 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRepair: An Intent-Aware Approach to Repair Data-Driven Errors in Large Language Models
Feb 12, 2025



Not a day goes by without hearing about the impressive feats of large language models (LLMs), and equally, not a day passes without hearing about their challenges. LLMs are notoriously vulnerable to biases in their dataset, leading to issues such as toxicity. While domain-adaptive training has been employed to mitigate these issues, these techniques often address all model parameters indiscriminately during the repair process, resulting in poor repair quality and reduced model versatility. In this paper, we introduce a novel dynamic slicing-based intent-aware LLM repair strategy, IRepair. This approach selectively targets the most error-prone sections of the model for repair. Specifically, we propose dynamically slicing the model's most sensitive layers that require immediate attention, concentrating repair efforts on those areas. This method enables more effective repairs with potentially less impact on the model's overall performance by altering a smaller portion of the model. We evaluated our technique on three models from the GPT2 and GPT-Neo families, with parameters ranging from 800M to 1.6B, in a toxicity mitigation setup. Our results show that IRepair repairs errors 43.6% more effectively while causing 46% less disruption to general performance compared to the closest baseline, direct preference optimization. Our empirical analysis also reveals that errors are more concentrated in a smaller section of the model, with the top 20% of layers exhibiting 773% more error density than the remaining 80\%. This highlights the need for selective repair. Additionally, we demonstrate that a dynamic selection approach is essential for addressing errors dispersed throughout the model, ensuring a robust and efficient repair.
What Kinds of Contracts Do ML APIs Need?
Jul 26, 2023Recent work has shown that Machine Learning (ML) programs are error-prone and called for contracts for ML code. Contracts, as in the design by contract methodology, help document APIs and aid API users in writing correct code. The question is: what kinds of contracts would provide the most help to API users? We are especially interested in what kinds of contracts help API users catch errors at earlier stages in the ML pipeline. We describe an empirical study of posts on Stack Overflow of the four most often-discussed ML libraries: TensorFlow, Scikit-learn, Keras, and PyTorch. For these libraries, our study extracted 413 informal (English) API specifications. We used these specifications to understand the following questions. What are the root causes and effects behind ML contract violations? Are there common patterns of ML contract violations? When does understanding ML contracts require an advanced level of ML software expertise? Could checking contracts at the API level help detect the violations in early ML pipeline stages? Our key findings are that the most commonly needed contracts for ML APIs are either checking constraints on single arguments of an API or on the order of API calls. The software engineering community could employ existing contract mining approaches to mine these contracts to promote an increased understanding of ML APIs. We also noted a need to combine behavioral and temporal contract mining approaches. We report on categories of required ML contracts, which may help designers of contract languages.
Decomposing a Recurrent Neural Network into Modules for Enabling Reusability and Replacement
Dec 15, 2022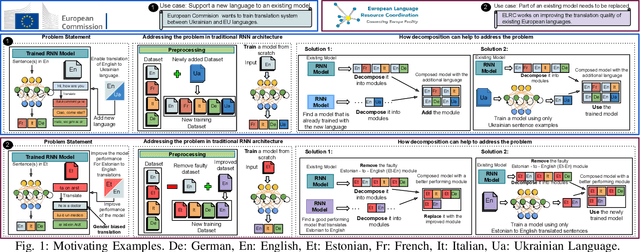
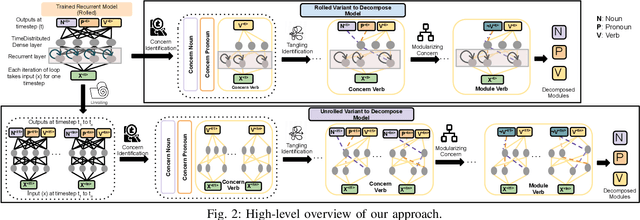

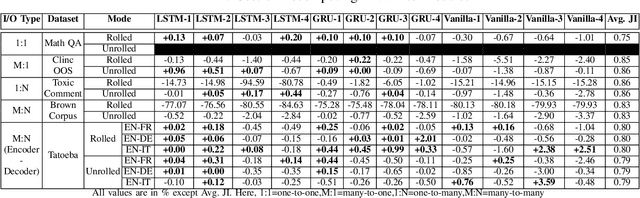
Can we take a recurrent neural network (RNN) trained to translate between languages and augment it to support a new natural language without retraining the model from scratch? Can we fix the faulty behavior of the RNN by replacing portions associated with the faulty behavior? Recent works on decomposing a fully connected neural network (FCNN) and convolutional neural network (CNN) into modules have shown the value of engineering deep models in this manner, which is standard in traditional SE but foreign for deep learning models. However, prior works focus on the image-based multiclass classification problems and cannot be applied to RNN due to (a) different layer structures, (b) loop structures, (c) different types of input-output architectures, and (d) usage of both nonlinear and logistic activation functions. In this work, we propose the first approach to decompose an RNN into modules. We study different types of RNNs, i.e., Vanilla, LSTM, and GRU. Further, we show how such RNN modules can be reused and replaced in various scenarios. We evaluate our approach against 5 canonical datasets (i.e., Math QA, Brown Corpus, Wiki-toxicity, Clinc OOS, and Tatoeba) and 4 model variants for each dataset. We found that decomposing a trained model has a small cost (Accuracy: -0.6%, BLEU score: +0.10%). Also, the decomposed modules can be reused and replaced without needing to retrain.