 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granular Text Encoding for Self-Explaining Categorization
Paper and Code
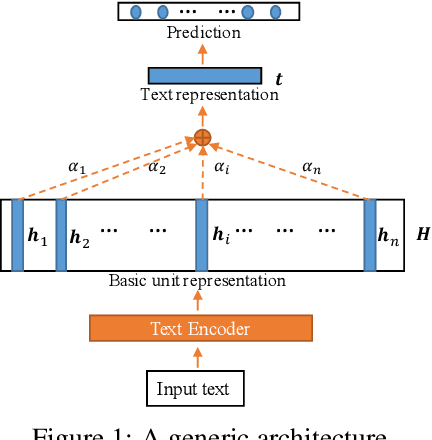
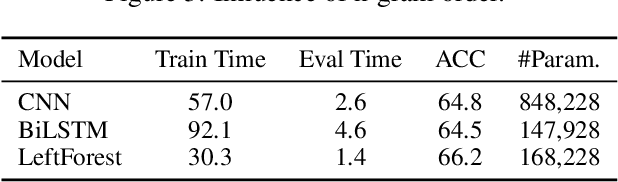
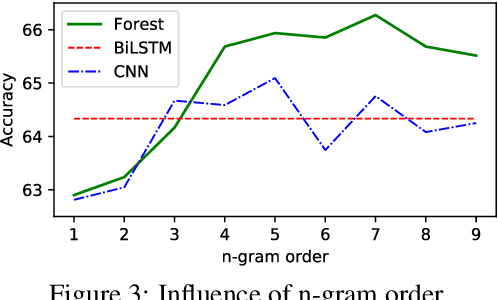
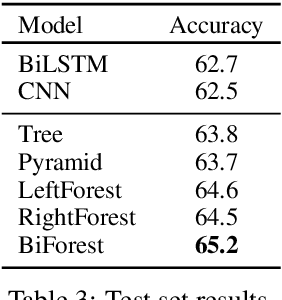
Self-explaining text categorization requires a classifier to make a prediction along with supporting evidence. A popular type of evidence is sub-sequences extracted from the input text which are sufficient for the classifier to make the prediction. In this work, we define multi-granular ngrams as basic units for explanation, and organize all ngrams into a hierarchical structure, so that shorter ngrams can be reused while computing longer ngrams. We leverage a tree-structured LSTM to learn a context-independent representation for each unit via parameter sharing. Experiments on medical disease classification show that our model is more accurate, efficient and compact than BiLSTM and CNN baselines. More importantly, our model can extract intuitive multi-granular evidence to support its predictions.