 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Class Imbalance in Low-Resource Dialogue Systems by Combining Few-Shot Classification and Interpolation
Paper and Code

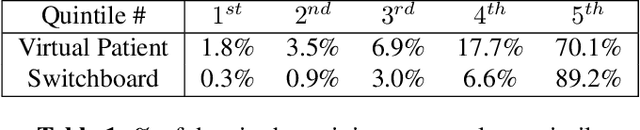

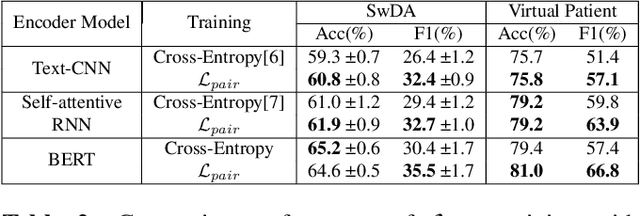
Utterance classification performance in low-resource dialogue systems is constrained by an inevitably high degree of data imbalance in class labels. We present a new end-to-end pairwise learning framework that is designed specifically to tackle this phenomenon by inducing a few-shot classification capability in the utterance representations and augmenting data through an interpolation of utterance representations. Our approach is a general purpose training methodology, agnostic to the neural architecture used for encoding utterances. We show significant improvements in macro-F1 score over standard cross-entropy training for three different neural architectures, demonstrating improvements on a Virtual Patient dialogue dataset as well as a low-resourced emulation of the Switchboard dialogue act classification dataset.