 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCodeAgent: A Multi-Agent Workflow for Language-agnostic Translation and Validation of Large-scale Repositories
Apr 08, 2026Most repository-level code translation and validation techniques have been evaluated on a single source-target programming language (PL) pair, owing to the complex engineering effort required to adapt new PL pairs. Programming agents can enable PL-agnosticism in repository-level code translation and validation: they can synthesize code across many PLs and autonomously use existing tools specific to each PL's analysis. However, state-of-the-art has yet to offer a fully autonomous agentic approach for repository-level code translation and validation of large-scale programs. This paper proposes ReCodeAgent, an autonomous multi-agent approach for language-agnostic repository-level code translation and validation. Users only need to provide the project in the source PL and specify the target PL for ReCodeAgent to automatically translate and validate the entire repository. ReCodeAgent is the first technique to achieve high translation success rates across many PLs. We compare the effectiveness of ReCodeAgent with four alternative neuro-symbolic and agentic approaches to translate 118 real-world projects, with 1,975 LoC and 43 translation units for each project, on average. The projects cover 6 PLs (C, Go, Java, JavaScript, Python, and Rust) and 4 PL pairs (C-Rust, Go-Rust, Java-Python, Python-JavaScript). Our results demonstrate that ReCodeAgent consistently outperforms prior techniques on translation correctness, improving test pass rate by 60.8% on ground-truth tests, with an average cost of $15.3. We also perform process-centric analysis of ReCodeAgent trajectories to confirm its procedural efficiency. Finally, we investigate how the design choices (a multi-agent vs. single-agent architecture) influence ReCodeAgent performance: on average, the test pass rate drops by 40.4%, and trajectories become 28% longer and persistently inefficient.
MatchFixAgent: Language-Agnostic Autonomous Repository-Level Code Translation Validation and Repair
Sep 19, 2025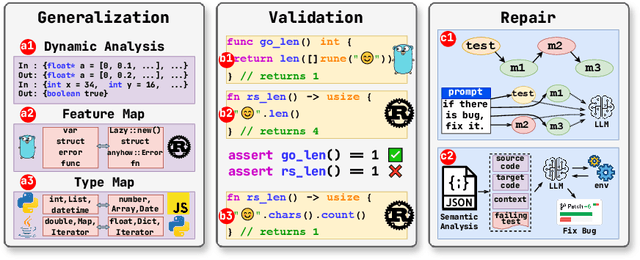



Code translation transforms source code from one programming language (PL) to another. Validating the functional equivalence of translation and repairing, if necessary, are critical steps in code translation. Existing automated validation and repair approaches struggle to generalize to many PLs due to high engineering overhead, and they rely on existing and often inadequate test suites, which results in false claims of equivalence and ineffective translation repair. We develop MatchFixAgent, a large language model (LLM)-based, PL-agnostic framework for equivalence validation and repair of translations. MatchFixAgent features a multi-agent architecture that divides equivalence validation into several sub-tasks to ensure thorough and consistent semantic analysis of the translation. Then it feeds this analysis to test agent to write and execute tests. Upon observing a test failure, the repair agent attempts to fix the translation bug. The final (in)equivalence decision is made by the verdict agent, considering semantic analyses and test execution results. We compare MatchFixAgent's validation and repair results with four repository-level code translation techniques. We use 2,219 translation pairs from their artifacts, which cover 6 PL pairs, and are collected from 24 GitHub projects totaling over 900K lines of code. Our results demonstrate that MatchFixAgent produces (in)equivalence verdicts for 99.2% of translation pairs, with the same equivalence validation result as prior work on 72.8% of them. When MatchFixAgent's result disagrees with prior work, we find that 60.7% of the time MatchFixAgent's result is actually correct. In addition, we show that MatchFixAgent can repair 50.6% of inequivalent translation, compared to prior work's 18.5%. This demonstrates that MatchFixAgent is far more adaptable to many PL pairs than prior work, while producing highly accurate validation results.
Repository-Level Compositional Code Translation and Validation
Oct 31, 2024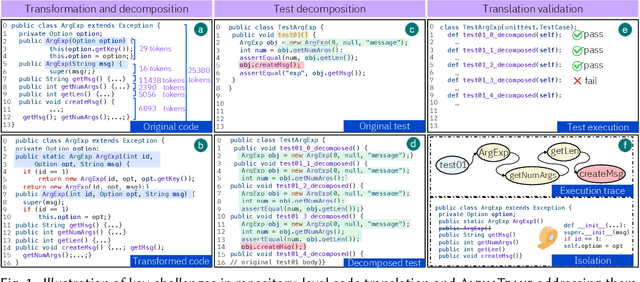
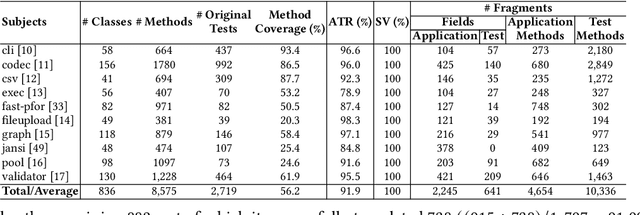
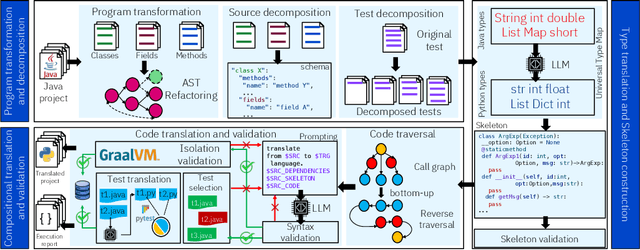
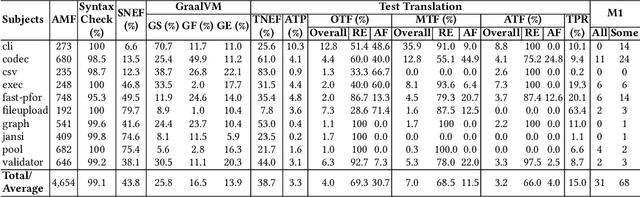
Code translation transforms programs from one programming language (PL) to another. Several rule-based transpilers have been designed to automate code translation between different pairs of PLs. However, the rules can become obsolete as the PLs evolve and cannot generalize to other PLs. Recent studies have explored the automation of code translation using Large Language Models (LLMs). One key observation is that such techniques may work well for crafted benchmarks but fail to generalize to the scale and complexity of real-world projects with dependencies, custom types, PL-specific features, etc. We propose AlphaTrans, a neuro-symbolic approach to automate repository-level code translation. AlphaTrans translates both source and test code, and employs multiple levels of validation to ensure the translation preserves the functionality of the source program. To break down the problem for LLMs, AlphaTrans leverages program analysis to decompose the program into fragments and translates them in the reverse call order. We leveraged AlphaTrans to translate ten real-world open-source projects consisting of <836, 8575, 2719> classes, methods, and tests. AlphaTrans translated the entire repository of these projects consisting of 6899 source code fragments. 99.1% of the translated code fragments are syntactically correct, and AlphaTrans validates the translations' runtime behavior and functional correctness for 25.8%. On average, the integrated translation and validation take 36 hours to translate a project, showing its scalability in practice. For the syntactically or semantically incorrect translations, AlphaTrans generates a report including existing translation, stack trace, test errors, or assertion failures. We provided these artifacts to two developers to fix the translation bugs in four projects. They were able to fix the issues in 20.1 hours on average and achieve all passing tests.
Automated Bug Generation in the era of Large Language Models
Oct 03, 2023



Bugs are essential in software engineering; many research studies in the past decades have been proposed to detect, localize, and repair bugs in software systems. Effectiveness evaluation of such techniques requires complex bugs, i.e., those that are hard to detect through testing and hard to repair through debugging. From the classic software engineering point of view, a hard-to-repair bug differs from the correct code in multiple locations, making it hard to localize and repair. Hard-to-detect bugs, on the other hand, manifest themselves under specific test inputs and reachability conditions. These two objectives, i.e., generating hard-to-detect and hard-to-repair bugs, are mostly aligned; a bug generation technique can change multiple statements to be covered only under a specific set of inputs. However, these two objectives are conflicting for learning-based techniques: A bug should have a similar code representation to the correct code in the training data to challenge a bug prediction model to distinguish them. The hard-to-repair bug definition remains the same but with a caveat: the more a bug differs from the original code (at multiple locations), the more distant their representations are and easier to be detected. We propose BugFarm, to transform arbitrary code into multiple complex bugs. BugFarm leverages LLMs to mutate code in multiple locations (hard-to-repair). To ensure that multiple modifications do not notably change the code representation, BugFarm analyzes the attention of the underlying model and instructs LLMs to only change the least attended locations (hard-to-detect). Our comprehensive evaluation of 320k+ bugs from over 2.5M mutants generated by BugFarm and two alternative approaches demonstrates our superiority in generating bugs that are hard to detect by learning-based bug prediction approaches and hard to repair by SOTA learning-based program repair technique.
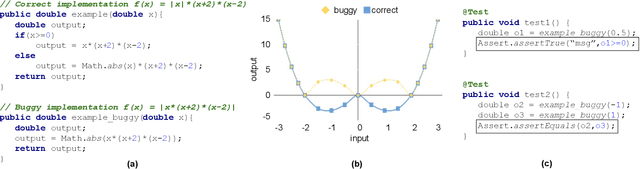
Perfect Is the Enemy of Test Oracle
Feb 03, 2023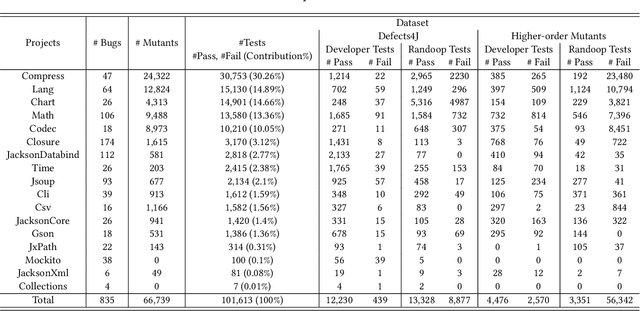
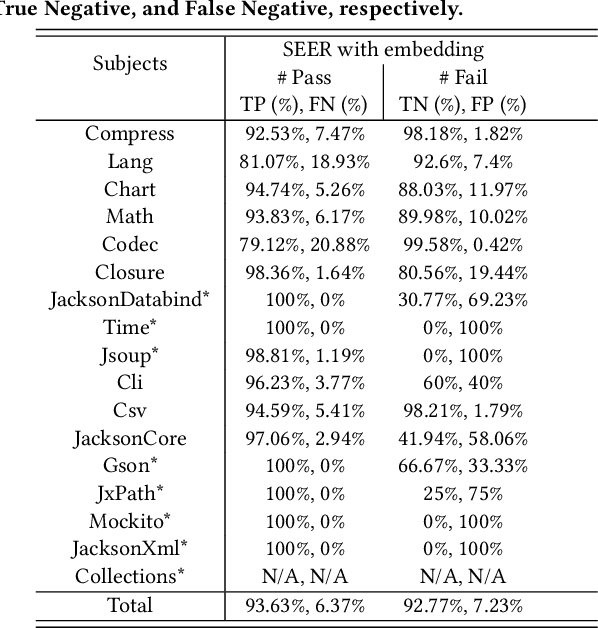
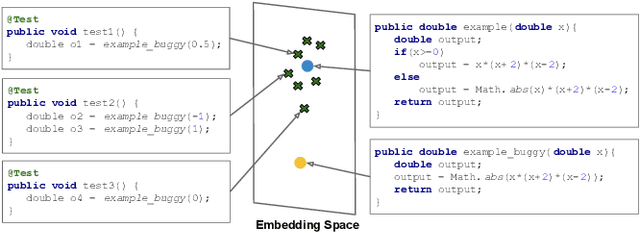
Automation of test oracles is one of the most challenging facets of software testing, but remains comparatively less addressed compared to automated test input generation. Test oracles rely on a ground-truth that can distinguish between the correct and buggy behavior to determine whether a test fails (detects a bug) or passes. What makes the oracle problem challenging and undecidable is the assumption that the ground-truth should know the exact expected, correct, or buggy behavior. However, we argue that one can still build an accurate oracle without knowing the exact correct or buggy behavior, but how these two might differ. This paper presents SEER, a learning-based approach that in the absence of test assertions or other types of oracle, can determine whether a unit test passes or fails on a given method under test (MUT). To build the ground-truth, SEER jointly embeds unit tests and the implementation of MUTs into a unified vector space, in such a way that the neural representation of tests are similar to that of MUTs they pass on them, but dissimilar to MUTs they fail on them. The classifier built on top of this vector representation serves as the oracle to generate "fail" labels, when test inputs detect a bug in MUT or "pass" labels, otherwise. Our extensive experiments on applying SEER to more than 5K unit tests from a diverse set of open-source Java projects show that the produced oracle is (1) effective in predicting the fail or pass labels, achieving an overall accuracy, precision, recall, and F1 measure of 93%, 86%, 94%, and 90%, (2) generalizable, predicting the labels for the unit test of projects that were not in training or validation set with negligible performance drop, and (3) efficient, detecting the existence of bugs in only 6.5 milliseconds on average.