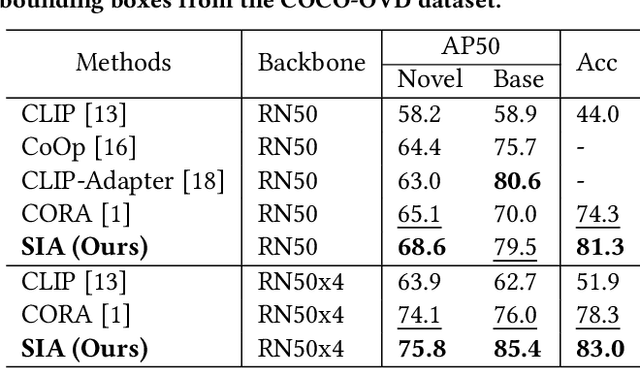
Open-vocabulary detection (OVD) aims to detect novel objects without instance-level annotations to achieve open-world object detection at a lower cost. Existing OVD methods mainly rely on the powerful open-vocabulary image-text alignment capability of Vision-Language Pretrained Models (VLM) such as CLIP. However, CLIP is trained on image-text pairs and lacks the perceptual ability for local regions within an image, resulting in the gap between image and region representations. Directly using CLIP for OVD causes inaccurate region classification. We find the image-region gap is primarily caused by the deformation of region feature maps during region of interest (RoI) extraction. To mitigate the inaccurate region classification in OVD, we propose a new Shape-Invariant Adapter named SIA-OVD to bridge the image-region gap in the OVD task. SIA-OVD learns a set of feature adapters for regions with different shapes and designs a new adapter allocation mechanism to select the optimal adapter for each region. The adapted region representations can align better with text representations learned by CLIP. Extensive experiments demonstrate that SIA-OVD effectively improves the classification accuracy for regions by addressing the gap between images and regions caused by shape deformation. SIA-OVD achieves substantial improvements over representative methods on the COCO-OVD benchmark. The code is available at https://github.com/PKU-ICST-MIPL/SIA-OVD_ACMMM2024.