 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Variational Motion Prior for Video-based Motion Capture
Oct 28, 2022Motion capture from a monocular video is fundamental and crucial for us humans to naturally experience and interact with each other in Virtual Reality (VR) and Augmented Reality (AR). However, existing methods still struggle with challenging cases involving self-occlusion and complex poses due to the lack of effective motion prior modeling. In this paper, we present a novel variational motion prior (VMP) learning approach for video-based motion capture to resolve the above issue. Instead of directly building the correspondence between the video and motion domain, We propose to learn a generic latent space for capturing the prior distribution of all natural motions, which serve as the basis for subsequent video-based motion capture tasks. To improve the generalization capacity of prior space, we propose a transformer-based variational autoencoder pretrained over marker-based 3D mocap data, with a novel style-mapping block to boost the generation quality. Afterward, a separate video encoder is attached to the pretrained motion generator for end-to-end fine-tuning over task-specific video datasets. Compared to existing motion prior models, our VMP model serves as a motion rectifier that can effectively reduce temporal jittering and failure modes in frame-wise pose estimation, leading to temporally stable and visually realistic motion capture results. Furthermore, our VMP-based framework models motion at sequence level and can directly generate motion clips in the forward pass, achieving real-time motion capture during inference. Extensive experiments over both public datasets and in-the-wild videos have demonstrated the efficacy and generalization capability of our framework.
Thousand to One: Semantic Prior Modeling for Conceptual Coding
Mar 16, 2021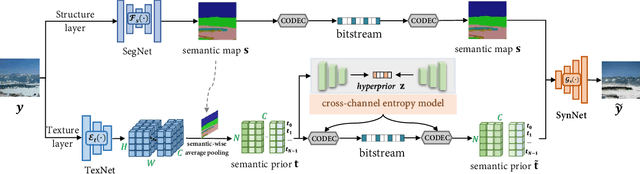
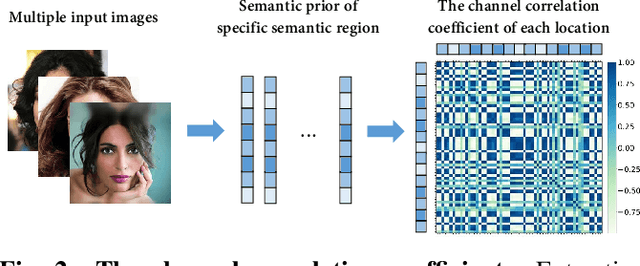

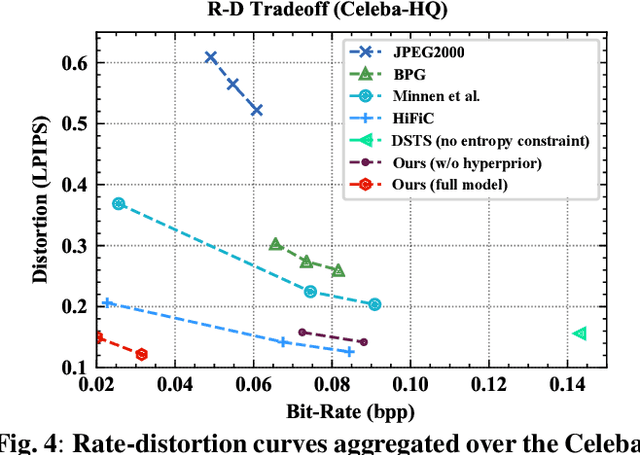
Conceptual coding has been an emerging research topic recently, which encodes natural images into disentangled conceptual representations for compression. However, the compression performance of the existing methods is still sub-optimal due to the lack of comprehensive consideration of rate constraint and reconstruction quality. To this end, we propose a novel end-to-end semantic prior modeling-based conceptual coding scheme towards extremely low bitrate image compression, which leverages semantic-wise deep representations as a unified prior for entropy estimation and texture synthesis. Specifically, we employ semantic segmentation maps as structural guidance for extracting deep semantic prior, which provides fine-grained texture distribution modeling for better detail construction and higher flexibility in subsequent high-level vision tasks. Moreover, a cross-channel entropy model is proposed to further exploit the inter-channel correlation of the spatially independent semantic prior, leading to more accurate entropy estimation for rate-constrained training. The proposed scheme achieves an ultra-high 1000x compression ratio, while still enjoying high visual reconstruction quality and versatility towards visual processing and analysis tasks.
Intrinsic Temporal Regularization for High-resolution Human Video Synthesis
Dec 11, 2020


Temporal consistency is crucial for extending image processing pipelines to the video domain, which is often enforced with flow-based warping error over adjacent frames. Yet for human video synthesis, such scheme is less reliable due to the misalignment between source and target video as well as the difficulty in accurate flow estimation. In this paper, we propose an effective intrinsic temporal regularization scheme to mitigate these issues, where an intrinsic confidence map is estimated via the frame generator to regulate motion estimation via temporal loss modulation. This creates a shortcut for back-propagating temporal loss gradients directly to the front-end motion estimator, thus improving training stability and temporal coherence in output videos. We apply our intrinsic temporal regulation to single-image generator, leading to a powerful "INTERnet" capable of generating $512\times512$ resolution human action videos with temporal-coherent, realistic visual details. Extensive experiments demonstrate the superiority of proposed INTERnet over several competitive baselines.
Conceptual Compression via Deep Structure and Texture Synthesis
Nov 10, 2020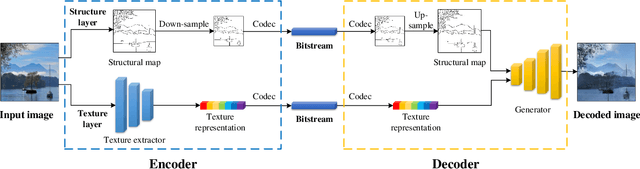
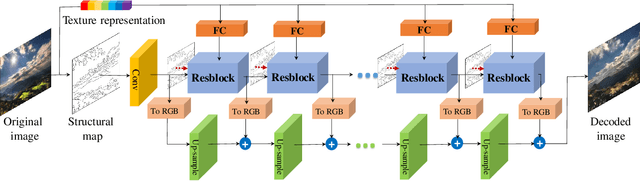
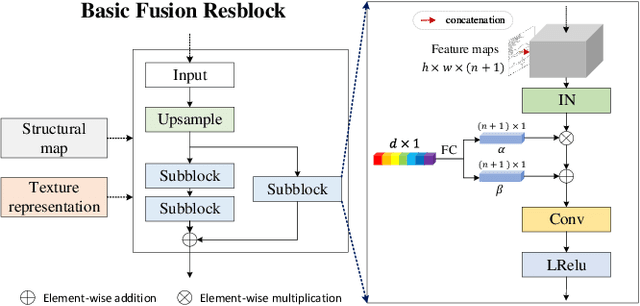
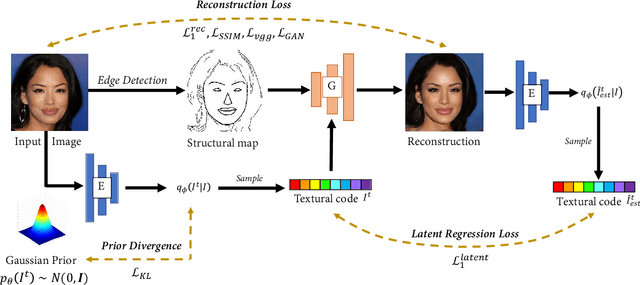
Existing compression methods typically focus on the removal of signal-level redundancies, while the potential and versatility of decomposing visual data into compact conceptual components still lack further study. To this end, we propose a novel conceptual compression framework that encodes visual data into compact structure and texture representations, then decodes in a deep synthesis fashion, aiming to achieve better visual reconstruction quality, flexible content manipulation, and potential support for various vision tasks. In particular, we propose to compress images by a dual-layered model consisting of two complementary visual features: 1) structure layer represented by structural maps and 2) texture layer characterized by low-dimensional deep representations. At the encoder side, the structural maps and texture representations are individually extracted and compressed, generating the compact, interpretable, inter-operable bitstreams. During the decoding stage, a hierarchical fusion GAN (HF-GAN) is proposed to learn the synthesis paradigm where the textures are rendered into the decoded structural maps, leading to high-quality reconstruction with remarkable visual realism. Extensive experiments on diverse images have demonstrated the superiority of our framework with lower bitrates, higher reconstruction quality, and increased versatility towards visual analysis and content manipulation tasks.
Implicit Subspace Prior Learning for Dual-Blind Face Restoration
Oct 12, 2020
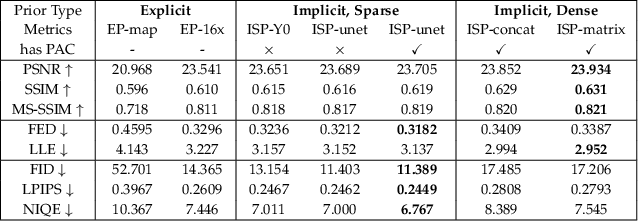

Face restoration is an inherently ill-posed problem, where additional prior constraints are typically considered crucial for mitigating such pathology. However, real-world image prior are often hard to simulate with precise mathematical models, which inevitably limits the performance and generalization ability of existing prior-regularized restoration methods. In this paper, we study the problem of face restoration under a more practical ``dual blind'' setting, i.e., without prior assumptions or hand-crafted regularization terms on the degradation profile or image contents. To this end, a novel implicit subspace prior learning (ISPL) framework is proposed as a generic solution to dual-blind face restoration, with two key elements: 1) an implicit formulation to circumvent the ill-defined restoration mapping and 2) a subspace prior decomposition and fusion mechanism to dynamically handle inputs at varying degradation levels with consistent high-quality restoration results. Experimental results demonstrate significant perception-distortion improvement of ISPL against existing state-of-the-art methods for a variety of restoration subtasks, including a 3.69db PSNR and 45.8% FID gain against ESRGAN, the 2018 NTIRE SR challenge winner. Overall, we prove that it is possible to capture and utilize prior knowledge without explicitly formulating it, which will help inspire new research paradigms towards low-level vision tasks.
Progressive Semantic-Aware Style Transformation for Blind Face Restoration
Sep 18, 2020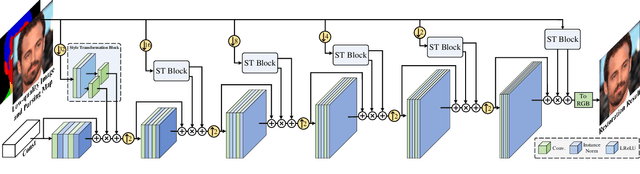



Face restoration is important in face image processing, and has been widely studied in recent years. However, previous works often fail to generate plausible high quality (HQ) results for real-world low quality (LQ) face images. In this paper, we propose a new progressive semantic-aware style transformation framework, named PSFR-GAN, for face restoration. Specifically, instead of using an encoder-decoder framework as previous methods, we formulate the restoration of LQ face images as a multi-scale progressive restoration procedure through semantic-aware style transformation. Given a pair of LQ face image and its corresponding parsing map, we first generate a multi-scale pyramid of the inputs, and then progressively modulate different scale features from coarse-to-fine in a semantic-aware style transfer way. Compared with previous networks, the proposed PSFR-GAN makes full use of the semantic (parsing maps) and pixel (LQ images) space information from different scales of input pairs. In addition, we further introduce a semantic aware style loss which calculates the feature style loss for each semantic region individually to improve the details of face textures. Finally, we pretrain a face parsing network which can generate decent parsing maps from real-world LQ face images. Experiment results show that our model trained with synthetic data can not only produce more realistic high-resolution results for synthetic LQ inputs and but also generalize better to natural LQ face images compared with state-of-the-art methods. Codes are available at https://github.com/chaofengc/PSFRGAN.
Towards Fine-grained Human Pose Transfer with Detail Replenishing Network
May 26, 2020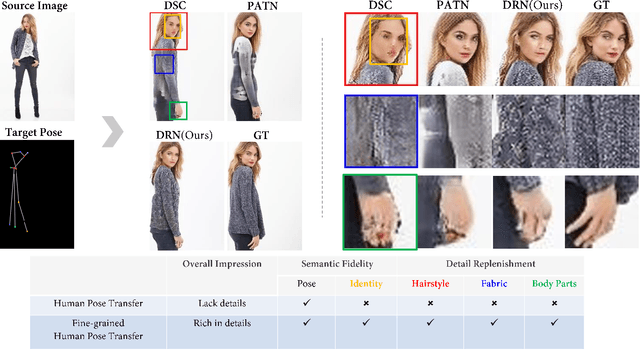
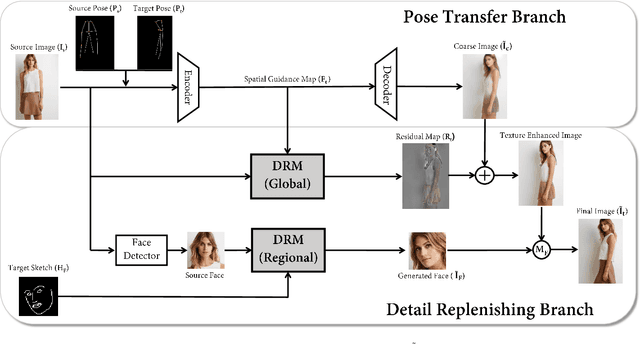
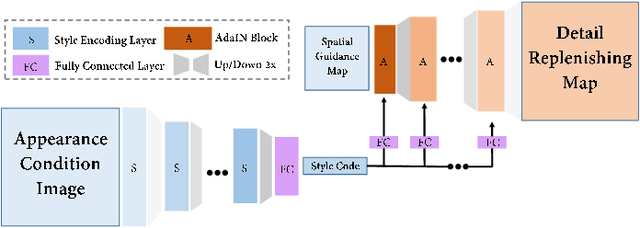

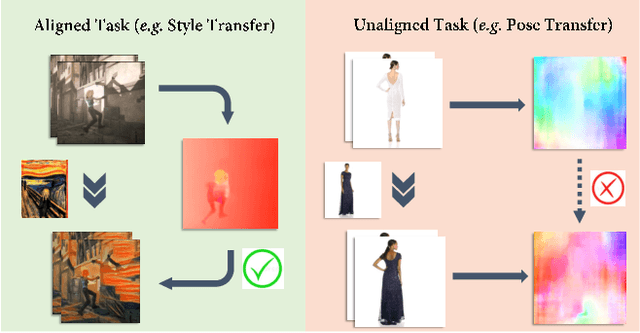
Human pose transfer (HPT) is an emerging research topic with huge potential in fashion design, media production, online advertising and virtual reality. For these applications, the visual realism of fine-grained appearance details is crucial for production quality and user engagement. However, existing HPT methods often suffer from three fundamental issues: detail deficiency, content ambiguity and style inconsistency, which severely degrade the visual quality and realism of generated images. Aiming towards real-world applications, we develop a more challenging yet practical HPT setting, termed as Fine-grained Human Pose Transfer (FHPT), with a higher focus on semantic fidelity and detail replenishment. Concretely, we analyze the potential design flaws of existing methods via an illustrative example, and establish the core FHPT methodology by combing the idea of content synthesis and feature transfer together in a mutually-guided fashion. Thereafter, we substantiate the proposed methodology with a Detail Replenishing Network (DRN) and a corresponding coarse-to-fine model training scheme. Moreover, we build up a complete suite of fine-grained evaluation protocols to address the challenges of FHPT in a comprehensive manner, including semantic analysis, structural detection and perceptual quality assessment. Extensive experiments on the DeepFashion benchmark dataset have verified the power of proposed benchmark against start-of-the-art works, with 12\%-14\% gain on top-10 retrieval recall, 5\% higher joint localization accuracy, and near 40\% gain on face identity preservation. Moreover, the evaluation results offer further insights to the subject matter, which could inspire many promising future works along this direction.
Region-adaptive Texture Enhancement for Detailed Person Image Synthesis
May 26, 2020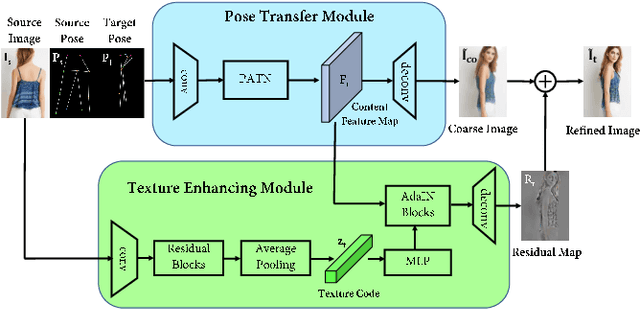



The ability to produce convincing textural details is essential for the fidelity of synthesized person images. However, existing methods typically follow a ``warping-based'' strategy that propagates appearance features through the same pathway used for pose transfer. However, most fine-grained features would be lost due to down-sampling, leading to over-smoothed clothes and missing details in the output images. In this paper we presents RATE-Net, a novel framework for synthesizing person images with sharp texture details. The proposed framework leverages an additional texture enhancing module to extract appearance information from the source image and estimate a fine-grained residual texture map, which helps to refine the coarse estimation from the pose transfer module. In addition, we design an effective alternate updating strategy to promote mutual guidance between two modules for better shape and appearance consistency. Experiments conducted on DeepFashion benchmark dataset have demonstrated the superiority of our framework compared with existing networks.
HiFaceGAN: Face Renovation via Collaborative Suppression and Replenishment
May 11, 2020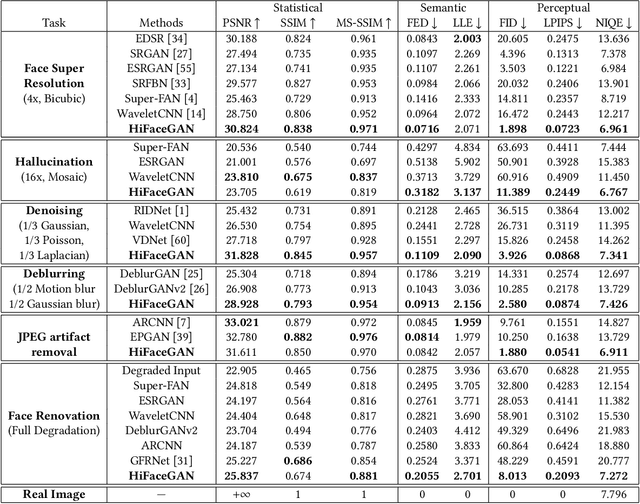


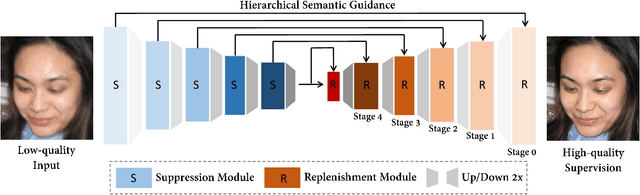
Existing face restoration researches typically relies on either the degradation prior or explicit guidance labels for training, which often results in limited generalization ability over real-world images with heterogeneous degradations and rich background contents. In this paper, we investigate the more challenging and practical "dual-blind" version of the problem by lifting the requirements on both types of prior, termed as "Face Renovation"(FR). Specifically, we formulated FR as a semantic-guided generation problem and tackle it with a collaborative suppression and replenishment (CSR) approach. This leads to HiFaceGAN, a multi-stage framework containing several nested CSR units that progressively replenish facial details based on the hierarchical semantic guidance extracted from the front-end content-adaptive suppression modules. Extensive experiments on both synthetic and real face images have verified the superior performance of HiFaceGAN over a wide range of challenging restoration subtasks, demonstrating its versatility, robustness and generalization ability towards real-world face processing applications.