 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAuth - Precise Task-Scoped Authorization For Agents
Mar 17, 2026The emerging agentic web envisions AI agents that reliably fulfill users' natural-language (NL)-based tasks by interacting with existing web services. However, existing authorization models are misaligned with this vision. In particular, today's operator-scoped authorization, exemplified by OAuth, grants broad permissions tied to operators (e.g., the transfer operator) rather than to the specific operations (e.g., transfer $100 to Bob) implied by a user's task. This will inevitably result in overprivileged agents. We introduce Precise Task-Scoped Implicit Authorization (PAuth), a fundamentally different model in which submitting an NL task implicitly authorizes only the concrete operations required for its faithful execution. To make this enforceable at servers, we propose NL slices: symbolic specifications of the calls each service expects, derived from the task and upstream results. Complementing this, we also propose envelopes: special data structure to bind each operand's concrete value to its symbolic provenance, enabling servers to verify that all operands arise from legitimate computations. PAuth is prototyped in the agent-security evaluation framework AgentDojo. We evaluate it in both benign settings and attack scenarios where a spurious operation is injected into an otherwise normal task. In all benign tests, PAuth executes the tasks successfully without requiring any additional permissions. In all attack tests, PAuth correctly raises warnings about missing permissions. These results demonstrate that PAuth's reasoning about permissions is indeed precise. We further analyze the characteristics of these tasks and measure the associated token costs.
Atomicity for Agents: Exposing, Exploiting, and Mitigating TOCTOU Vulnerabilities in Browser-Use Agents
Feb 28, 2026Browser-use agents are widely used for everyday tasks. They enable automated interaction with web pages through structured DOM based interfaces or vision language models operating on page screenshots. However, web pages often change between planning and execution, causing agents to execute actions based on stale assumptions. We view this temporal mismatch as a time of check to time of use (TOCTOU) vulnerability in browser-use agents. Dynamic or adversarial web content can exploit this window to induce unintended actions. We present a large scale empirical study of TOCTOU vulnerabilities in browser-use agents using a benchmark that spans synthesized and real world websites. Using this benchmark, we evaluate 10 popular open source agents and show that TOCTOU vulnerabilities are widespread. We design a lightweight mitigation based on pre-execution validation. It monitors DOM and layout changes during planning and validates the page state immediately before action execution. This approach reduces the risk of insecure execution and mitigates unintended side effects in browser-use agents.
Web Verbs: Typed Abstractions for Reliable Task Composition on the Agentic Web
Feb 19, 2026The Web is evolving from a medium that humans browse to an environment where software agents act on behalf of users. Advances in large language models (LLMs) make natural language a practical interface for goal-directed tasks, yet most current web agents operate on low-level primitives such as clicks and keystrokes. These operations are brittle, inefficient, and difficult to verify. Complementing content-oriented efforts such as NLWeb's semantic layer for retrieval, we argue that the agentic web also requires a semantic layer for web actions. We propose \textbf{Web Verbs}, a web-scale set of typed, semantically documented functions that expose site capabilities through a uniform interface, whether implemented through APIs or robust client-side workflows. These verbs serve as stable and composable units that agents can discover, select, and synthesize into concise programs. This abstraction unifies API-based and browser-based paradigms, enabling LLMs to synthesize reliable and auditable workflows with explicit control and data flow. Verbs can carry preconditions, postconditions, policy tags, and logging support, which improves \textbf{reliability} by providing stable interfaces, \textbf{efficiency} by reducing dozens of steps into a few function calls, and \textbf{verifiability} through typed contracts and checkable traces. We present our vision, a proof-of-concept implementation, and representative case studies that demonstrate concise and robust execution compared to existing agents. Finally, we outline a roadmap for standardization to make verbs deployable and trustworthy at web scale.
RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments
May 28, 2025Computer-use agents (CUAs) promise to automate complex tasks across operating systems (OS) and the web, but remain vulnerable to indirect prompt injection. Current evaluations of this threat either lack support realistic but controlled environments or ignore hybrid web-OS attack scenarios involving both interfaces. To address this, we propose RedTeamCUA, an adversarial testing framework featuring a novel hybrid sandbox that integrates a VM-based OS environment with Docker-based web platforms. Our sandbox supports key features tailored for red teaming, such as flexible adversarial scenario configuration, and a setting that decouples adversarial evaluation from navigational limitations of CUAs by initializing tests directly at the point of an adversarial injection. Using RedTeamCUA, we develop RTC-Bench, a comprehensive benchmark with 864 examples that investigate realistic, hybrid web-OS attack scenarios and fundamental security vulnerabilities. Benchmarking current frontier CUAs identifies significant vulnerabilities: Claude 3.7 Sonnet | CUA demonstrates an ASR of 42.9%, while Operator, the most secure CUA evaluated, still exhibits an ASR of 7.6%. Notably, CUAs often attempt to execute adversarial tasks with an Attempt Rate as high as 92.5%, although failing to complete them due to capability limitations. Nevertheless, we observe concerning ASRs of up to 50% in realistic end-to-end settings, with the recently released frontier Claude 4 Opus | CUA showing an alarming ASR of 48%, demonstrating that indirect prompt injection presents tangible risks for even advanced CUAs despite their capabilities and safeguards. Overall, RedTeamCUA provides an essential framework for advancing realistic, controlled, and systematic analysis of CUA vulnerabilities, highlighting the urgent need for robust defenses to indirect prompt injection prior to real-world deployment.
Imbalanced Gradients: A New Cause of Overestimated Adversarial Robustness
Jun 30, 2020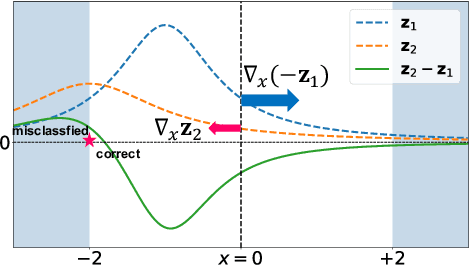
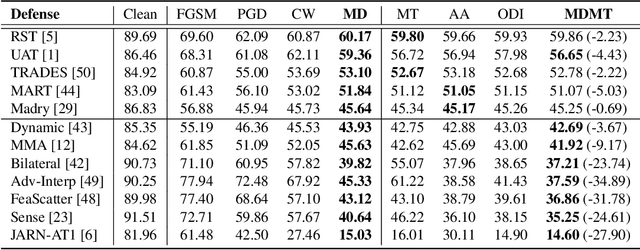
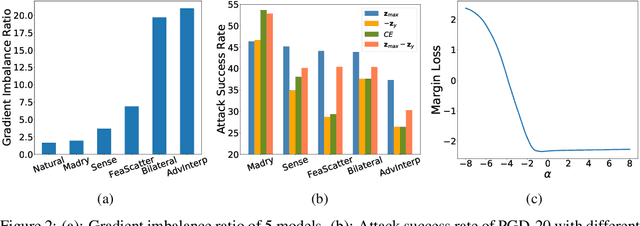
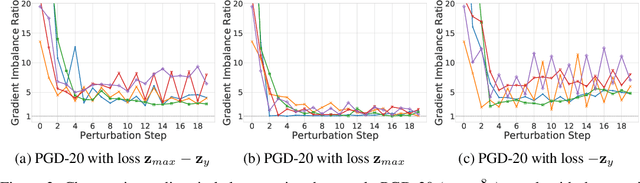
Evaluating the robustness of a defense model is a challenging task in adversarial robustness research. Obfuscated gradients, a type of gradient masking, have previously been found to exist in many defense methods and cause a false signal of robustness. In this paper, we identify a more subtle situation called \emph{Imbalanced Gradients} that can also cause overestimated adversarial robustness. The phenomenon of imbalanced gradients occurs when the gradient of one term of the margin loss dominates and pushes the attack towards to a suboptimal direction. To exploit imbalanced gradients, we formulate a \emph{Margin Decomposition (MD)} attack that decomposes a margin loss into individual terms and then explores the attackability of these terms separately via a two-stage process. We examine 12 state-of-the-art defense models, and find that models exploiting label smoothing easily cause imbalanced gradients, and on which our MD attacks can decrease their PGD robustness (evaluated by PGD attack) by over 23%. For 6 out of the 12 defenses, our attack can reduce their PGD robustness by at least 9%. The results suggest that imbalanced gradients need to be carefully addressed for more reliable adversarial robustness.
Heuristic Black-box Adversarial Attacks on Video Recognition Models
Nov 21, 2019
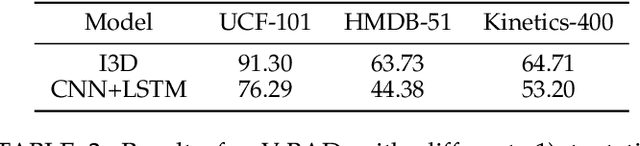


We study the problem of attacking video recognition models in the black-box setting, where the model information is unknown and the adversary can only make queries to detect the predicted top-1 class and its probability. Compared with the black-box attack on images, attacking videos is more challenging as the computation cost for searching the adversarial perturbations on a video is much higher due to its high dimensionality. To overcome this challenge, we propose a heuristic black-box attack model that generates adversarial perturbations only on the selected frames and regions. More specifically, a heuristic-based algorithm is proposed to measure the importance of each frame in the video towards generating the adversarial examples. Based on the frames' importance, the proposed algorithm heuristically searches a subset of frames where the generated adversarial example has strong adversarial attack ability while keeps the perturbations lower than the given bound. Besides, to further boost the attack efficiency, we propose to generate the perturbations only on the salient regions of the selected frames. In this way, the generated perturbations are sparse in both temporal and spatial domains. Experimental results of attacking two mainstream video recognition methods on the UCF-101 dataset and the HMDB-51 dataset demonstrate that the proposed heuristic black-box adversarial attack method can significantly reduce the computation cost and lead to more than 28\% reduction in query numbers for the untargeted attack on both datasets.
Black-box Adversarial Attacks on Video Recognition Models
Apr 10, 2019Deep neural networks (DNNs) are known for their vulnerability to adversarial examples. These are examples that have undergone a small, carefully crafted perturbation, and which can easily fool a DNN into making misclassifications at test time. Thus far, the field of adversarial research has mainly focused on image models, under either a white-box setting, where an adversary has full access to model parameters, or a black-box setting where an adversary can only query the target model for probabilities or labels. Whilst several white-box attacks have been proposed for video models, black-box video attacks are still unexplored. To close this gap, we propose the first black-box video attack framework, called V-BAD. V-BAD is a general framework for adversarial gradient estimation and rectification, based on Natural Evolution Strategies (NES). In particular, V-BAD utilizes \textit{tentative perturbations} transferred from image models, and \textit{partition-based rectifications} found by the NES on partitions (patches) of tentative perturbations, to obtain good adversarial gradient estimates with fewer queries to the target model. V-BAD is equivalent to estimating the projection of an adversarial gradient on a selected subspace. Using three benchmark video datasets, we demonstrate that V-BAD can craft both untargeted and targeted attacks to fool two state-of-the-art deep video recognition models. For the targeted attack, it achieves $>$93\% success rate using only an average of $3.4 \sim 8.4 \times 10^4$ queries, a similar number of queries to state-of-the-art black-box image attacks. This is despite the fact that videos often have two orders of magnitude higher dimensionality than static images. We believe that V-BAD is a promising new tool to evaluate and improve the robustness of video recognition models to black-box adversarial attacks.