 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Policy Minimum Bayesian Risk
May 22, 2025Inference scaling can help LLMs solve complex reasoning problems through extended runtime computation. On top of targeted supervision for long chain-of-thought (long-CoT) generation, purely inference-time techniques such as best-of-N (BoN) sampling, majority voting, or more generally, minimum Bayes risk decoding (MBRD), can further improve LLM accuracy by generating multiple candidate solutions and aggregating over them. These methods typically leverage additional signals in the form of reward models and risk/similarity functions that compare generated samples, e.g., exact match in some normalized space or standard similarity metrics such as Rouge. Here we present a novel method for incorporating reward and risk/similarity signals into MBRD. Based on the concept of optimal policy in KL-controlled reinforcement learning, our framework provides a simple and well-defined mechanism for leveraging such signals, offering several advantages over traditional inference-time methods: higher robustness, improved accuracy, and well-understood asymptotic behavior. In addition, it allows for the development of a sample-efficient variant of MBRD that can adjust the number of samples to generate according to the difficulty of the problem, without relying on majority vote counts. We empirically demonstrate the advantages of our approach on math (MATH-$500$) and coding (HumanEval) tasks using recent open-source models. We also present a comprehensive analysis of its accuracy-compute trade-offs.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
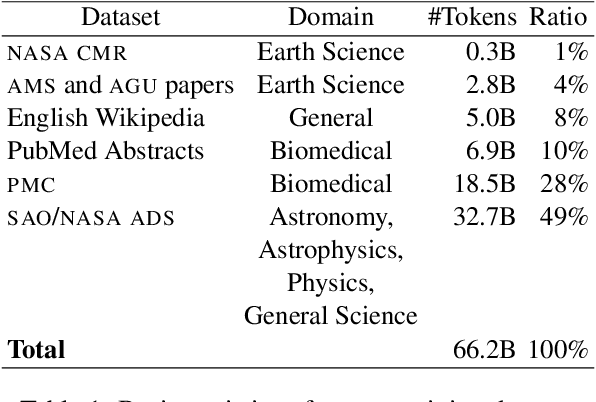
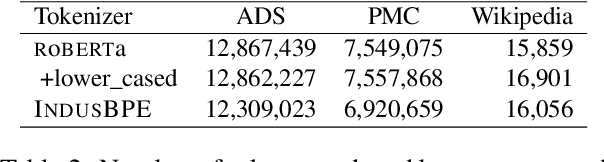

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Ensemble-Instruct: Generating Instruction-Tuning Data with a Heterogeneous Mixture of LMs
Oct 21, 2023



Using in-context learning (ICL) for data generation, techniques such as Self-Instruct (Wang et al., 2023) or the follow-up Alpaca (Taori et al., 2023) can train strong conversational agents with only a small amount of human supervision. One limitation of these approaches is that they resort to very large language models (around 175B parameters) that are also proprietary and non-public. Here we explore the application of such techniques to language models that are much smaller (around 10B--40B parameters) and have permissive licenses. We find the Self-Instruct approach to be less effective at these sizes and propose new ICL methods that draw on two main ideas: (a) Categorization and simplification of the ICL templates to make prompt learning easier for the LM, and (b) Ensembling over multiple LM outputs to help select high-quality synthetic examples. Our algorithm leverages the 175 Self-Instruct seed tasks and employs separate pipelines for instructions that require an input and instructions that do not. Empirical investigations with different LMs show that: (1) Our proposed method yields higher-quality instruction tuning data than Self-Instruct, (2) It improves performances of both vanilla and instruction-tuned LMs by significant margins, and (3) Smaller instruction-tuned LMs generate more useful outputs than their larger un-tuned counterparts. Our codebase is available at https://github.com/IBM/ensemble-instruct.
Neural Architecture Search for Effective Teacher-Student Knowledge Transfer in Language Models
Mar 16, 2023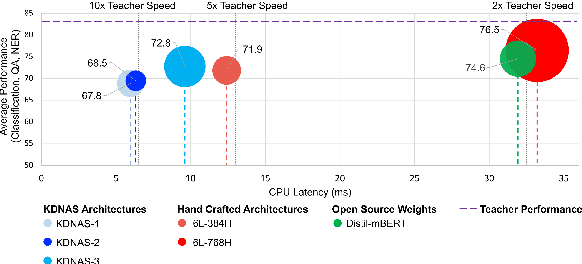

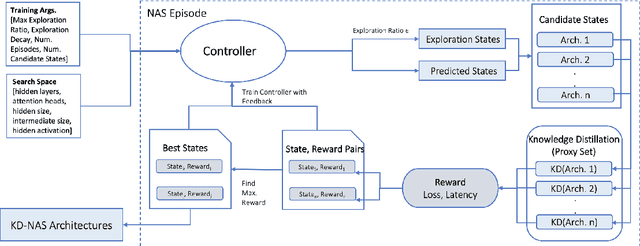
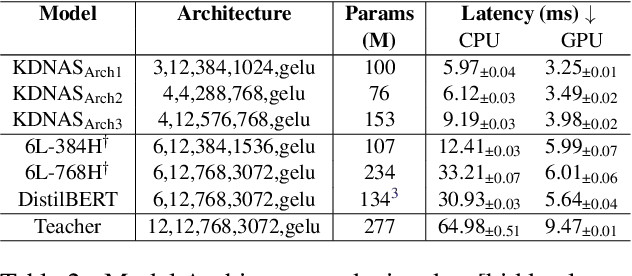
Large pre-trained language models have achieved state-of-the-art results on a variety of downstream tasks. Knowledge Distillation (KD) of a smaller student model addresses their inefficiency, allowing for deployment in resource-constraint environments. KD however remains ineffective, as the student is manually selected from a set of existing options already pre-trained on large corpora, a sub-optimal choice within the space of all possible student architectures. This paper proposes KD-NAS, the use of Neural Architecture Search (NAS) guided by the Knowledge Distillation process to find the optimal student model for distillation from a teacher, for a given natural language task. In each episode of the search process, a NAS controller predicts a reward based on a combination of accuracy on the downstream task and latency of inference. The top candidate architectures are then distilled from the teacher on a small proxy set. Finally the architecture(s) with the highest reward is selected, and distilled on the full downstream task training set. When distilling on the MNLI task, our KD-NAS model produces a 2 point improvement in accuracy on GLUE tasks with equivalent GPU latency with respect to a hand-crafted student architecture available in the literature. Using Knowledge Distillation, this model also achieves a 1.4x speedup in GPU Latency (3.2x speedup on CPU) with respect to a BERT-Base Teacher, while maintaining 97% performance on GLUE Tasks (without CoLA). We also obtain an architecture with equivalent performance as the hand-crafted student model on the GLUE benchmark, but with a 15% speedup in GPU latency (20% speedup in CPU latency) and 0.8 times the number of parameters
Zero-Shot Dynamic Quantization for Transformer Inference
Nov 17, 2022


We introduce a novel run-time method for significantly reducing the accuracy loss associated with quantizing BERT-like models to 8-bit integers. Existing methods for quantizing models either modify the training procedure,or they require an additional calibration step to adjust parameters that also requires a selected held-out dataset. Our method permits taking advantage of quantization without the need for these adjustments. We present results on several NLP tasks demonstrating the usefulness of this technique.
Multi-Granular Text Encoding for Self-Explaining Categorization
Jul 19, 2019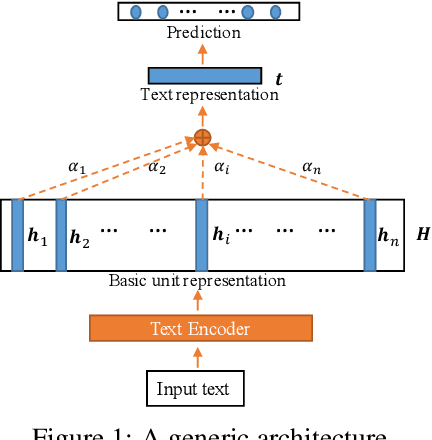
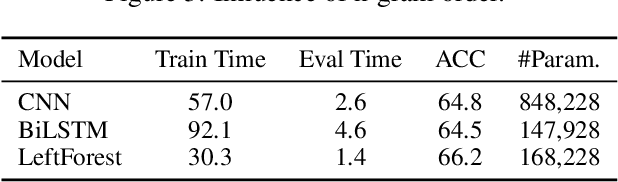
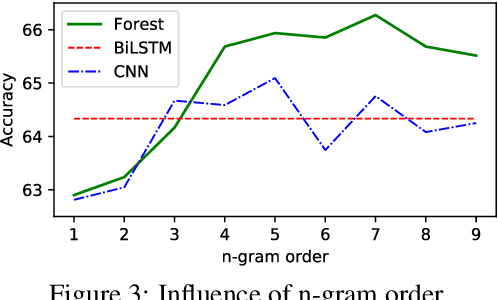
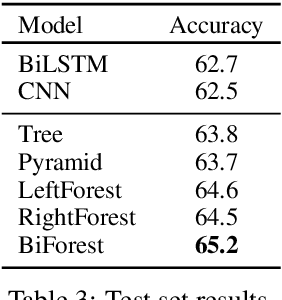
Self-explaining text categorization requires a classifier to make a prediction along with supporting evidence. A popular type of evidence is sub-sequences extracted from the input text which are sufficient for the classifier to make the prediction. In this work, we define multi-granular ngrams as basic units for explanation, and organize all ngrams into a hierarchical structure, so that shorter ngrams can be reused while computing longer ngrams. We leverage a tree-structured LSTM to learn a context-independent representation for each unit via parameter sharing. Experiments on medical disease classification show that our model is more accurate, efficient and compact than BiLSTM and CNN baselines. More importantly, our model can extract intuitive multi-granular evidence to support its predictions.