 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination of speech recognition errors with sequence to sequence learning
Paper and Code
Mar 31, 2021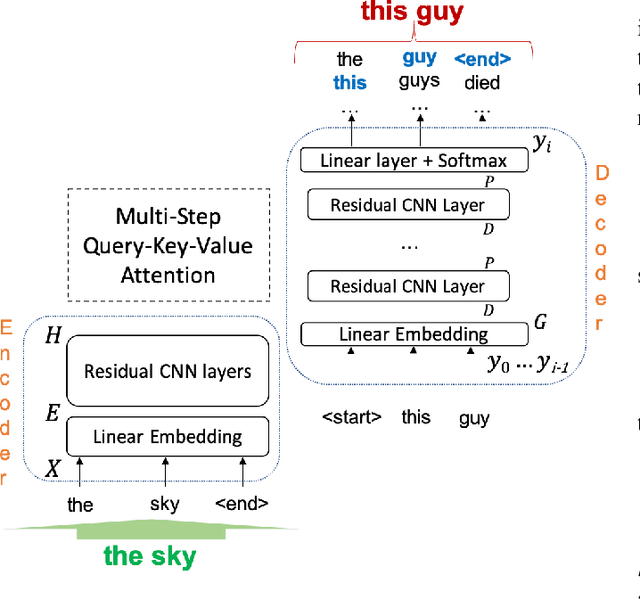
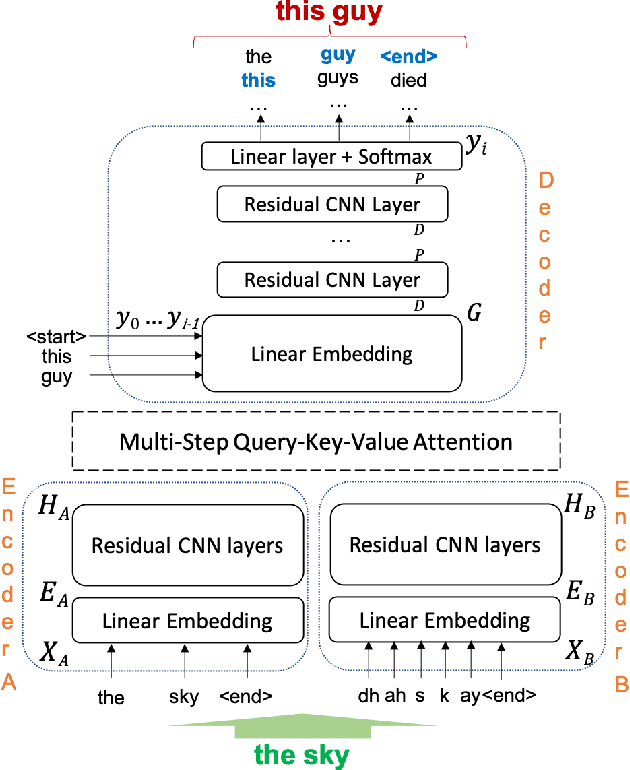
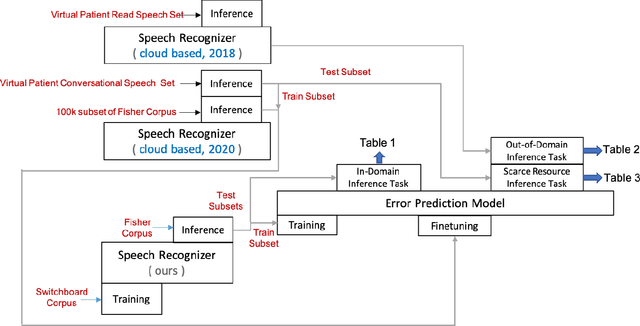
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system's transcription of unseen data, as well as an out-of-domain ASR system's transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.