 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemGrasp: Semantic Grasp Generation via Language Aligned Discretization
Paper and Code
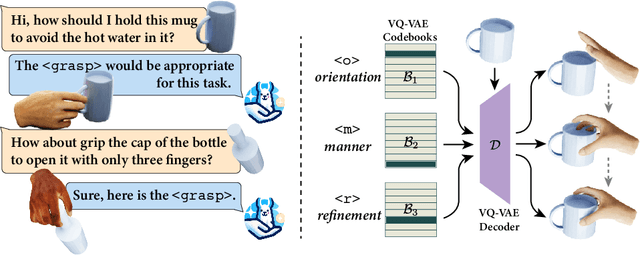
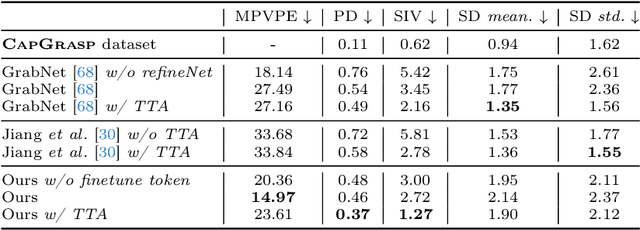
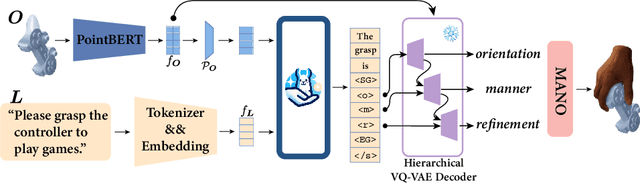

Generating natural human grasps necessitates consideration of not just object geometry but also semantic information. Solely depending on object shape for grasp generation confines the applications of prior methods in downstream tasks. This paper presents a novel semantic-based grasp generation method, termed SemGrasp, which generates a static human grasp pose by incorporating semantic information into the grasp representation. We introduce a discrete representation that aligns the grasp space with semantic space, enabling the generation of grasp postures in accordance with language instructions. A Multimodal Large Language Model (MLLM) is subsequently fine-tuned, integrating object, grasp, and language within a unified semantic space. To facilitate the training of SemGrasp, we have compiled a large-scale, grasp-text-aligned dataset named CapGrasp, featuring about 260k detailed captions and 50k diverse grasps. Experimental findings demonstrate that SemGrasp efficiently generates natural human grasps in alignment with linguistic intentions. Our code, models, and dataset are available publicly at: https://kailinli.github.io/SemGrasp.