 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Layer Swapping for Zero-Shot Cross-Lingual Transfer in Large Language Models
Oct 02, 2024



Model merging, such as model souping, is the practice of combining different models with the same architecture together without further training. In this work, we present a model merging methodology that addresses the difficulty of fine-tuning Large Language Models (LLMs) for target tasks in non-English languages, where task-specific data is often unavailable. We focus on mathematical reasoning and without in-language math data, facilitate cross-lingual transfer by composing language and math capabilities. Starting from the same pretrained model, we fine-tune separate "experts" on math instruction data in English and on generic instruction data in the target language. We then replace the top and bottom transformer layers of the math expert directly with layers from the language expert, which consequently enhances math performance in the target language. The resulting merged models outperform the individual experts and other merging methods on the math benchmark, MGSM, by 10% across four major languages where math instruction data is scarce. In addition, this layer swapping is simple, inexpensive, and intuitive, as it is based on an interpretative analysis of the most important parameter changes during the fine-tuning of each expert. The ability to successfully re-compose LLMs for cross-lingual transfer in this manner opens up future possibilities to combine model expertise, create modular solutions, and transfer reasoning capabilities across languages all post hoc.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
A Systematic Classification of Knowledge, Reasoning, and Context within the ARC Dataset
Jun 01, 2018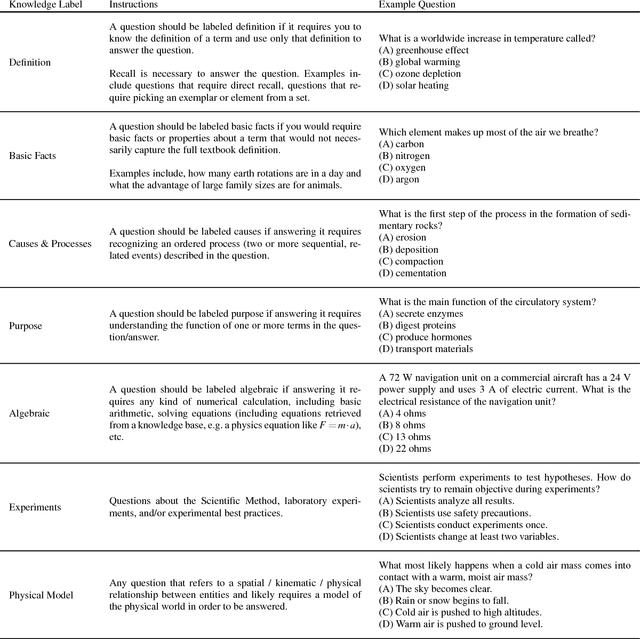
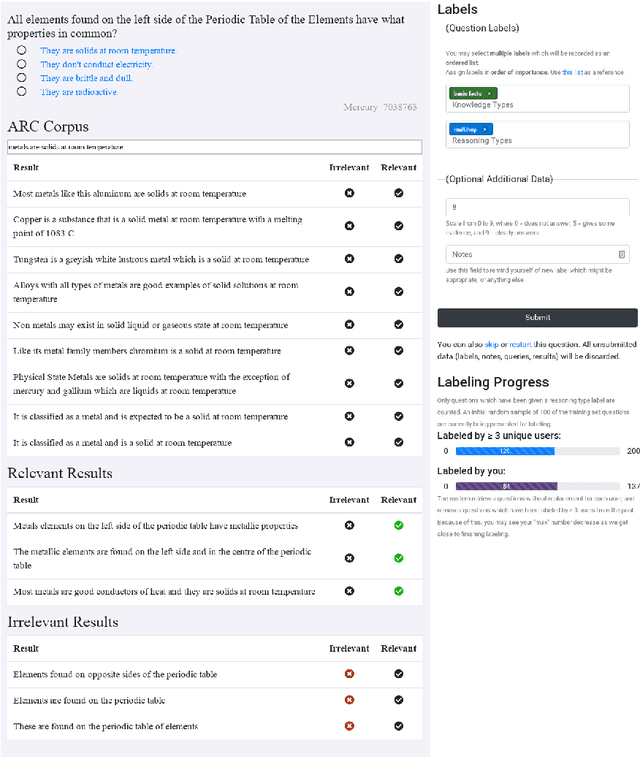
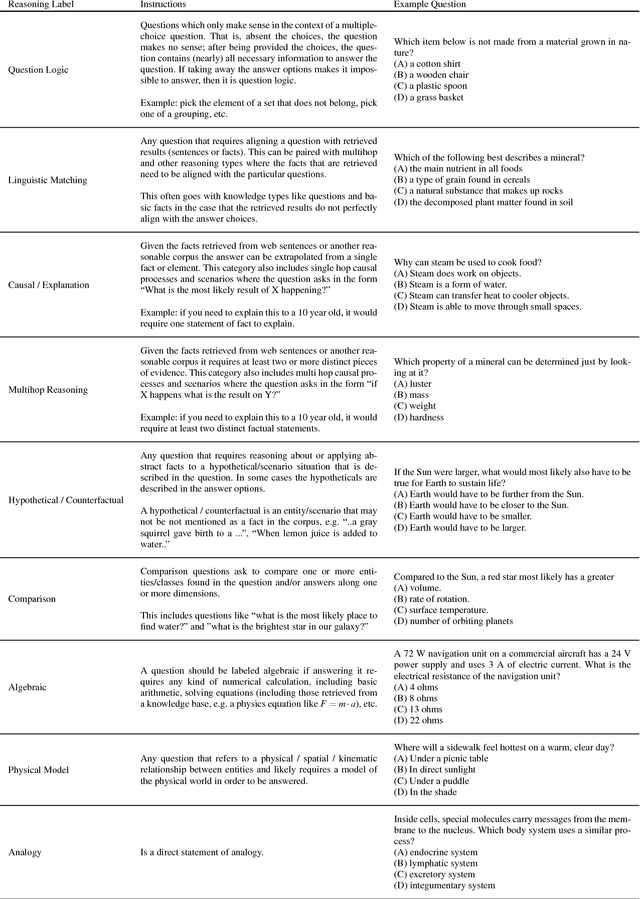
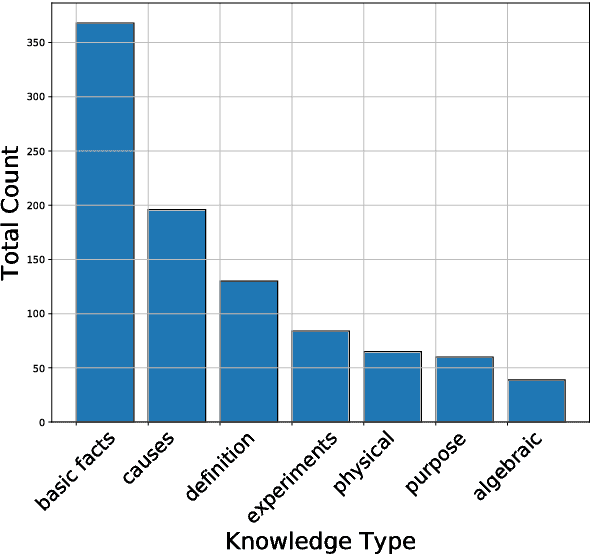
The recent work of Clark et al. introduces the AI2 Reasoning Challenge (ARC) and the associated ARC dataset that partitions open domain, complex science questions into an Easy Set and a Challenge Set. That paper includes an analysis of 100 questions with respect to the types of knowledge and reasoning required to answer them; however, it does not include clear definitions of these types, nor does it offer information about the quality of the labels. We propose a comprehensive set of definitions of knowledge and reasoning types necessary for answering the questions in the ARC dataset. Using ten annotators and a sophisticated annotation interface, we analyze the distribution of labels across the Challenge Set and statistics related to them. Additionally, we demonstrate that although naive information retrieval methods return sentences that are irrelevant to answering the query, sufficient supporting text is often present in the (ARC) corpus. Evaluating with human-selected relevant sentences improves the performance of a neural machine comprehension model by 42 points.
Modified Apriori Graph Algorithm for Frequent Pattern Mining
Apr 27, 2018

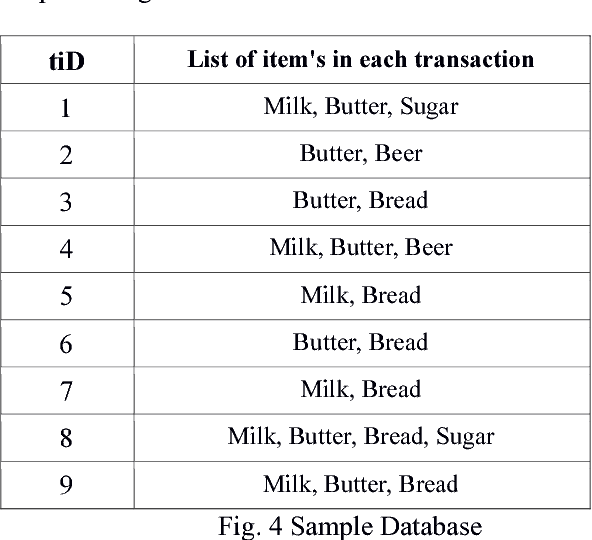
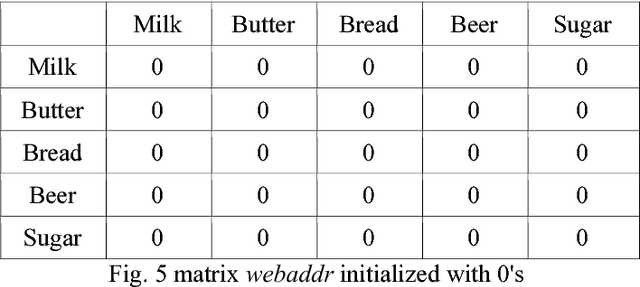
Web Usage Mining is an application of Data Mining Techniques to discover interesting usage patterns from web data in order to understand and better serve the needs of web-based applications. The paper proposes an algorithm for finding these usage patterns using a modified version of Apriori Algorithm called Apriori-Graph. These rules will help service providers to predict, which web pages, the user is likely to visit next. This will optimize the website in terms of efficiency, bandwidth and will have positive economic benefits for them. The proposed Apriori Graph Algorithm O((V)(E)) works faster compared to the existing Apriori Algorithm and is well suitable for real-time application.