 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards zero-shot Text-based voice editing using acoustic context conditioning, utterance embeddings, and reference encoders
Oct 28, 2022



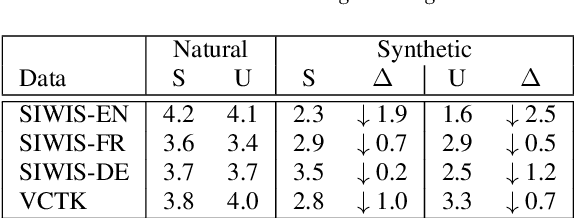
Text-based voice editing (TBVE) uses synthetic output from text-to-speech (TTS) systems to replace words in an original recording. Recent work has used neural models to produce edited speech that is similar to the original speech in terms of clarity, speaker identity, and prosody. However, one limitation of prior work is the usage of finetuning to optimise performance: this requires further model training on data from the target speaker, which is a costly process that may incorporate potentially sensitive data into server-side models. In contrast, this work focuses on the zero-shot approach which avoids finetuning altogether, and instead uses pretrained speaker verification embeddings together with a jointly trained reference encoder to encode utterance-level information that helps capture aspects such as speaker identity and prosody. Subjective listening tests find that both utterance embeddings and a reference encoder improve the continuity of speaker identity and prosody between the edited synthetic speech and unedited original recording in the zero-shot setting.
Exploring Disentanglement with Multilingual and Monolingual VQ-VAE
May 04, 2021


This work examines the content and usefulness of disentangled phone and speaker representations from two separately trained VQ-VAE systems: one trained on multilingual data and another trained on monolingual data. We explore the multi- and monolingual models using four small proof-of-concept tasks: copy-synthesis, voice transformation, linguistic code-switching, and content-based privacy masking. From these tasks, we reflect on how disentangled phone and speaker representations can be used to manipulate speech in a meaningful way. Our experiments demonstrate that the VQ representations are suitable for these tasks, including creating new voices by mixing speaker representations together. We also present our novel technique to conceal the content of targeted words within an utterance by manipulating phone VQ codes, while retaining speaker identity and intelligibility of surrounding words. Finally, we discuss recommendations for further increasing the viability of disentangled representations.