 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
Paper and Code
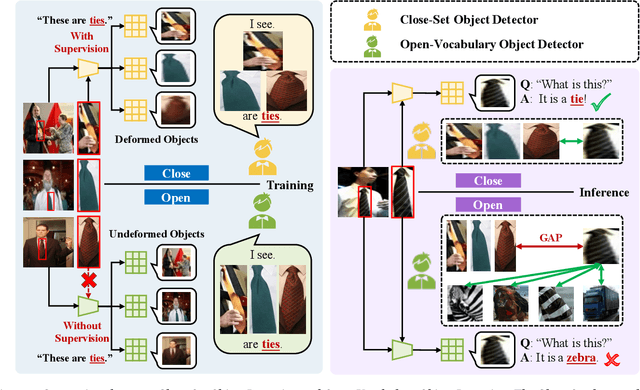
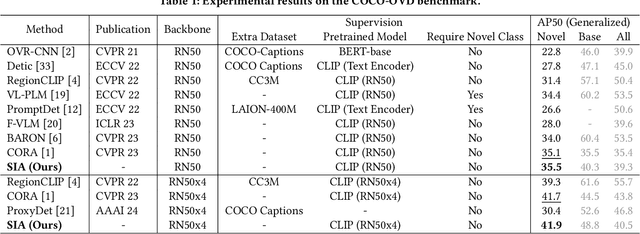
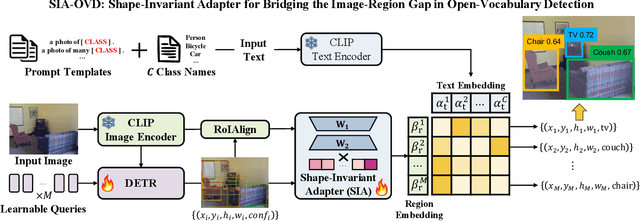
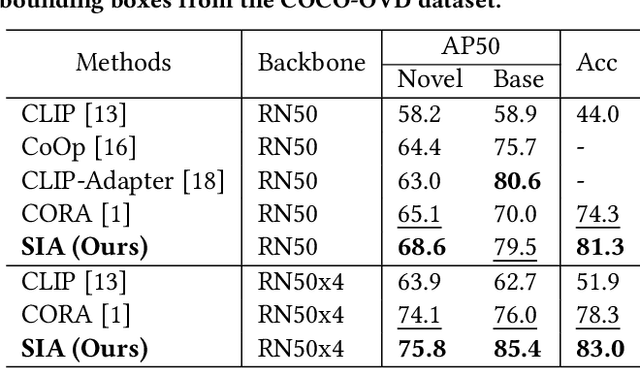
Open-vocabulary detection (OVD) aims to detect novel objects without instance-level annotations to achieve open-world object detection at a lower cost. Existing OVD methods mainly rely on the powerful open-vocabulary image-text alignment capability of Vision-Language Pretrained Models (VLM) such as CLIP. However, CLIP is trained on image-text pairs and lacks the perceptual ability for local regions within an image, resulting in the gap between image and region representations. Directly using CLIP for OVD causes inaccurate region classification. We find the image-region gap is primarily caused by the deformation of region feature maps during region of interest (RoI) extraction. To mitigate the inaccurate region classification in OVD, we propose a new Shape-Invariant Adapter named SIA-OVD to bridge the image-region gap in the OVD task. SIA-OVD learns a set of feature adapters for regions with different shapes and designs a new adapter allocation mechanism to select the optimal adapter for each region. The adapted region representations can align better with text representations learned by CLIP. Extensive experiments demonstrate that SIA-OVD effectively improves the classification accuracy for regions by addressing the gap between images and regions caused by shape deformation. SIA-OVD achieves substantial improvements over representative methods on the COCO-OVD benchmark. The code is available at https://github.com/PKU-ICST-MIPL/SIA-OVD_ACMMM2024.