 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMAP: Universal SMILES-Graph Representation Learning
Paper and Code
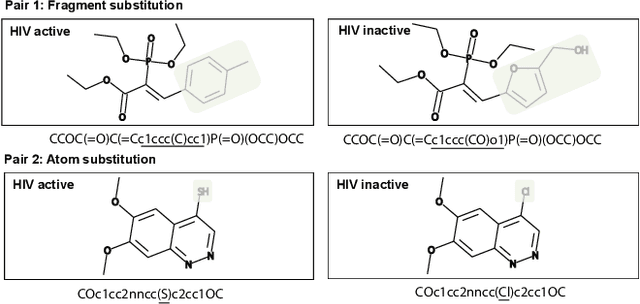
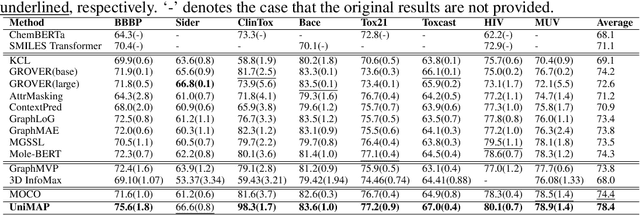
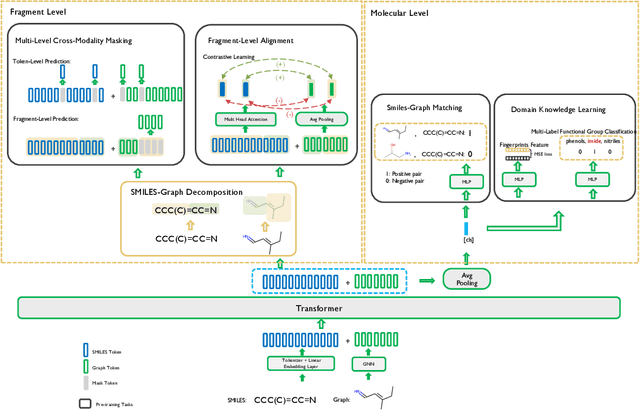
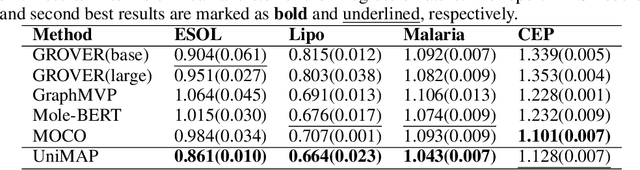
Molecular representation learning is fundamental for many drug related applications. Most existing molecular pre-training models are limited in using single molecular modality, either SMILES or graph representation. To effectively leverage both modalities, we argue that it is critical to capture the fine-grained 'semantics' between SMILES and graph, because subtle sequence/graph differences may lead to contrary molecular properties. In this paper, we propose a universal SMILE-graph representation learning model, namely UniMAP. Firstly, an embedding layer is employed to obtain the token and node/edge representation in SMILES and graph, respectively. A multi-layer Transformer is then utilized to conduct deep cross-modality fusion. Specially, four kinds of pre-training tasks are designed for UniMAP, including Multi-Level Cross-Modality Masking (CMM), SMILES-Graph Matching (SGM), Fragment-Level Alignment (FLA), and Domain Knowledge Learning (DKL). In this way, both global (i.e. SGM and DKL) and local (i.e. CMM and FLA) alignments are integrated to achieve comprehensive cross-modality fusion. We evaluate UniMAP on various downstream tasks, i.e. molecular property prediction, drug-target affinity prediction and drug-drug interaction. Experimental results show that UniMAP outperforms current state-of-the-art pre-training methods.We also visualize the learned representations to demonstrate the effect of multi-modality integration.