 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoPCNS: Monocular 3D Object Detection via Point Cloud Network Simulation
Paper and Code
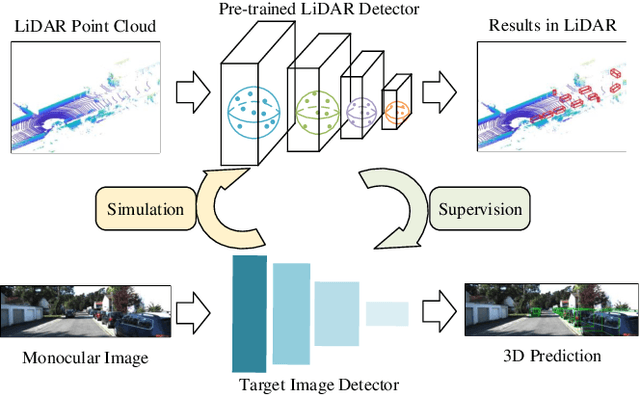
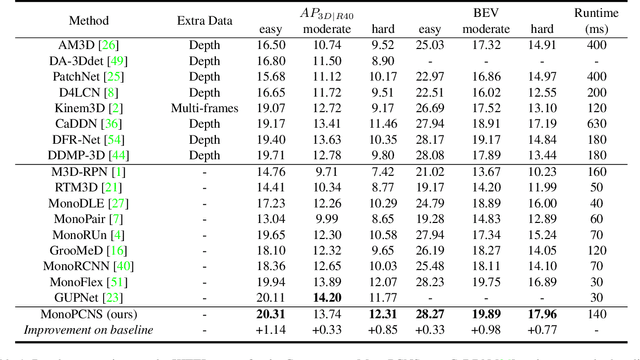
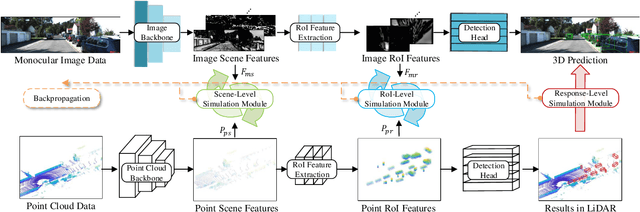
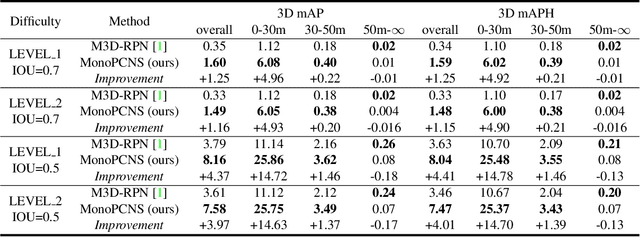
Monocular 3D object detection is a fundamental but very important task to many applications including autonomous driving, robotic grasping and augmented reality. Existing leading methods tend to estimate the depth of the input image first, and detect the 3D object based on point cloud. This routine suffers from the inherent gap between depth estimation and object detection. Besides, the prediction error accumulation would also affect the performance. In this paper, a novel method named MonoPCNS is proposed. The insight behind introducing MonoPCNS is that we propose to simulate the feature learning behavior of a point cloud based detector for monocular detector during the training period. Hence, during inference period, the learned features and prediction would be similar to the point cloud based detector as possible. To achieve it, we propose one scene-level simulation module, one RoI-level simulation module and one response-level simulation module, which are progressively used for the detector's full feature learning and prediction pipeline. We apply our method to the famous M3D-RPN detector and CaDDN detector, conducting extensive experiments on KITTI and Waymo Open dataset. Results show that our method consistently improves the performance of different monocular detectors for a large margin without changing their network architectures. Our method finally achieves state-of-the-art performance.