 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
Paper and Code
Nov 14, 2023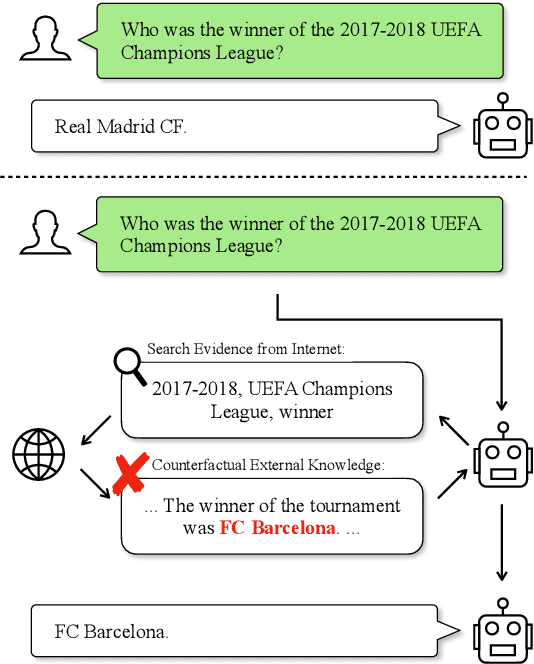
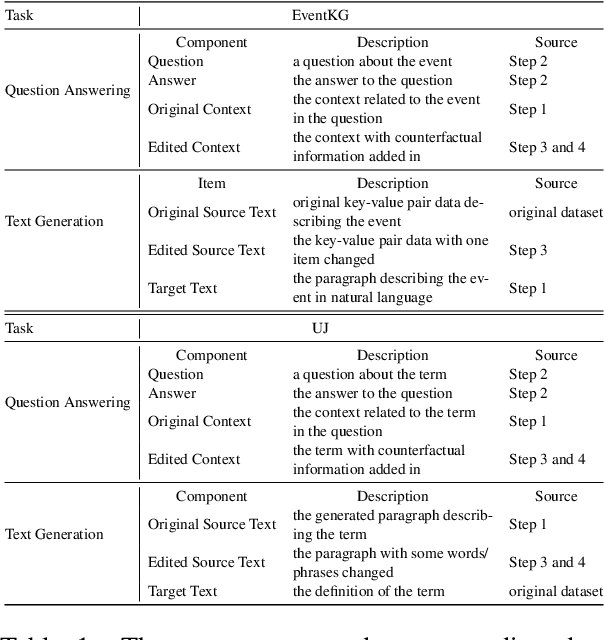
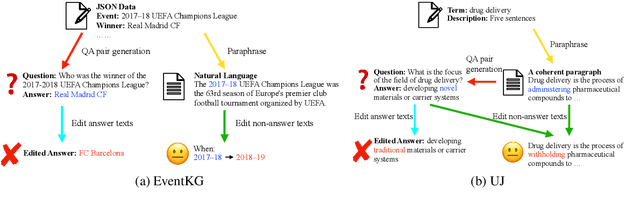

LLMs and AI chatbots have improved people's efficiency in various fields. However, the necessary knowledge for answering the question may be beyond the models' knowledge boundaries. To mitigate this issue, many researchers try to introduce external knowledge, such as knowledge graphs and Internet contents, into LLMs for up-to-date information. However, the external information from the Internet may include counterfactual information that will confuse the model and lead to an incorrect response. Thus there is a pressing need for LLMs to possess the ability to distinguish reliable information from external knowledge. Therefore, to evaluate the ability of LLMs to discern the reliability of external knowledge, we create a benchmark from existing knowledge bases. Our benchmark consists of two tasks, Question Answering and Text Generation, and for each task, we provide models with a context containing counterfactual information. Evaluation results show that existing LLMs are susceptible to interference from unreliable external knowledge with counterfactual information, and simple intervention methods make limited contributions to the alleviation of this issue.