 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapQA: A Dataset for Question Answering on Choropleth Maps
Nov 15, 2022Choropleth maps are a common visual representation for region-specific tabular data and are used in a number of different venues (newspapers, articles, etc). These maps are human-readable but are often challenging to deal with when trying to extract data for screen readers, analyses, or other related tasks. Recent research into Visual-Question Answering (VQA) has studied question answering on human-generated charts (ChartQA), such as bar, line, and pie charts. However, little work has paid attention to understanding maps; general VQA models, and ChartQA models, suffer when asked to perform this task. To facilitate and encourage research in this area, we present MapQA, a large-scale dataset of ~800K question-answer pairs over ~60K map images. Our task tests various levels of map understanding, from surface questions about map styles to complex questions that require reasoning on the underlying data. We present the unique challenges of MapQA that frustrate most strong baseline algorithms designed for ChartQA and general VQA tasks. We also present a novel algorithm, Visual Multi-Output Data Extraction based QA (V-MODEQA) for MapQA. V-MODEQA extracts the underlying structured data from a map image with a multi-output model and then performs reasoning on the extracted data. Our experimental results show that V-MODEQA has better overall performance and robustness on MapQA than the state-of-the-art ChartQA and VQA algorithms by capturing the unique properties in map question answering.
Identifying High Accuracy Regions in Traffic Camera Images to Enhance the Estimation of Road Traffic Metrics: A Quadtree Based Method
Jun 29, 2021
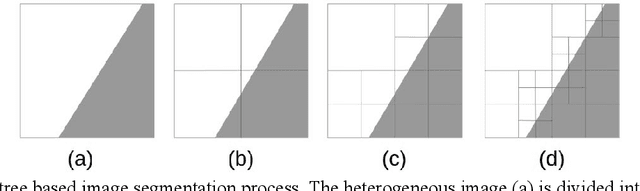


The growing number of real-time camera feeds in urban areas has made it possible to provide high-quality traffic data for effective transportation planning, operations, and management. However, deriving reliable traffic metrics from these camera feeds has been a challenge due to the limitations of current vehicle detection techniques, as well as the various camera conditions such as height and resolution. In this work, a quadtree based algorithm is developed to continuously partition the image extent until only regions with high detection accuracy are remained. These regions are referred to as the high-accuracy identification regions (HAIR) in this paper. We demonstrate how the use of the HAIR can improve the accuracy of traffic density estimates using images from traffic cameras at different heights and resolutions in Central Ohio. Our experiments show that the proposed algorithm can be used to derive robust HAIR where vehicle detection accuracy is 41 percent higher than that in the original image extent. The use of the HAIR also significantly improves the traffic density estimation with an overall decrease of 49 percent in root mean squared error.