 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Paper and Code
Jan 06, 2020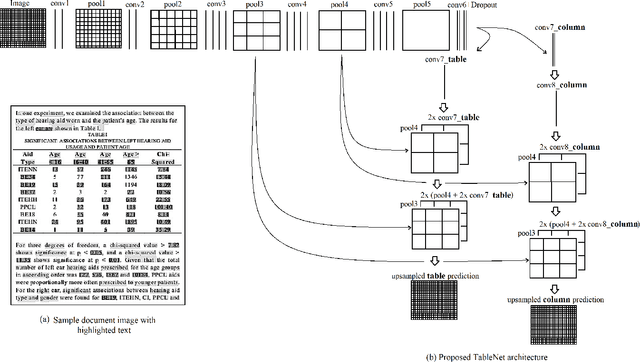

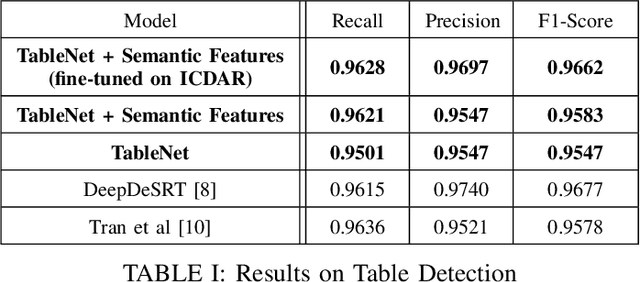
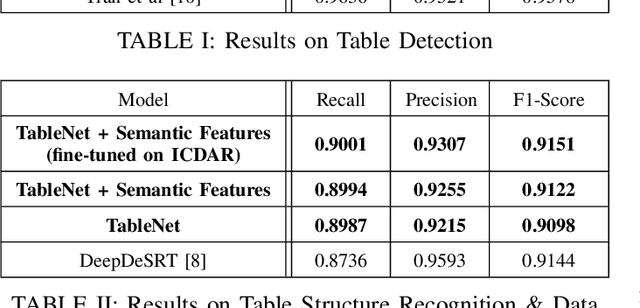
With the widespread use of mobile phones and scanners to photograph and upload documents, the need for extracting the information trapped in unstructured document images such as retail receipts, insurance claim forms and financial invoices is becoming more acute. A major hurdle to this objective is that these images often contain information in the form of tables and extracting data from tabular sub-images presents a unique set of challenges. This includes accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table. While some progress has been made in table detection, extracting the table contents is still a challenge since this involves more fine grained table structure(rows & columns) recognition. Prior approaches have attempted to solve the table detection and structure recognition problems independently using two separate models. In this paper, we propose TableNet: a novel end-to-end deep learning model for both table detection and structure recognition. The model exploits the interdependence between the twin tasks of table detection and table structure recognition to segment out the table and column regions. This is followed by semantic rule-based row extraction from the identified tabular sub-regions. The proposed model and extraction approach was evaluated on the publicly available ICDAR 2013 and Marmot Table datasets obtaining state of the art results. Additionally, we demonstrate that feeding additional semantic features further improves model performance and that the model exhibits transfer learning across datasets. Another contribution of this paper is to provide additional table structure annotations for the Marmot data, which currently only has annotations for table detection.