 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHints of Prompt: Enhancing Visual Representation for Multimodal LLMs in Autonomous Driving
Nov 20, 2024



In light of the dynamic nature of autonomous driving environments and stringent safety requirements, general MLLMs combined with CLIP alone often struggle to represent driving-specific scenarios accurately, particularly in complex interactions and long-tail cases. To address this, we propose the Hints of Prompt (HoP) framework, which introduces three key enhancements: Affinity hint to emphasize instance-level structure by strengthening token-wise connections, Semantic hint to incorporate high-level information relevant to driving-specific cases, such as complex interactions among vehicles and traffic signs, and Question hint to align visual features with the query context, focusing on question-relevant regions. These hints are fused through a Hint Fusion module, enriching visual representations and enhancing multimodal reasoning for autonomous driving VQA tasks. Extensive experiments confirm the effectiveness of the HoP framework, showing it significantly outperforms previous state-of-the-art methods across all key metrics.
Noise-Resistant Deep Metric Learning with Probabilistic Instance Filtering
Aug 03, 2021
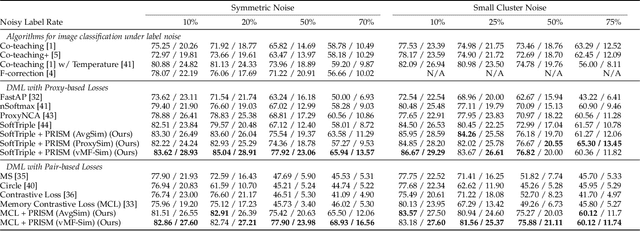

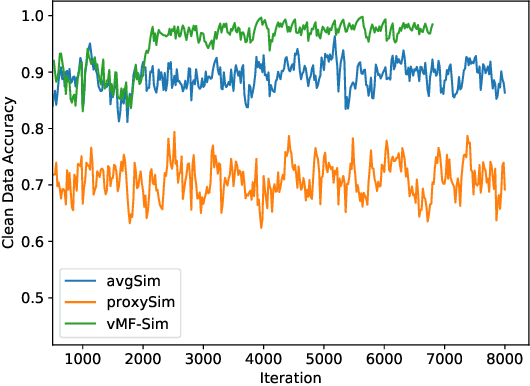
Noisy labels are commonly found in real-world data, which cause performance degradation of deep neural networks. Cleaning data manually is labour-intensive and time-consuming. Previous research mostly focuses on enhancing classification models against noisy labels, while the robustness of deep metric learning (DML) against noisy labels remains less well-explored. In this paper, we bridge this important gap by proposing Probabilistic Ranking-based Instance Selection with Memory (PRISM) approach for DML. PRISM calculates the probability of a label being clean, and filters out potentially noisy samples. Specifically, we propose three methods to calculate this probability: 1) Average Similarity Method (AvgSim), which calculates the average similarity between potentially noisy data and clean data; 2) Proxy Similarity Method (ProxySim), which replaces the centers maintained by AvgSim with the proxies trained by proxy-based method; and 3) von Mises-Fisher Distribution Similarity (vMF-Sim), which estimates a von Mises-Fisher distribution for each data class. With such a design, the proposed approach can deal with challenging DML situations in which the majority of the samples are noisy. Extensive experiments on both synthetic and real-world noisy dataset show that the proposed approach achieves up to 8.37% higher Precision@1 compared with the best performing state-of-the-art baseline approaches, within reasonable training time.
Video Imprint
Jun 07, 2021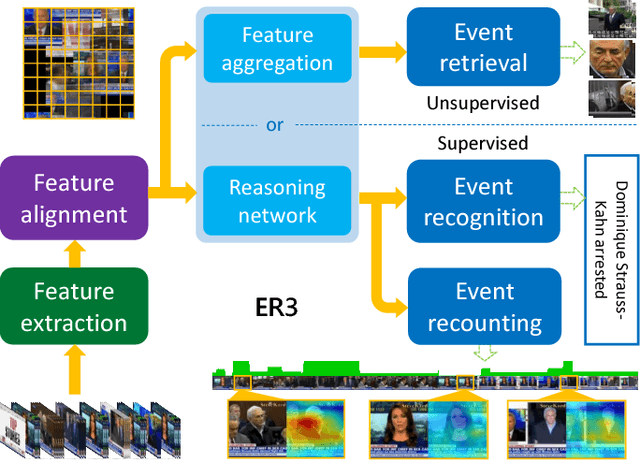


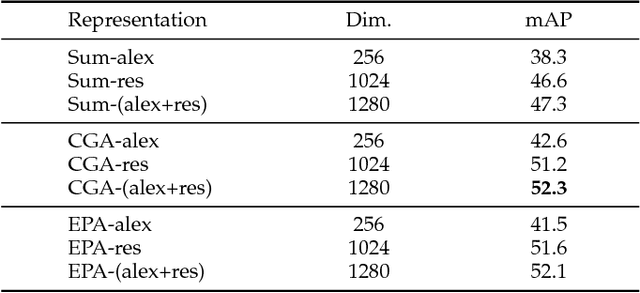
A new unified video analytics framework (ER3) is proposed for complex event retrieval, recognition and recounting, based on the proposed video imprint representation, which exploits temporal correlations among image features across video frames. With the video imprint representation, it is convenient to reverse map back to both temporal and spatial locations in video frames, allowing for both key frame identification and key areas localization within each frame. In the proposed framework, a dedicated feature alignment module is incorporated for redundancy removal across frames to produce the tensor representation, i.e., the video imprint. Subsequently, the video imprint is individually fed into both a reasoning network and a feature aggregation module, for event recognition/recounting and event retrieval tasks, respectively. Thanks to its attention mechanism inspired by the memory networks used in language modeling, the proposed reasoning network is capable of simultaneous event category recognition and localization of the key pieces of evidence for event recounting. In addition, the latent structure in our reasoning network highlights the areas of the video imprint, which can be directly used for event recounting. With the event retrieval task, the compact video representation aggregated from the video imprint contributes to better retrieval results than existing state-of-the-art methods.
Noise-resistant Deep Metric Learning with Ranking-based Instance Selection
Apr 12, 2021



The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving robustness to noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains open. In this paper, we propose a noise-resistant training technique for DML, which we name Probabilistic Ranking-based Instance Selection with Memory (PRISM). PRISM identifies noisy data in a minibatch using average similarity against image features extracted by several previous versions of the neural network. These features are stored in and retrieved from a memory bank. To alleviate the high computational cost brought by the memory bank, we introduce an acceleration method that replaces individual data points with the class centers. In extensive comparisons with 12 existing approaches under both synthetic and real-world label noise, PRISM demonstrates superior performance of up to 6.06% in Precision@1.
Intrinsic Temporal Regularization for High-resolution Human Video Synthesis
Dec 11, 2020


Temporal consistency is crucial for extending image processing pipelines to the video domain, which is often enforced with flow-based warping error over adjacent frames. Yet for human video synthesis, such scheme is less reliable due to the misalignment between source and target video as well as the difficulty in accurate flow estimation. In this paper, we propose an effective intrinsic temporal regularization scheme to mitigate these issues, where an intrinsic confidence map is estimated via the frame generator to regulate motion estimation via temporal loss modulation. This creates a shortcut for back-propagating temporal loss gradients directly to the front-end motion estimator, thus improving training stability and temporal coherence in output videos. We apply our intrinsic temporal regulation to single-image generator, leading to a powerful "INTERnet" capable of generating $512\times512$ resolution human action videos with temporal-coherent, realistic visual details. Extensive experiments demonstrate the superiority of proposed INTERnet over several competitive baselines.
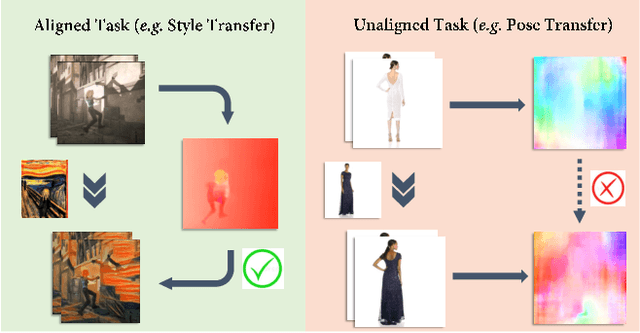
Implicit Subspace Prior Learning for Dual-Blind Face Restoration
Oct 12, 2020
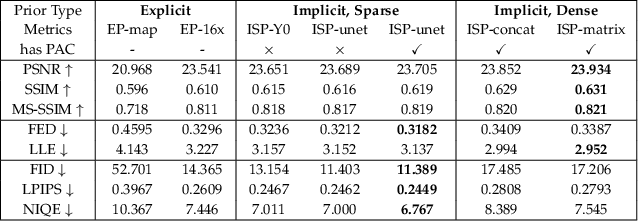

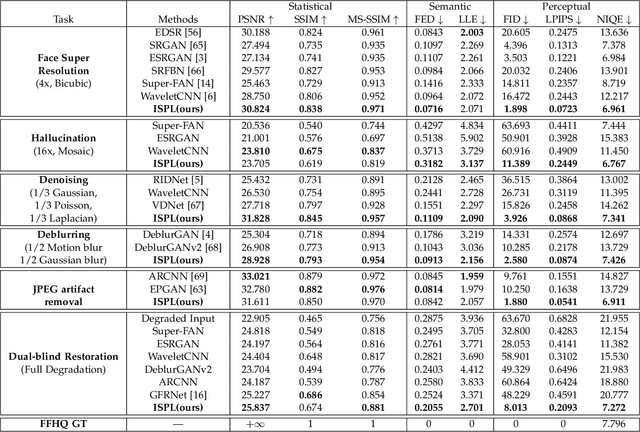
Face restoration is an inherently ill-posed problem, where additional prior constraints are typically considered crucial for mitigating such pathology. However, real-world image prior are often hard to simulate with precise mathematical models, which inevitably limits the performance and generalization ability of existing prior-regularized restoration methods. In this paper, we study the problem of face restoration under a more practical ``dual blind'' setting, i.e., without prior assumptions or hand-crafted regularization terms on the degradation profile or image contents. To this end, a novel implicit subspace prior learning (ISPL) framework is proposed as a generic solution to dual-blind face restoration, with two key elements: 1) an implicit formulation to circumvent the ill-defined restoration mapping and 2) a subspace prior decomposition and fusion mechanism to dynamically handle inputs at varying degradation levels with consistent high-quality restoration results. Experimental results demonstrate significant perception-distortion improvement of ISPL against existing state-of-the-art methods for a variety of restoration subtasks, including a 3.69db PSNR and 45.8% FID gain against ESRGAN, the 2018 NTIRE SR challenge winner. Overall, we prove that it is possible to capture and utilize prior knowledge without explicitly formulating it, which will help inspire new research paradigms towards low-level vision tasks.
Towards Fine-grained Human Pose Transfer with Detail Replenishing Network
May 26, 2020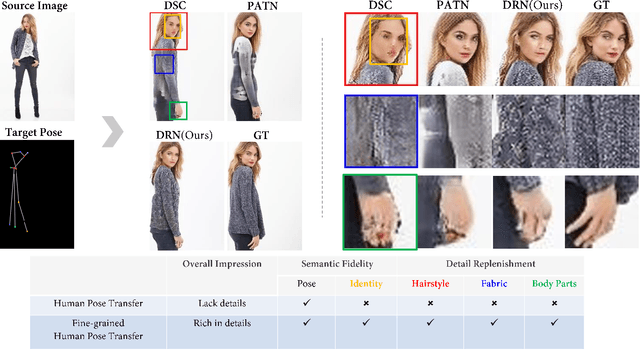
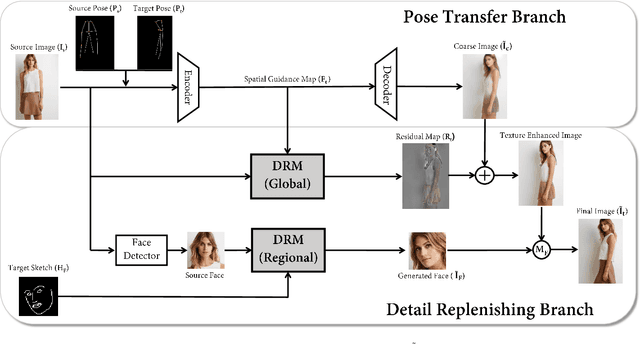
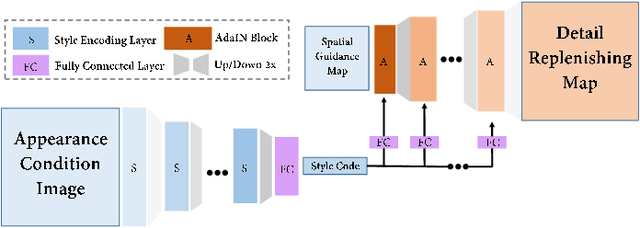

Human pose transfer (HPT) is an emerging research topic with huge potential in fashion design, media production, online advertising and virtual reality. For these applications, the visual realism of fine-grained appearance details is crucial for production quality and user engagement. However, existing HPT methods often suffer from three fundamental issues: detail deficiency, content ambiguity and style inconsistency, which severely degrade the visual quality and realism of generated images. Aiming towards real-world applications, we develop a more challenging yet practical HPT setting, termed as Fine-grained Human Pose Transfer (FHPT), with a higher focus on semantic fidelity and detail replenishment. Concretely, we analyze the potential design flaws of existing methods via an illustrative example, and establish the core FHPT methodology by combing the idea of content synthesis and feature transfer together in a mutually-guided fashion. Thereafter, we substantiate the proposed methodology with a Detail Replenishing Network (DRN) and a corresponding coarse-to-fine model training scheme. Moreover, we build up a complete suite of fine-grained evaluation protocols to address the challenges of FHPT in a comprehensive manner, including semantic analysis, structural detection and perceptual quality assessment. Extensive experiments on the DeepFashion benchmark dataset have verified the power of proposed benchmark against start-of-the-art works, with 12\%-14\% gain on top-10 retrieval recall, 5\% higher joint localization accuracy, and near 40\% gain on face identity preservation. Moreover, the evaluation results offer further insights to the subject matter, which could inspire many promising future works along this direction.
Region-adaptive Texture Enhancement for Detailed Person Image Synthesis
May 26, 2020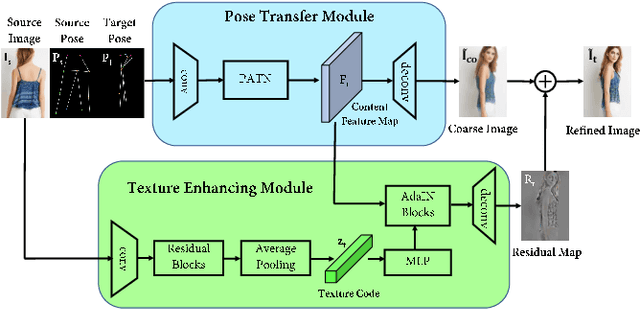



The ability to produce convincing textural details is essential for the fidelity of synthesized person images. However, existing methods typically follow a ``warping-based'' strategy that propagates appearance features through the same pathway used for pose transfer. However, most fine-grained features would be lost due to down-sampling, leading to over-smoothed clothes and missing details in the output images. In this paper we presents RATE-Net, a novel framework for synthesizing person images with sharp texture details. The proposed framework leverages an additional texture enhancing module to extract appearance information from the source image and estimate a fine-grained residual texture map, which helps to refine the coarse estimation from the pose transfer module. In addition, we design an effective alternate updating strategy to promote mutual guidance between two modules for better shape and appearance consistency. Experiments conducted on DeepFashion benchmark dataset have demonstrated the superiority of our framework compared with existing networks.
Ladder Loss for Coherent Visual-Semantic Embedding
Nov 18, 2019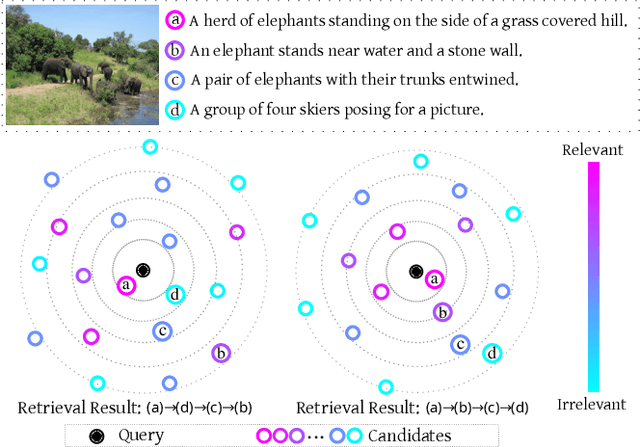
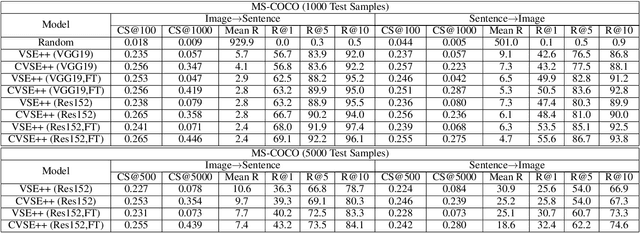

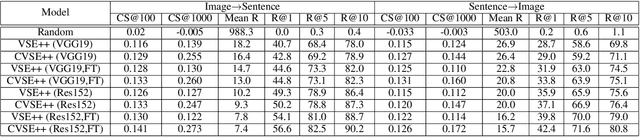
For visual-semantic embedding, the existing methods normally treat the relevance between queries and candidates in a bipolar way -- relevant or irrelevant, and all "irrelevant" candidates are uniformly pushed away from the query by an equal margin in the embedding space, regardless of their various proximity to the query. This practice disregards relatively discriminative information and could lead to suboptimal ranking in the retrieval results and poorer user experience, especially in the long-tail query scenario where a matching candidate may not necessarily exist. In this paper, we introduce a continuous variable to model the relevance degree between queries and multiple candidates, and propose to learn a coherent embedding space, where candidates with higher relevance degrees are mapped closer to the query than those with lower relevance degrees. In particular, the new ladder loss is proposed by extending the triplet loss inequality to a more general inequality chain, which implements variable push-away margins according to respective relevance degrees. In addition, a proper Coherent Score metric is proposed to better measure the ranking results including those "irrelevant" candidates. Extensive experiments on multiple datasets validate the efficacy of our proposed method, which achieves significant improvement over existing state-of-the-art methods.
EleAtt-RNN: Adding Attentiveness to Neurons in Recurrent Neural Networks
Sep 03, 2019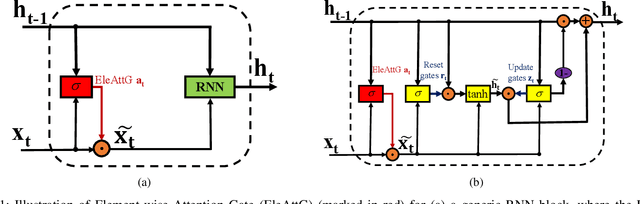
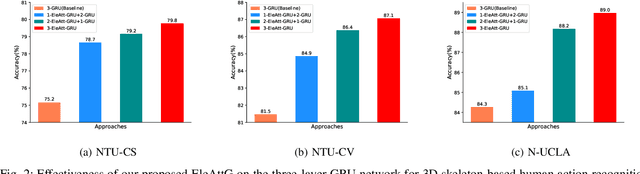


Recurrent neural networks (RNNs) are capable of modeling temporal dependencies of complex sequential data. In general, current available structures of RNNs tend to concentrate on controlling the contributions of current and previous information. However, the exploration of different importance levels of different elements within an input vector is always ignored. We propose a simple yet effective Element-wise-Attention Gate (EleAttG), which can be easily added to an RNN block (e.g. all RNN neurons in an RNN layer), to empower the RNN neurons to have attentiveness capability. For an RNN block, an EleAttG is used for adaptively modulating the input by assigning different levels of importance, i.e., attention, to each element/dimension of the input. We refer to an RNN block equipped with an EleAttG as an EleAtt-RNN block. Instead of modulating the input as a whole, the EleAttG modulates the input at fine granularity, i.e., element-wise, and the modulation is content adaptive. The proposed EleAttG, as an additional fundamental unit, is general and can be applied to any RNN structures, e.g., standard RNN, Long Short-Term Memory (LSTM), or Gated Recurrent Unit (GRU). We demonstrate the effectiveness of the proposed EleAtt-RNN by applying it to different tasks including the action recognition, from both skeleton-based data and RGB videos, gesture recognition, and sequential MNIST classification. Experiments show that adding attentiveness through EleAttGs to RNN blocks significantly improves the power of RNNs.