 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Jan 06, 2020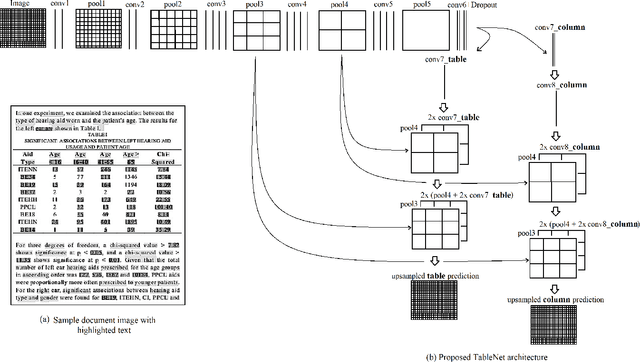

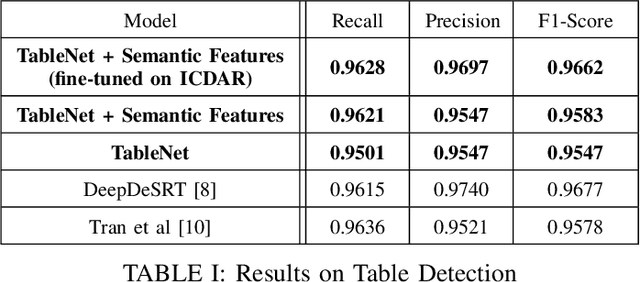
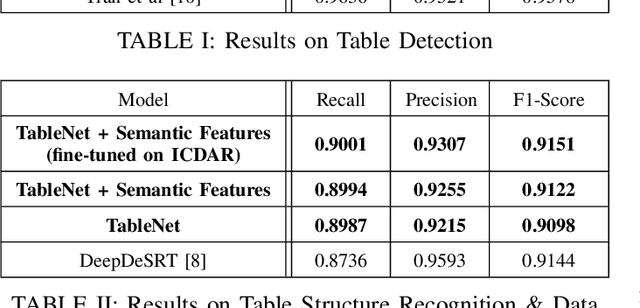
With the widespread use of mobile phones and scanners to photograph and upload documents, the need for extracting the information trapped in unstructured document images such as retail receipts, insurance claim forms and financial invoices is becoming more acute. A major hurdle to this objective is that these images often contain information in the form of tables and extracting data from tabular sub-images presents a unique set of challenges. This includes accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table. While some progress has been made in table detection, extracting the table contents is still a challenge since this involves more fine grained table structure(rows & columns) recognition. Prior approaches have attempted to solve the table detection and structure recognition problems independently using two separate models. In this paper, we propose TableNet: a novel end-to-end deep learning model for both table detection and structure recognition. The model exploits the interdependence between the twin tasks of table detection and table structure recognition to segment out the table and column regions. This is followed by semantic rule-based row extraction from the identified tabular sub-regions. The proposed model and extraction approach was evaluated on the publicly available ICDAR 2013 and Marmot Table datasets obtaining state of the art results. Additionally, we demonstrate that feeding additional semantic features further improves model performance and that the model exhibits transfer learning across datasets. Another contribution of this paper is to provide additional table structure annotations for the Marmot data, which currently only has annotations for table detection.
One-shot Information Extraction from Document Images using Neuro-Deductive Program Synthesis
Jun 06, 2019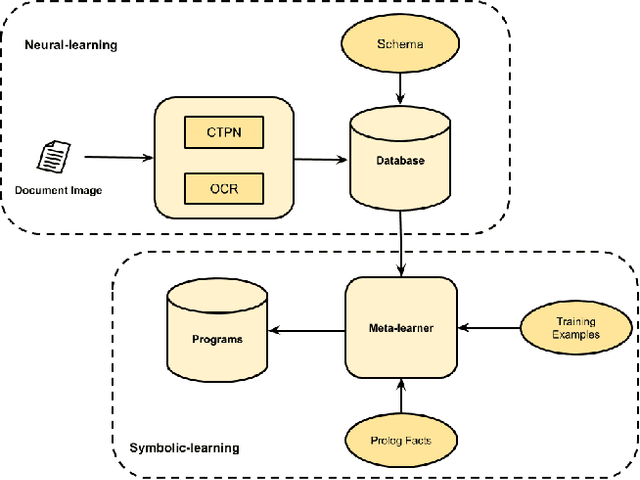


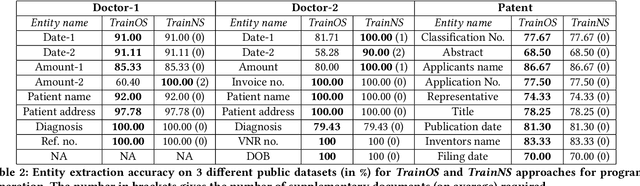
Our interest in this paper is in meeting a rapidly growing industrial demand for information extraction from images of documents such as invoices, bills, receipts etc. In practice users are able to provide a very small number of example images labeled with the information that needs to be extracted. We adopt a novel two-level neuro-deductive, approach where (a) we use pre-trained deep neural networks to populate a relational database with facts about each document-image; and (b) we use a form of deductive reasoning, related to meta-interpretive learning of transition systems to learn extraction programs: Given task-specific transitions defined using the entities and relations identified by the neural detectors and a small number of instances (usually 1, sometimes 2) of images and the desired outputs, a resource-bounded meta-interpreter constructs proofs for the instance(s) via logical deduction; a set of logic programs that extract each desired entity is easily synthesized from such proofs. In most cases a single training example together with a noisy-clone of itself suffices to learn a program-set that generalizes well on test documents, at which time the value of each entity is determined by a majority vote across its program-set. We demonstrate our two-level neuro-deductive approach on publicly available datasets ("Patent" and "Doctor's Bills") and also describe its use in a real-life industrial problem.
Automatic Information Extraction from Piping and Instrumentation Diagrams
Jan 28, 2019

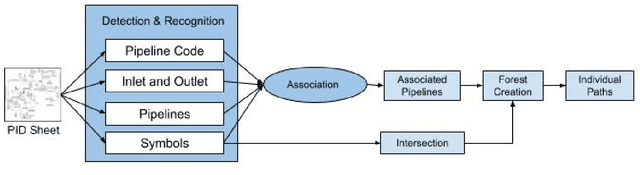
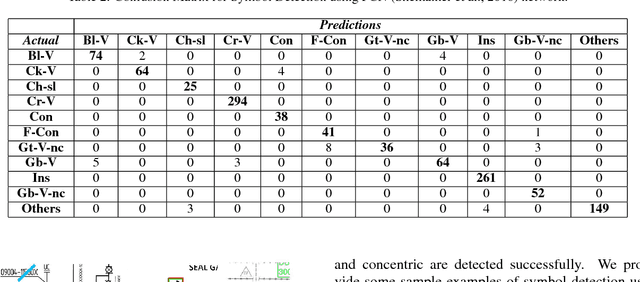
One of the most common modes of representing engineering schematics are Piping and Instrumentation diagrams (P&IDs) that describe the layout of an engineering process flow along with the interconnected process equipment. Over the years, P&ID diagrams have been manually generated, scanned and stored as image files. These files need to be digitized for purposes of inventory management and updation, and easy reference to different components of the schematics. There are several challenging vision problems associated with digitizing real world P&ID diagrams. Real world P&IDs come in several different resolutions, and often contain noisy textual information. Extraction of instrumentation information from these diagrams involves accurate detection of symbols that frequently have minute visual differences between them. Identification of pipelines that may converge and diverge at different points in the image is a further cause for concern. Due to these reasons, to the best of our knowledge, no system has been proposed for end-to-end data extraction from P&ID diagrams. However, with the advent of deep learning and the spectacular successes it has achieved in vision, we hypothesized that it is now possible to re-examine this problem armed with the latest deep learning models. To that end, we present a novel pipeline for information extraction from P&ID sheets via a combination of traditional vision techniques and state-of-the-art deep learning models to identify and isolate pipeline codes, pipelines, inlets and outlets, and for detecting symbols. This is followed by association of the detected components with the appropriate pipeline. The extracted pipeline information is used to populate a tree-like data-structure for capturing the structure of the piping schematics. We evaluated proposed method on a real world dataset of P&ID sheets obtained from an oil firm and have obtained promising results.
Deep Reader: Information extraction from Document images via relation extraction and Natural Language
Dec 14, 2018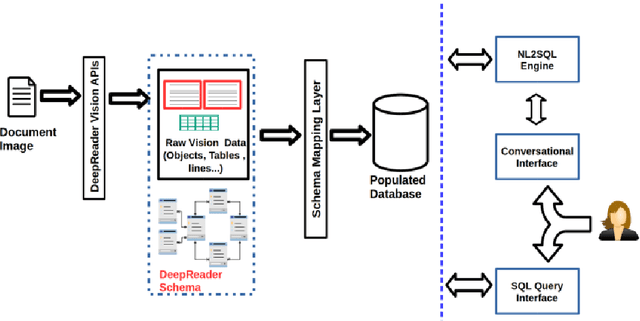
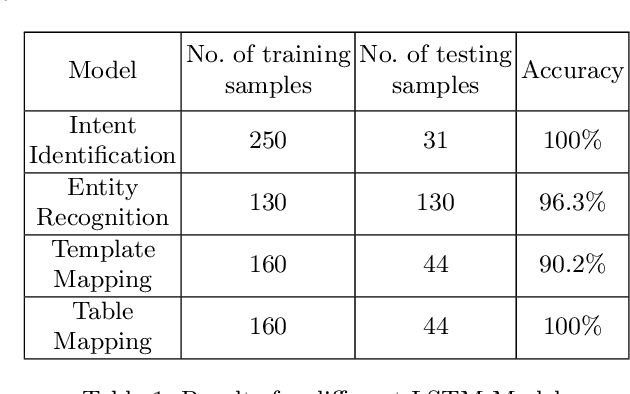
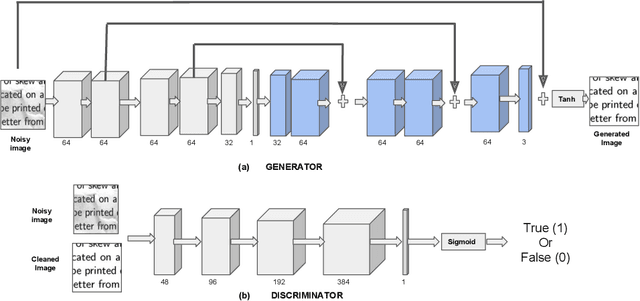

Recent advancements in the area of Computer Vision with state-of-art Neural Networks has given a boost to Optical Character Recognition (OCR) accuracies. However, extracting characters/text alone is often insufficient for relevant information extraction as documents also have a visual structure that is not captured by OCR. Extracting information from tables, charts, footnotes, boxes, headings and retrieving the corresponding structured representation for the document remains a challenge and finds application in a large number of real-world use cases. In this paper, we propose a novel enterprise based end-to-end framework called DeepReader which facilitates information extraction from document images via identification of visual entities and populating a meta relational model across different entities in the document image. The model schema allows for an easy to understand abstraction of the entities detected by the deep vision models and the relationships between them. DeepReader has a suite of state-of-the-art vision algorithms which are applied to recognize handwritten and printed text, eliminate noisy effects, identify the type of documents and detect visual entities like tables, lines and boxes. Deep Reader maps the extracted entities into a rich relational schema so as to capture all the relevant relationships between entities (words, textboxes, lines etc) detected in the document. Relevant information and fields can then be extracted from the document by writing SQL queries on top of the relationship tables. A natural language based interface is added on top of the relationship schema so that a non-technical user, specifying the queries in natural language, can fetch the information with minimal effort. In this paper, we also demonstrate many different capabilities of Deep Reader and report results on a real-world use case.
Reading Industrial Inspection Sheets by Inferring Visual Relations
Dec 11, 2018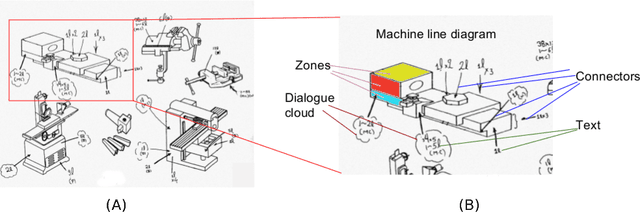
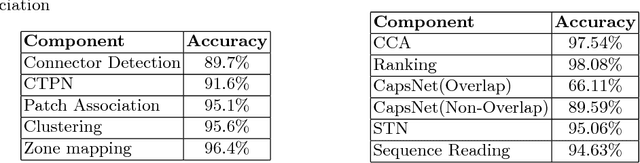
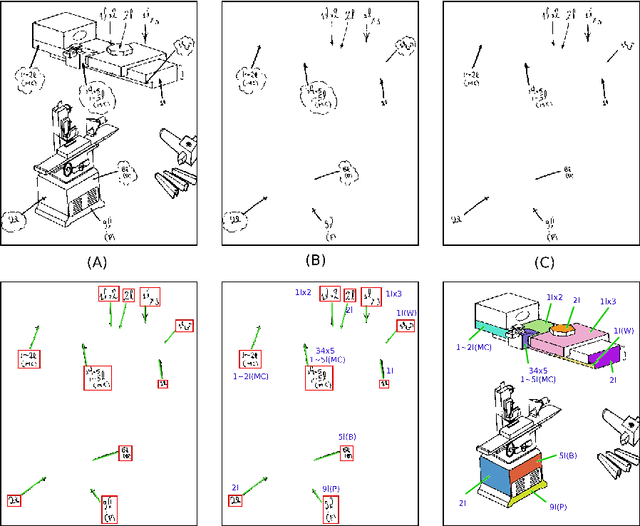

The traditional mode of recording faults in heavy factory equipment has been via hand marked inspection sheets, wherein a machine engineer manually marks the faulty machine regions on a paper outline of the machine. Over the years, millions of such inspection sheets have been recorded and the data within these sheets has remained inaccessible. However, with industries going digital and waking up to the potential value of fault data for machine health monitoring, there is an increased impetus towards digitization of these hand marked inspection records. To target this digitization, we propose a novel visual pipeline combining state of the art deep learning models, with domain knowledge and low level vision techniques, followed by inference of visual relationships. Our framework is robust to the presence of both static and non-static background in the document, variability in the machine template diagrams, unstructured shape of graphical objects to be identified and variability in the strokes of handwritten text. The proposed pipeline incorporates a capsule and spatial transformer network based classifier for accurate text reading, and a customized CTPN network for text detection in addition to hybrid techniques for arrow detection and dialogue cloud removal. We have tested our approach on a real world dataset of 50 inspection sheets for large containers and boilers. The results are visually appealing and the pipeline achieved an accuracy of 87.1% for text detection and 94.6% for text reading.