 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Approach for Measuring the Fairness in ASR
Paper and Code
Sep 19, 2021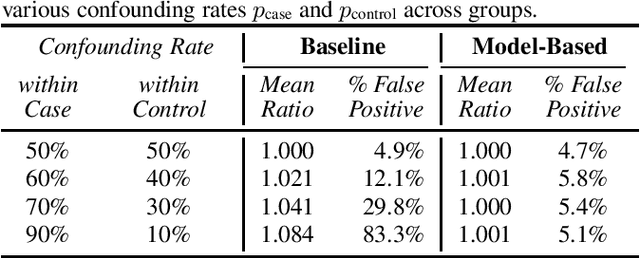
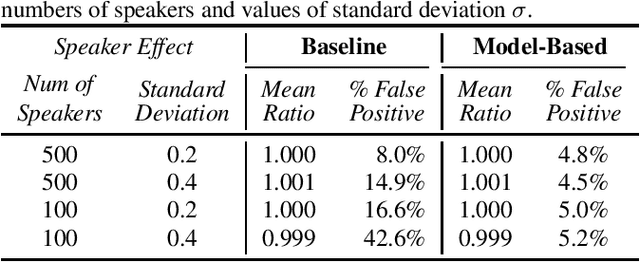
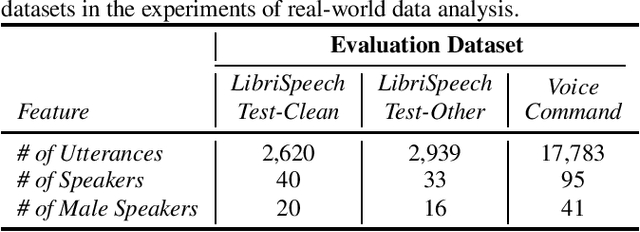
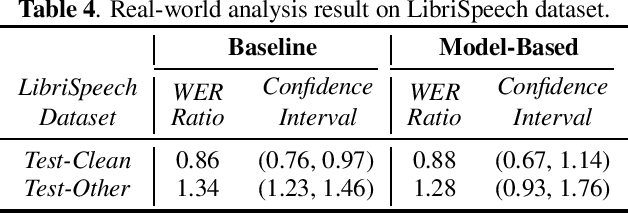
The issue of fairness arises when the automatic speech recognition (ASR) systems do not perform equally well for all subgroups of the population. In any fairness measurement studies for ASR, the open questions of how to control the nuisance factors, how to handle unobserved heterogeneity across speakers, and how to trace the source of any word error rate (WER) gap among different subgroups are especially important - if not appropriately accounted for, incorrect conclusions will be drawn. In this paper, we introduce mixed-effects Poisson regression to better measure and interpret any WER difference among subgroups of interest. Particularly, the presented method can effectively address the three problems raised above and is very flexible to use in practical disparity analyses. We demonstrate the validity of proposed model-based approach on both synthetic and real-world speech data.