 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtter: Generating Tests from Issues to Validate SWE Patches
Feb 07, 2025While there has been plenty of work on generating tests from existing code, there has been limited work on generating tests from issues. A correct test must validate the code patch that resolves the issue. In this work, we focus on the scenario where the code patch does not exist yet. This approach supports two major use-cases. First, it supports TDD (test-driven development), the discipline of "test first, write code later" that has well-documented benefits for human software engineers. Second, it also validates SWE (software engineering) agents, which generate code patches for resolving issues. This paper introduces Otter, an LLM-based solution for generating tests from issues. Otter augments LLMs with rule-based analysis to check and repair their outputs, and introduces a novel self-reflective action planning stage. Experiments show Otter outperforming state-of-the-art systems for generating tests from issues, in addition to enhancing systems that generate patches from issues. We hope that Otter helps make developers more productive at resolving issues and leads to more robust, well-tested code.
TDD-Bench Verified: Can LLMs Generate Tests for Issues Before They Get Resolved?
Dec 03, 2024



Test-driven development (TDD) is the practice of writing tests first and coding later, and the proponents of TDD expound its numerous benefits. For instance, given an issue on a source code repository, tests can clarify the desired behavior among stake-holders before anyone writes code for the agreed-upon fix. Although there has been a lot of work on automated test generation for the practice "write code first, test later", there has been little such automation for TDD. Ideally, tests for TDD should be fail-to-pass (i.e., fail before the issue is resolved and pass after) and have good adequacy with respect to covering the code changed during issue resolution. This paper introduces TDD-Bench Verified, a high-quality benchmark suite of 449 issues mined from real-world GitHub code repositories. The benchmark's evaluation harness runs only relevant tests in isolation for simple yet accurate coverage measurements, and the benchmark's dataset is filtered both by human judges and by execution in the harness. This paper also presents Auto-TDD, an LLM-based solution that takes as input an issue description and a codebase (prior to issue resolution) and returns as output a test that can be used to validate the changes made for resolving the issue. Our evaluation shows that Auto-TDD yields a better fail-to-pass rate than the strongest prior work while also yielding high coverage adequacy. Overall, we hope that this work helps make developers more productive at resolving issues while simultaneously leading to more robust fixes.
Repository-Level Compositional Code Translation and Validation
Oct 31, 2024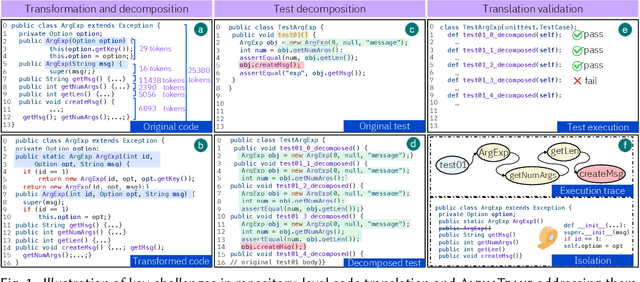
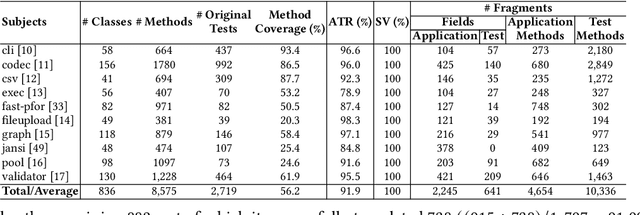
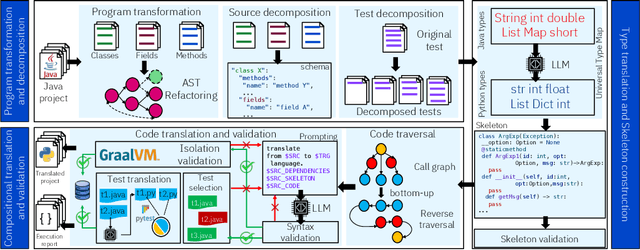
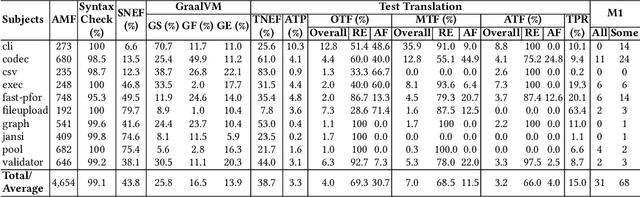
Code translation transforms programs from one programming language (PL) to another. Several rule-based transpilers have been designed to automate code translation between different pairs of PLs. However, the rules can become obsolete as the PLs evolve and cannot generalize to other PLs. Recent studies have explored the automation of code translation using Large Language Models (LLMs). One key observation is that such techniques may work well for crafted benchmarks but fail to generalize to the scale and complexity of real-world projects with dependencies, custom types, PL-specific features, etc. We propose AlphaTrans, a neuro-symbolic approach to automate repository-level code translation. AlphaTrans translates both source and test code, and employs multiple levels of validation to ensure the translation preserves the functionality of the source program. To break down the problem for LLMs, AlphaTrans leverages program analysis to decompose the program into fragments and translates them in the reverse call order. We leveraged AlphaTrans to translate ten real-world open-source projects consisting of <836, 8575, 2719> classes, methods, and tests. AlphaTrans translated the entire repository of these projects consisting of 6899 source code fragments. 99.1% of the translated code fragments are syntactically correct, and AlphaTrans validates the translations' runtime behavior and functional correctness for 25.8%. On average, the integrated translation and validation take 36 hours to translate a project, showing its scalability in practice. For the syntactically or semantically incorrect translations, AlphaTrans generates a report including existing translation, stack trace, test errors, or assertion failures. We provided these artifacts to two developers to fix the translation bugs in four projects. They were able to fix the issues in 20.1 hours on average and achieve all passing tests.
Decomposing a Recurrent Neural Network into Modules for Enabling Reusability and Replacement
Dec 15, 2022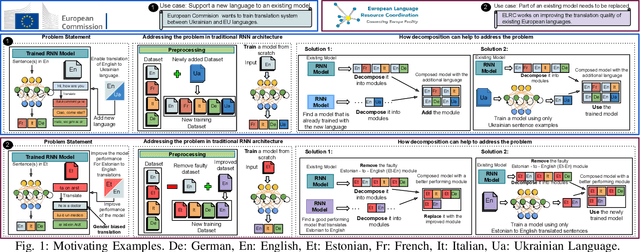
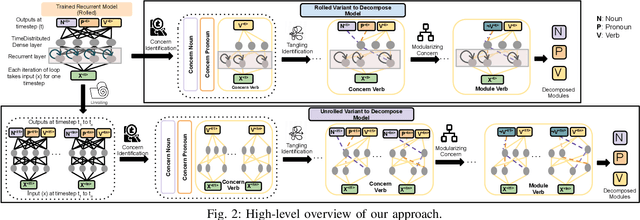

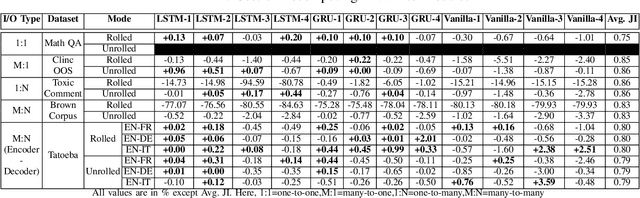
Can we take a recurrent neural network (RNN) trained to translate between languages and augment it to support a new natural language without retraining the model from scratch? Can we fix the faulty behavior of the RNN by replacing portions associated with the faulty behavior? Recent works on decomposing a fully connected neural network (FCNN) and convolutional neural network (CNN) into modules have shown the value of engineering deep models in this manner, which is standard in traditional SE but foreign for deep learning models. However, prior works focus on the image-based multiclass classification problems and cannot be applied to RNN due to (a) different layer structures, (b) loop structures, (c) different types of input-output architectures, and (d) usage of both nonlinear and logistic activation functions. In this work, we propose the first approach to decompose an RNN into modules. We study different types of RNNs, i.e., Vanilla, LSTM, and GRU. Further, we show how such RNN modules can be reused and replaced in various scenarios. We evaluate our approach against 5 canonical datasets (i.e., Math QA, Brown Corpus, Wiki-toxicity, Clinc OOS, and Tatoeba) and 4 model variants for each dataset. We found that decomposing a trained model has a small cost (Accuracy: -0.6%, BLEU score: +0.10%). Also, the decomposed modules can be reused and replaced without needing to retrain.
Manas: Mining Software Repositories to Assist AutoML
Dec 06, 2021
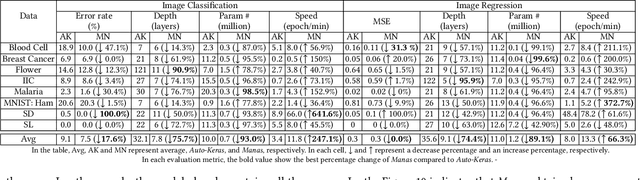
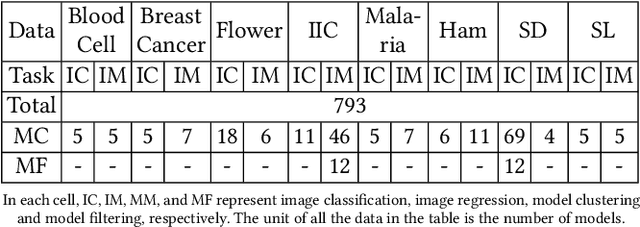
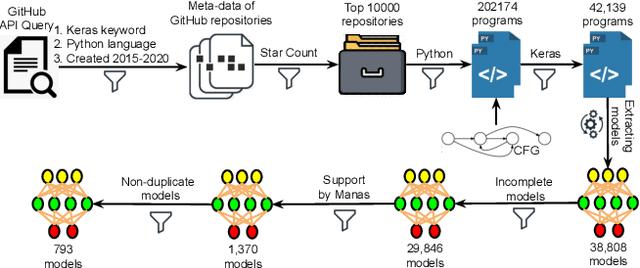
Today deep learning is widely used for building software. A software engineering problem with deep learning is that finding an appropriate convolutional neural network (CNN) model for the task can be a challenge for developers. Recent work on AutoML, more precisely neural architecture search (NAS), embodied by tools like Auto-Keras aims to solve this problem by essentially viewing it as a search problem where the starting point is a default CNN model, and mutation of this CNN model allows exploration of the space of CNN models to find a CNN model that will work best for the problem. These works have had significant success in producing high-accuracy CNN models. There are two problems, however. First, NAS can be very costly, often taking several hours to complete. Second, CNN models produced by NAS can be very complex that makes it harder to understand them and costlier to train them. We propose a novel approach for NAS, where instead of starting from a default CNN model, the initial model is selected from a repository of models extracted from GitHub. The intuition being that developers solving a similar problem may have developed a better starting point compared to the default model. We also analyze common layer patterns of CNN models in the wild to understand changes that the developers make to improve their models. Our approach uses commonly occurring changes as mutation operators in NAS. We have extended Auto-Keras to implement our approach. Our evaluation using 8 top voted problems from Kaggle for tasks including image classification and image regression shows that given the same search time, without loss of accuracy, Manas produces models with 42.9% to 99.6% fewer number of parameters than Auto-Keras' models. Benchmarked on GPU, Manas' models train 30.3% to 641.6% faster than Auto-Keras' models.
Decomposing Convolutional Neural Networks into Reusable and Replaceable Modules
Oct 11, 2021
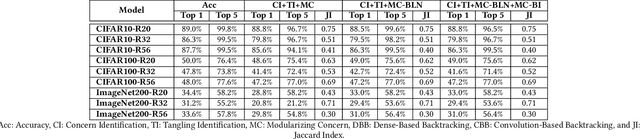
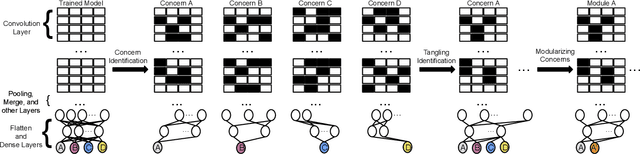
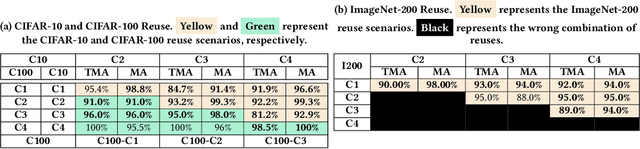
Training from scratch is the most common way to build a Convolutional Neural Network (CNN) based model. What if we can build new CNN models by reusing parts from previously build CNN models? What if we can improve a CNN model by replacing (possibly faulty) parts with other parts? In both cases, instead of training, can we identify the part responsible for each output class (module) in the model(s) and reuse or replace only the desired output classes to build a model? Prior work has proposed decomposing dense-based networks into modules (one for each output class) to enable reusability and replaceability in various scenarios. However, this work is limited to the dense layers and based on the one-to-one relationship between the nodes in consecutive layers. Due to the shared architecture in the CNN model, prior work cannot be adapted directly. In this paper, we propose to decompose a CNN model used for image classification problems into modules for each output class. These modules can further be reused or replaced to build a new model. We have evaluated our approach with CIFAR-10, CIFAR-100, and ImageNet tiny datasets with three variations of ResNet models and found that enabling decomposition comes with a small cost (2.38% and 0.81% for top-1 and top-5 accuracy, respectively). Also, building a model by reusing or replacing modules can be done with a 2.3% and 0.5% average loss of accuracy. Furthermore, reusing and replacing these modules reduces CO2e emission by ~37 times compared to training the model from scratch.
A Comprehensive Study on Deep Learning Bug Characteristics
Jun 03, 2019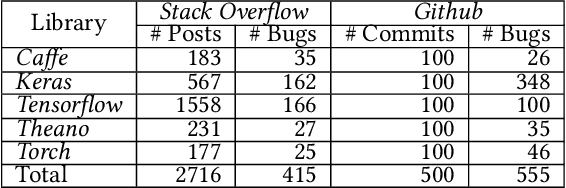
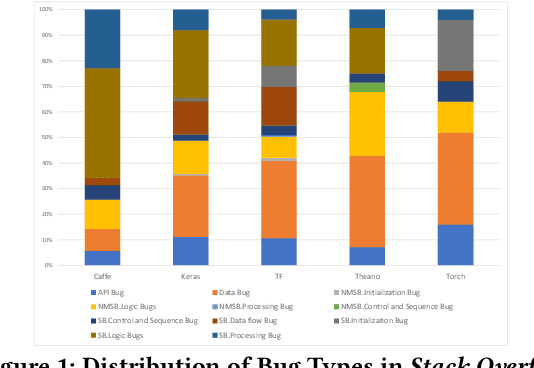
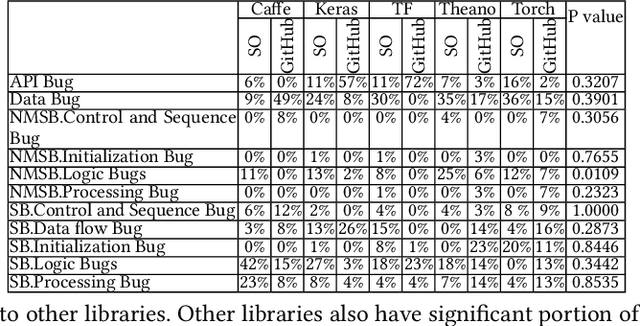
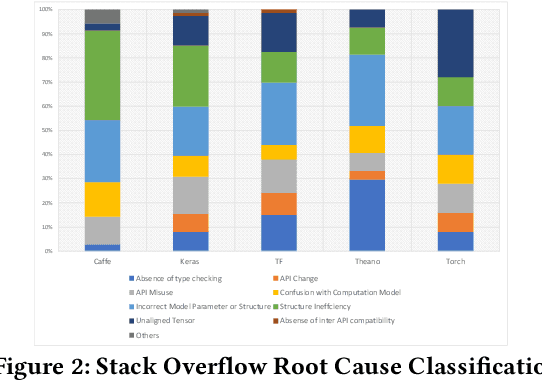
Deep learning has gained substantial popularity in recent years. Developers mainly rely on libraries and tools to add deep learning capabilities to their software. What kinds of bugs are frequently found in such software? What are the root causes of such bugs? What impacts do such bugs have? Which stages of deep learning pipeline are more bug prone? Are there any antipatterns? Understanding such characteristics of bugs in deep learning software has the potential to foster the development of better deep learning platforms, debugging mechanisms, development practices, and encourage the development of analysis and verification frameworks. Therefore, we study 2716 high-quality posts from Stack Overflow and 500 bug fix commits from Github about five popular deep learning libraries Caffe, Keras, Tensorflow, Theano, and Torch to understand the types of bugs, root causes of bugs, impacts of bugs, bug-prone stage of deep learning pipeline as well as whether there are some common antipatterns found in this buggy software. The key findings of our study include: data bug and logic bug are the most severe bug types in deep learning software appearing more than 48% of the times, major root causes of these bugs are Incorrect Model Parameter (IPS) and Structural Inefficiency (SI) showing up more than 43% of the times. We have also found that the bugs in the usage of deep learning libraries have some common antipatterns that lead to a strong correlation of bug types among the libraries.
Identifying Classes Susceptible to Adversarial Attacks
May 30, 2019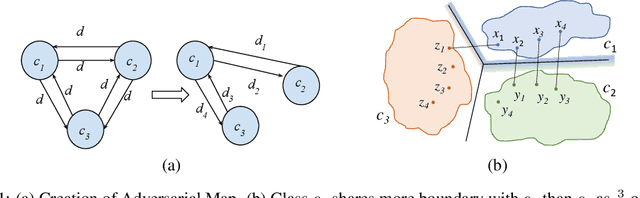

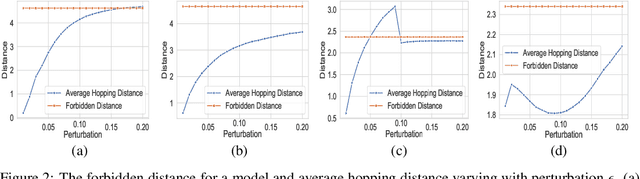
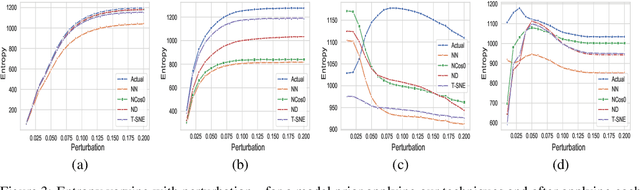
Despite numerous attempts to defend deep learning based image classifiers, they remain susceptible to the adversarial attacks. This paper proposes a technique to identify susceptible classes, those classes that are more easily subverted. To identify the susceptible classes we use distance-based measures and apply them on a trained model. Based on the distance among original classes, we create mapping among original classes and adversarial classes that helps to reduce the randomness of a model to a significant amount in an adversarial setting. We analyze the high dimensional geometry among the feature classes and identify the k most susceptible target classes in an adversarial attack. We conduct experiments using MNIST, Fashion MNIST, CIFAR-10 (ImageNet and ResNet-32) datasets. Finally, we evaluate our techniques in order to determine which distance-based measure works best and how the randomness of a model changes with perturbation.