 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
A Non-autoregressive Model for Joint STT and TTS
Jan 15, 2025In this paper, we take a step towards jointly modeling automatic speech recognition (STT) and speech synthesis (TTS) in a fully non-autoregressive way. We develop a novel multimodal framework capable of handling the speech and text modalities as input either individually or together. The proposed model can also be trained with unpaired speech or text data owing to its multimodal nature. We further propose an iterative refinement strategy to improve the STT and TTS performance of our model such that the partial hypothesis at the output can be fed back to the input of our model, thus iteratively improving both STT and TTS predictions. We show that our joint model can effectively perform both STT and TTS tasks, outperforming the STT-specific baseline in all tasks and performing competitively with the TTS-specific baseline across a wide range of evaluation metrics.
Improving Transducer-Based Spoken Language Understanding with Self-Conditioned CTC and Knowledge Transfer
Jan 03, 2025In this paper, we propose to improve end-to-end (E2E) spoken language understand (SLU) in an RNN transducer model (RNN-T) by incorporating a joint self-conditioned CTC automatic speech recognition (ASR) objective. Our proposed model is akin to an E2E differentiable cascaded model which performs ASR and SLU sequentially and we ensure that the SLU task is conditioned on the ASR task by having CTC self conditioning. This novel joint modeling of ASR and SLU improves SLU performance significantly over just using SLU optimization. We further improve the performance by aligning the acoustic embeddings of this model with the semantically richer BERT model. Our proposed knowledge transfer strategy makes use of a bag-of-entity prediction layer on the aligned embeddings and the output of this is used to condition the RNN-T based SLU decoding. These techniques show significant improvement over several strong baselines and can perform at par with large models like Whisper with significantly fewer parameters.
End-to-End real time tracking of children's reading with pointer network
Oct 17, 2023In this work, we explore how a real time reading tracker can be built efficiently for children's voices. While previously proposed reading trackers focused on ASR-based cascaded approaches, we propose a fully end-to-end model making it less prone to lags in voice tracking. We employ a pointer network that directly learns to predict positions in the ground truth text conditioned on the streaming speech. To train this pointer network, we generate ground truth training signals by using forced alignment between the read speech and the text being read on the training set. Exploring different forced alignment models, we find a neural attention based model is at least as close in alignment accuracy to the Montreal Forced Aligner, but surprisingly is a better training signal for the pointer network. Our results are reported on one adult speech data (TIMIT) and two children's speech datasets (CMU Kids and Reading Races). Our best model can accurately track adult speech with 87.8% accuracy and the much harder and disfluent children's speech with 77.1% accuracy on CMU Kids data and a 65.3% accuracy on the Reading Races dataset.
Tokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems
Apr 11, 2022


Recent advances in End-to-End (E2E) Spoken Language Understanding (SLU) have been primarily due to effective pretraining of speech representations. One such pretraining paradigm is the distillation of semantic knowledge from state-of-the-art text-based models like BERT to speech encoder neural networks. This work is a step towards doing the same in a much more efficient and fine-grained manner where we align speech embeddings and BERT embeddings on a token-by-token basis. We introduce a simple yet novel technique that uses a cross-modal attention mechanism to extract token-level contextual embeddings from a speech encoder such that these can be directly compared and aligned with BERT based contextual embeddings. This alignment is performed using a novel tokenwise contrastive loss. Fine-tuning such a pretrained model to perform intent recognition using speech directly yields state-of-the-art performance on two widely used SLU datasets. Our model improves further when fine-tuned with additional regularization using SpecAugment especially when speech is noisy, giving an absolute improvement as high as 8% over previous results.
Building an ASR Error Robust Spoken Virtual Patient System in a Highly Class-Imbalanced Scenario Without Speech Data
Apr 11, 2022

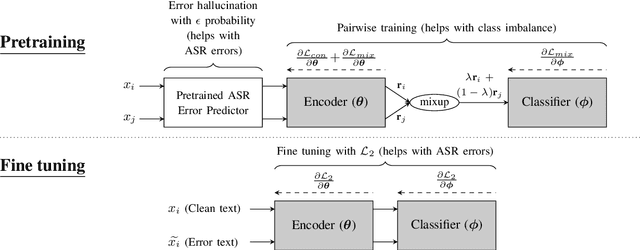

A Virtual Patient (VP) is a powerful tool for training medical students to take patient histories, where responding to a diverse set of spoken questions is essential to simulate natural conversations with a student. The performance of such a Spoken Language Understanding system (SLU) can be adversely affected by both the presence of Automatic Speech Recognition (ASR) errors in the test data and a high degree of class imbalance in the SLU training data. While these two issues have been addressed separately in prior work, we develop a novel two-step training methodology that tackles both these issues effectively in a single dialog agent. As it is difficult to collect spoken data from users without a functioning SLU system, our method does not rely on spoken data for training, rather we use an ASR error predictor to "speechify" the text data. Our method shows significant improvements over strong baselines on the VP intent classification task at various word error rate settings.
Towards End-to-End Integration of Dialog History for Improved Spoken Language Understanding
Apr 11, 2022


Dialog history plays an important role in spoken language understanding (SLU) performance in a dialog system. For end-to-end (E2E) SLU, previous work has used dialog history in text form, which makes the model dependent on a cascaded automatic speech recognizer (ASR). This rescinds the benefits of an E2E system which is intended to be compact and robust to ASR errors. In this paper, we propose a hierarchical conversation model that is capable of directly using dialog history in speech form, making it fully E2E. We also distill semantic knowledge from the available gold conversation transcripts by jointly training a similar text-based conversation model with an explicit tying of acoustic and semantic embeddings. We also propose a novel technique that we call DropFrame to deal with the long training time incurred by adding dialog history in an E2E manner. On the HarperValleyBank dialog dataset, our E2E history integration outperforms a history independent baseline by 7.7% absolute F1 score on the task of dialog action recognition. Our model performs competitively with the state-of-the-art history based cascaded baseline, but uses 48% fewer parameters. In the absence of gold transcripts to fine-tune an ASR model, our model outperforms this baseline by a significant margin of 10% absolute F1 score.
Hallucination of speech recognition errors with sequence to sequence learning
Mar 31, 2021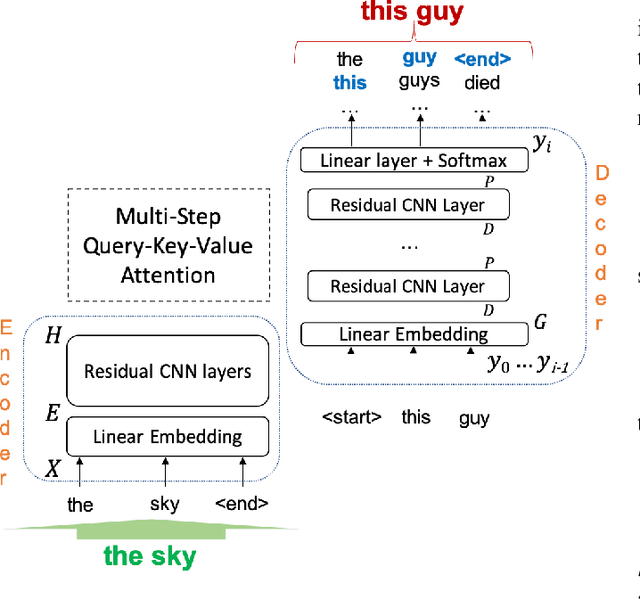
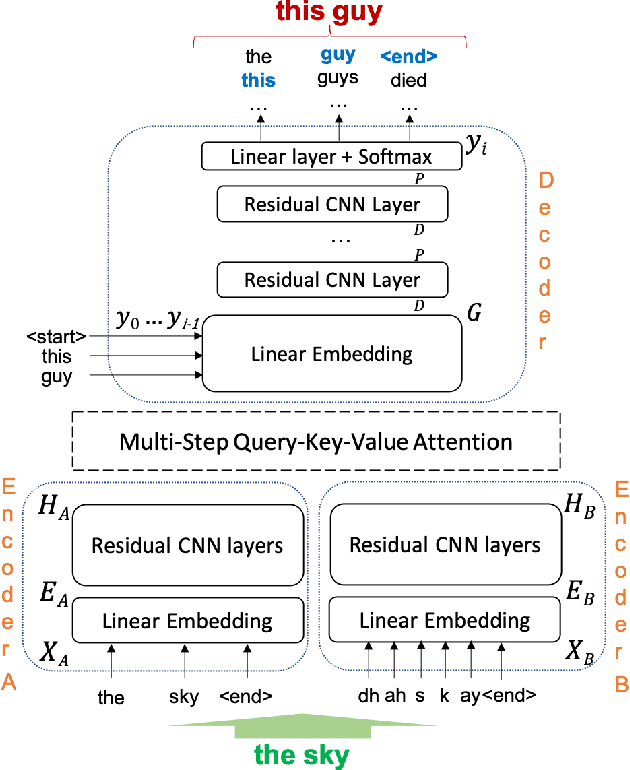
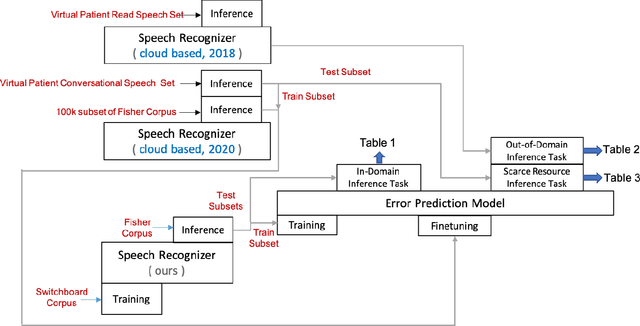
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system's transcription of unseen data, as well as an out-of-domain ASR system's transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.
Handling Class Imbalance in Low-Resource Dialogue Systems by Combining Few-Shot Classification and Interpolation
Oct 28, 2020
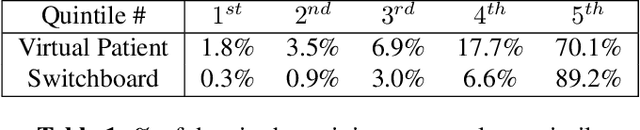

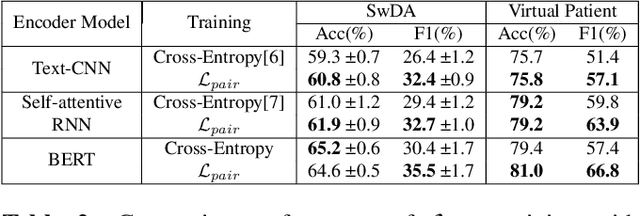
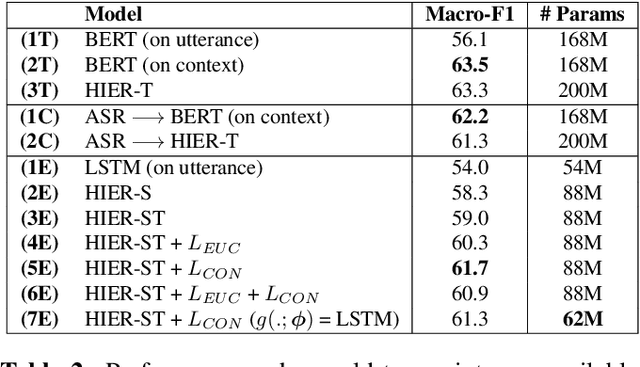
Utterance classification performance in low-resource dialogue systems is constrained by an inevitably high degree of data imbalance in class labels. We present a new end-to-end pairwise learning framework that is designed specifically to tackle this phenomenon by inducing a few-shot classification capability in the utterance representations and augmenting data through an interpolation of utterance representations. Our approach is a general purpose training methodology, agnostic to the neural architecture used for encoding utterances. We show significant improvements in macro-F1 score over standard cross-entropy training for three different neural architectures, demonstrating improvements on a Virtual Patient dialogue dataset as well as a low-resourced emulation of the Switchboard dialogue act classification dataset.
One-shot Information Extraction from Document Images using Neuro-Deductive Program Synthesis
Jun 06, 2019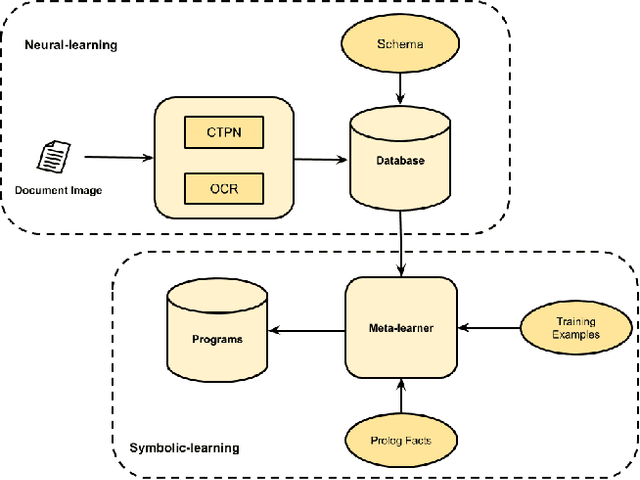


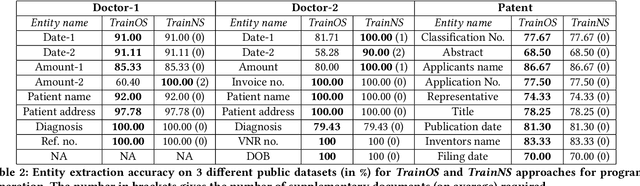
Our interest in this paper is in meeting a rapidly growing industrial demand for information extraction from images of documents such as invoices, bills, receipts etc. In practice users are able to provide a very small number of example images labeled with the information that needs to be extracted. We adopt a novel two-level neuro-deductive, approach where (a) we use pre-trained deep neural networks to populate a relational database with facts about each document-image; and (b) we use a form of deductive reasoning, related to meta-interpretive learning of transition systems to learn extraction programs: Given task-specific transitions defined using the entities and relations identified by the neural detectors and a small number of instances (usually 1, sometimes 2) of images and the desired outputs, a resource-bounded meta-interpreter constructs proofs for the instance(s) via logical deduction; a set of logic programs that extract each desired entity is easily synthesized from such proofs. In most cases a single training example together with a noisy-clone of itself suffices to learn a program-set that generalizes well on test documents, at which time the value of each entity is determined by a majority vote across its program-set. We demonstrate our two-level neuro-deductive approach on publicly available datasets ("Patent" and "Doctor's Bills") and also describe its use in a real-life industrial problem.