 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Improving Resource-Efficient Speech Enhancement via Neural Differentiable DSP Vocoder Refinement
Aug 20, 2025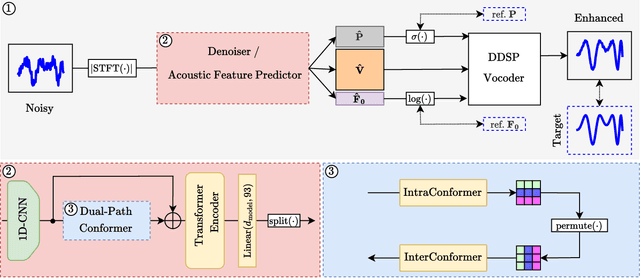
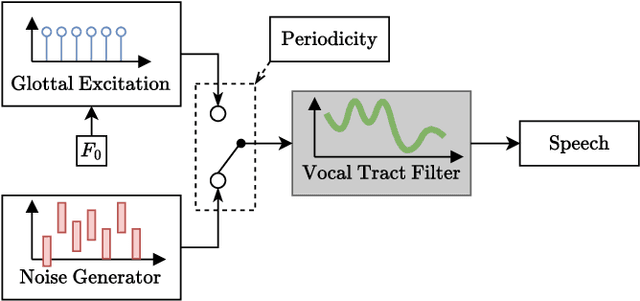
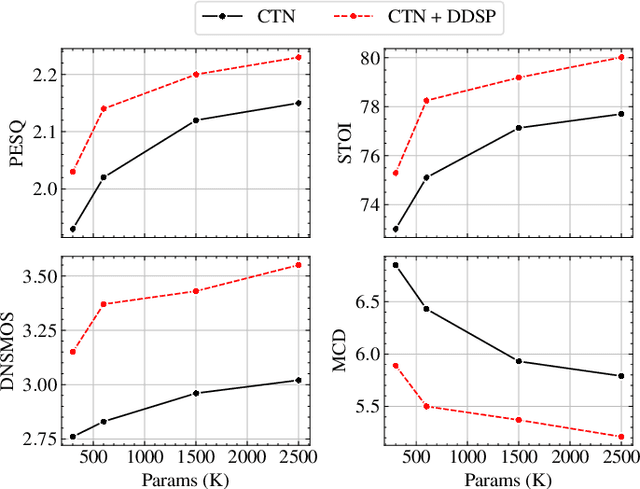
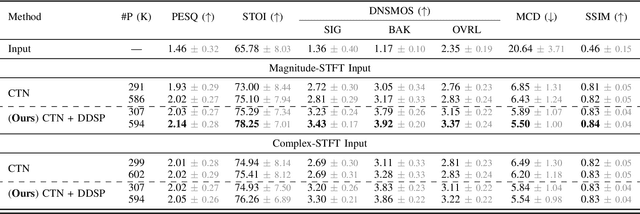
Deploying speech enhancement (SE) systems in wearable devices, such as smart glasses, is challenging due to the limited computational resources on the device. Although deep learning methods have achieved high-quality results, their computational cost limits their feasibility on embedded platforms. This work presents an efficient end-to-end SE framework that leverages a Differentiable Digital Signal Processing (DDSP) vocoder for high-quality speech synthesis. First, a compact neural network predicts enhanced acoustic features from noisy speech: spectral envelope, fundamental frequency (F0), and periodicity. These features are fed into the DDSP vocoder to synthesize the enhanced waveform. The system is trained end-to-end with STFT and adversarial losses, enabling direct optimization at the feature and waveform levels. Experimental results show that our method improves intelligibility and quality by 4% (STOI) and 19% (DNSMOS) over strong baselines without significantly increasing computation, making it well-suited for real-time applications.
Ultra-lightweight Neural Differential DSP Vocoder For High Quality Speech Synthesis
Jan 19, 2024



Neural vocoders model the raw audio waveform and synthesize high-quality audio, but even the highly efficient ones, like MB-MelGAN and LPCNet, fail to run real-time on a low-end device like a smartglass. A pure digital signal processing (DSP) based vocoder can be implemented via lightweight fast Fourier transforms (FFT), and therefore, is a magnitude faster than any neural vocoder. A DSP vocoder often gets a lower audio quality due to consuming over-smoothed acoustic model predictions of approximate representations for the vocal tract. In this paper, we propose an ultra-lightweight differential DSP (DDSP) vocoder that uses a jointly optimized acoustic model with a DSP vocoder, and learns without an extracted spectral feature for the vocal tract. The model achieves audio quality comparable to neural vocoders with a high average MOS of 4.36 while being efficient as a DSP vocoder. Our C++ implementation, without any hardware-specific optimization, is at 15 MFLOPS, surpasses MB-MelGAN by 340 times in terms of FLOPS, and achieves a vocoder-only RTF of 0.003 and overall RTF of 0.044 while running single-threaded on a 2GHz Intel Xeon CPU.
Towards zero-shot Text-based voice editing using acoustic context conditioning, utterance embeddings, and reference encoders
Oct 28, 2022



Text-based voice editing (TBVE) uses synthetic output from text-to-speech (TTS) systems to replace words in an original recording. Recent work has used neural models to produce edited speech that is similar to the original speech in terms of clarity, speaker identity, and prosody. However, one limitation of prior work is the usage of finetuning to optimise performance: this requires further model training on data from the target speaker, which is a costly process that may incorporate potentially sensitive data into server-side models. In contrast, this work focuses on the zero-shot approach which avoids finetuning altogether, and instead uses pretrained speaker verification embeddings together with a jointly trained reference encoder to encode utterance-level information that helps capture aspects such as speaker identity and prosody. Subjective listening tests find that both utterance embeddings and a reference encoder improve the continuity of speaker identity and prosody between the edited synthetic speech and unedited original recording in the zero-shot setting.