 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Dynamics in Knowledge Distillation for Language Models
Jan 21, 2026Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from large language models to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three large language model (LLM) families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Improving Fairness and Robustness in End-to-End Speech Recognition through unsupervised clustering
Jun 06, 2023



The challenge of fairness arises when Automatic Speech Recognition (ASR) systems do not perform equally well for all sub-groups of the population. In the past few years there have been many improvements in overall speech recognition quality, but without any particular focus on advancing Equality and Equity for all user groups for whom systems do not perform well. ASR fairness is therefore also a robustness issue. Meanwhile, data privacy also takes priority in production systems. In this paper, we present a privacy preserving approach to improve fairness and robustness of end-to-end ASR without using metadata, zip codes, or even speaker or utterance embeddings directly in training. We extract utterance level embeddings using a speaker ID model trained on a public dataset, which we then use in an unsupervised fashion to create acoustic clusters. We use cluster IDs instead of speaker utterance embeddings as extra features during model training, which shows improvements for all demographic groups and in particular for different accents.
Text Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023
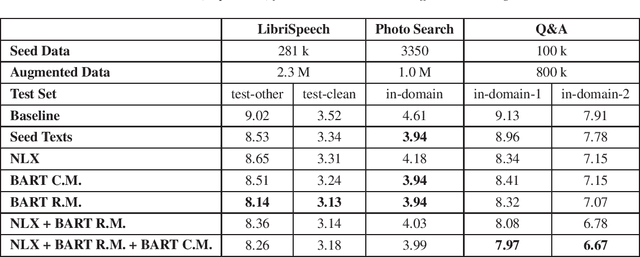
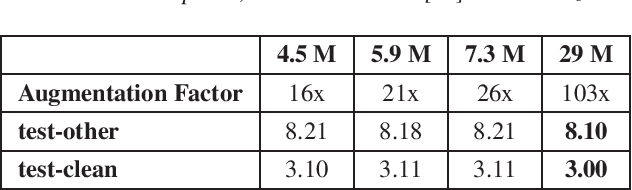
Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
Synthetic Cross-accent Data Augmentation for Automatic Speech Recognition
Mar 01, 2023


The awareness for biased ASR datasets or models has increased notably in recent years. Even for English, despite a vast amount of available training data, systems perform worse for non-native speakers. In this work, we improve an accent-conversion model (ACM) which transforms native US-English speech into accented pronunciation. We include phonetic knowledge in the ACM training to provide accurate feedback about how well certain pronunciation patterns were recovered in the synthesized waveform. Furthermore, we investigate the feasibility of learned accent representations instead of static embeddings. Generated data was then used to train two state-of-the-art ASR systems. We evaluated our approach on native and non-native English datasets and found that synthetically accented data helped the ASR to better understand speech from seen accents. This observation did not translate to unseen accents, and it was not observed for a model that had been pre-trained exclusively with native speech.
Model-Based Approach for Measuring the Fairness in ASR
Sep 19, 2021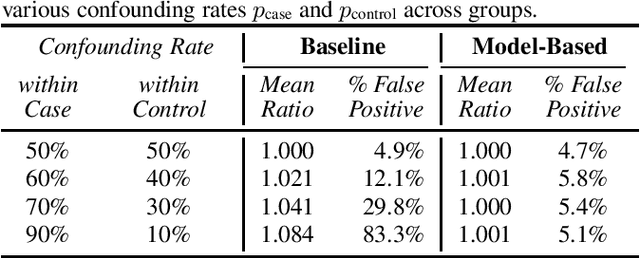
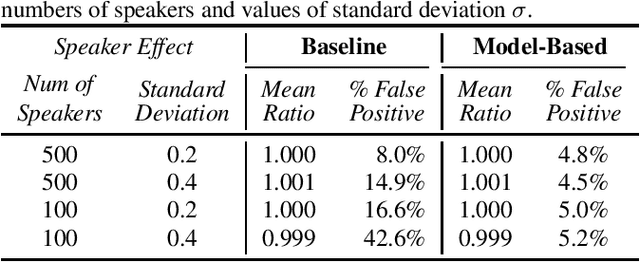
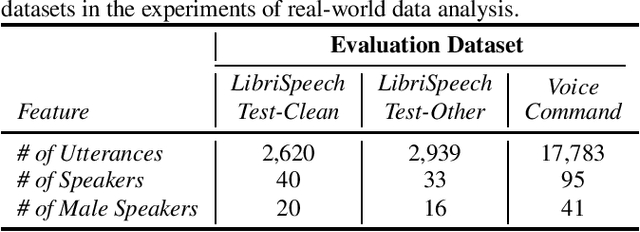
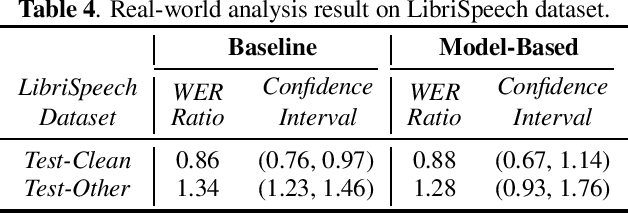
The issue of fairness arises when the automatic speech recognition (ASR) systems do not perform equally well for all subgroups of the population. In any fairness measurement studies for ASR, the open questions of how to control the nuisance factors, how to handle unobserved heterogeneity across speakers, and how to trace the source of any word error rate (WER) gap among different subgroups are especially important - if not appropriately accounted for, incorrect conclusions will be drawn. In this paper, we introduce mixed-effects Poisson regression to better measure and interpret any WER difference among subgroups of interest. Particularly, the presented method can effectively address the three problems raised above and is very flexible to use in practical disparity analyses. We demonstrate the validity of proposed model-based approach on both synthetic and real-world speech data.