 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepository-Level Compositional Code Translation and Validation
Paper and Code
Oct 31, 2024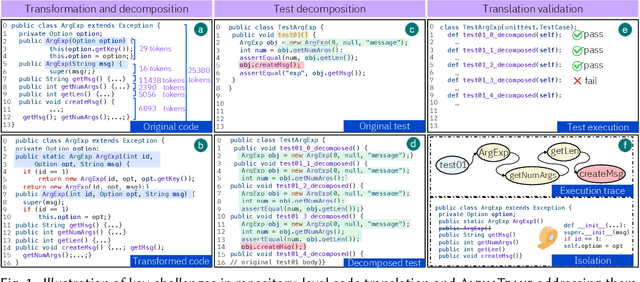
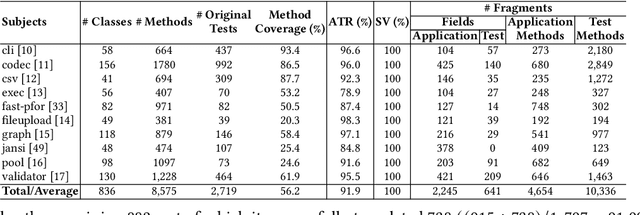
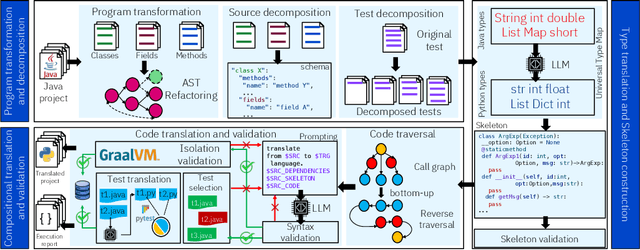
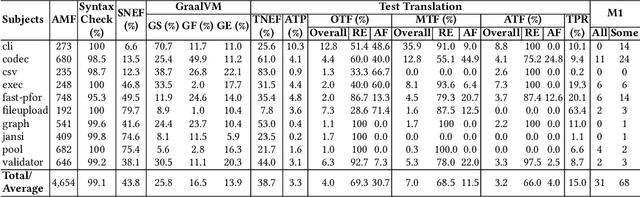
Code translation transforms programs from one programming language (PL) to another. Several rule-based transpilers have been designed to automate code translation between different pairs of PLs. However, the rules can become obsolete as the PLs evolve and cannot generalize to other PLs. Recent studies have explored the automation of code translation using Large Language Models (LLMs). One key observation is that such techniques may work well for crafted benchmarks but fail to generalize to the scale and complexity of real-world projects with dependencies, custom types, PL-specific features, etc. We propose AlphaTrans, a neuro-symbolic approach to automate repository-level code translation. AlphaTrans translates both source and test code, and employs multiple levels of validation to ensure the translation preserves the functionality of the source program. To break down the problem for LLMs, AlphaTrans leverages program analysis to decompose the program into fragments and translates them in the reverse call order. We leveraged AlphaTrans to translate ten real-world open-source projects consisting of <836, 8575, 2719> classes, methods, and tests. AlphaTrans translated the entire repository of these projects consisting of 6899 source code fragments. 99.1% of the translated code fragments are syntactically correct, and AlphaTrans validates the translations' runtime behavior and functional correctness for 25.8%. On average, the integrated translation and validation take 36 hours to translate a project, showing its scalability in practice. For the syntactically or semantically incorrect translations, AlphaTrans generates a report including existing translation, stack trace, test errors, or assertion failures. We provided these artifacts to two developers to fix the translation bugs in four projects. They were able to fix the issues in 20.1 hours on average and achieve all passing tests.