 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLM: A Python package for non-autoregressive language models
Dec 18, 2025In recent years, there has been a resurgence of interest in non-autoregressive text generation in the context of general language modeling. Unlike the well-established autoregressive language modeling paradigm, which has a plethora of standard training and inference libraries, implementations of non-autoregressive language modeling have largely been bespoke making it difficult to perform systematic comparisons of different methods. Moreover, each non-autoregressive language model typically requires it own data collation, loss, and prediction logic, making it challenging to reuse common components. In this work, we present the XLM python package, which is designed to make implementing small non-autoregressive language models faster with a secondary goal of providing a suite of small pre-trained models (through a companion xlm-models package) that can be used by the research community. The code is available at https://github.com/dhruvdcoder/xlm-core.
Quasi-random Multi-Sample Inference for Large Language Models
Nov 09, 2024



Large language models (LLMs) are often equipped with multi-sample decoding strategies. An LLM implicitly defines an arithmetic code book, facilitating efficient and embarrassingly parallelizable \textbf{arithmetic sampling} to produce multiple samples using quasi-random codes. Traditional text generation methods, such as beam search and sampling-based techniques, have notable limitations: they lack parallelizability or diversity of sampled sequences. This study explores the potential of arithmetic sampling, contrasting it with ancestral sampling across two decoding tasks that employ multi-sample inference: chain-of-thought reasoning with self-consistency and machine translation with minimum Bayes risk decoding. Our results demonstrate that arithmetic sampling produces more diverse samples, significantly improving reasoning and translation performance as the sample size increases. We observe a $\mathbf{3\text{-}5\%}$ point increase in accuracy on the GSM8K dataset and a $\mathbf{0.45\text{-}0.89\%}$ point increment in COMET score for WMT19 tasks using arithmetic sampling without any significant computational overhead.
QueryBuilder: Human-in-the-Loop Query Development for Information Retrieval
Sep 10, 2024Frequently, users of an Information Retrieval (IR) system start with an overarching information need (a.k.a., an analytic task) and proceed to define finer-grained queries covering various important aspects (i.e., sub-topics) of that analytic task. We present a novel, interactive system called $\textit{QueryBuilder}$, which allows a novice, English-speaking user to create queries with a small amount of effort, through efficient exploration of an English development corpus in order to rapidly develop cross-lingual information retrieval queries corresponding to the user's information needs. QueryBuilder performs near real-time retrieval of documents based on user-entered search terms; the user looks through the retrieved documents and marks sentences as relevant to the information needed. The marked sentences are used by the system as additional information in query formation and refinement: query terms (and, optionally, event features, which capture event $'triggers'$ (indicator terms) and agent/patient roles) are appropriately weighted, and a neural-based system, which better captures textual meaning, retrieves other relevant content. The process of retrieval and marking is repeated as many times as desired, giving rise to increasingly refined queries in each iteration. The final product is a fine-grained query used in Cross-Lingual Information Retrieval (CLIR). Our experiments using analytic tasks and requests from the IARPA BETTER IR datasets show that with a small amount of effort (at most 10 minutes per sub-topic), novice users can form $\textit{useful}$ fine-grained queries including in languages they don't understand. QueryBuilder also provides beneficial capabilities to the traditional corpus exploration and query formation process. A demonstration video is released at https://vimeo.com/734795835
Multistage Collaborative Knowledge Distillation from Large Language Models
Nov 15, 2023



We study semi-supervised sequence prediction tasks where labeled data are too scarce to effectively finetune a model and at the same time few-shot prompting of a large language model (LLM) has suboptimal performance. This happens when a task, such as parsing, is expensive to annotate and also unfamiliar to a pretrained LLM. In this paper, we present a discovery that student models distilled from a prompted LLM can often generalize better than their teacher on such tasks. Leveraging this finding, we propose a new distillation method, multistage collaborative knowledge distillation from an LLM (MCKD), for such tasks. MCKD first prompts an LLM using few-shot in-context learning to produce pseudolabels for unlabeled data. Then, at each stage of distillation, a pair of students are trained on disjoint partitions of the pseudolabeled data. Each student subsequently produces new and improved pseudolabels for the unseen partition to supervise the next round of student(s) with. We show the benefit of multistage cross-partition labeling on two constituency parsing tasks. On CRAFT biomedical parsing, 3-stage MCKD with 50 labeled examples matches the performance of supervised finetuning with 500 examples and outperforms the prompted LLM and vanilla KD by 7.5% and 3.7% parsing F1, respectively.
ExcavatorCovid: Extracting Events and Relations from Text Corpora for Temporal and Causal Analysis for COVID-19
May 05, 2021
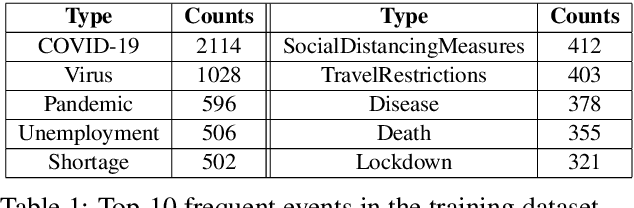
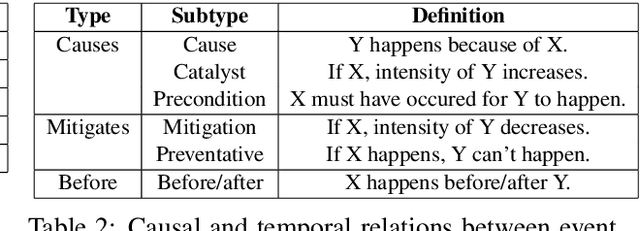

Timely responses from policy makers to mitigate the impact of the COVID-19 pandemic rely on a comprehensive grasp of events, their causes, and their impacts. These events are reported at such a speed and scale as to be overwhelming. In this paper, we present ExcavatorCovid, a machine reading system that ingests open-source text documents (e.g., news and scientific publications), extracts COVID19 related events and relations between them, and builds a Temporal and Causal Analysis Graph (TCAG). Excavator will help government agencies alleviate the information overload, understand likely downstream effects of political and economic decisions and events related to the pandemic, and respond in a timely manner to mitigate the impact of COVID-19. We expect the utility of Excavator to outlive the COVID-19 pandemic: analysts and decision makers will be empowered by Excavator to better understand and solve complex problems in the future. An interactive TCAG visualization is available at http://afrl402.bbn.com:5050/index.html. We also released a demonstration video at https://vimeo.com/528619007.