 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Post-Turing Condition: Conceptualising Artificial Subjectivity and Synthetic Sociality
Jan 19, 2026In the Post-Turing era, artificial intelligence increasingly shapes social coordination and meaning formation rather than merely automating cognitive tasks. The central challenge is therefore not whether machines become conscious, but whether processes of interpretation and shared reference are progressively automated in ways that marginalize human participation. This paper introduces the PRMO framework, relating AI design trajectories to four constitutive dimensions of human subjectivity: Perception, Representation, Meaning, and the Real. Within this framework, Synthetic Sociality denotes a technological horizon in which artificial agents negotiate coherence and social order primarily among themselves, raising the structural risk of human exclusion from meaning formation. To address this risk, the paper proposes Quadrangulation as a design principle for socially embedded AI systems, requiring artificial agents to treat the human subject as a constitutive reference within shared contexts of meaning. This work is a conceptual perspective that contributes a structural vocabulary for analyzing AI systems at the intersection of computation and society, without proposing a specific technical implementation.
On the Reduction of Biases in Big Data Sets for the Detection of Irregular Power Usage
Apr 03, 2018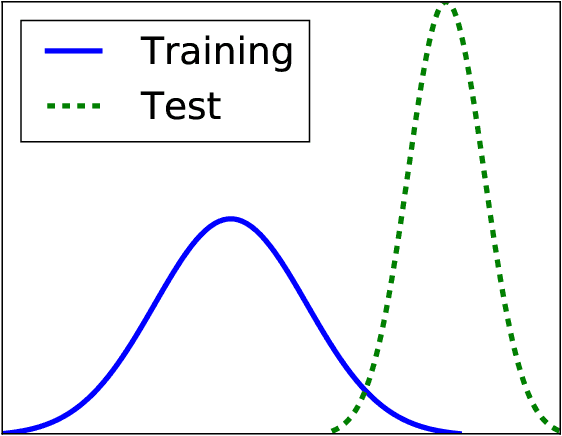



In machine learning, a bias occurs whenever training sets are not representative for the test data, which results in unreliable models. The most common biases in data are arguably class imbalance and covariate shift. In this work, we aim to shed light on this topic in order to increase the overall attention to this issue in the field of machine learning. We propose a scalable novel framework for reducing multiple biases in high-dimensional data sets in order to train more reliable predictors. We apply our methodology to the detection of irregular power usage from real, noisy industrial data. In emerging markets, irregular power usage, and electricity theft in particular, may range up to 40% of the total electricity distributed. Biased data sets are of particular issue in this domain. We show that reducing these biases increases the accuracy of the trained predictors. Our models have the potential to generate significant economic value in a real world application, as they are being deployed in a commercial software for the detection of irregular power usage.
Impact of Biases in Big Data
Mar 02, 2018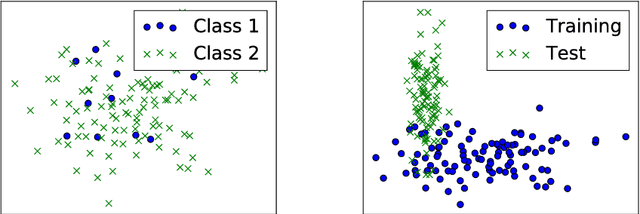



The underlying paradigm of big data-driven machine learning reflects the desire of deriving better conclusions from simply analyzing more data, without the necessity of looking at theory and models. Is having simply more data always helpful? In 1936, The Literary Digest collected 2.3M filled in questionnaires to predict the outcome of that year's US presidential election. The outcome of this big data prediction proved to be entirely wrong, whereas George Gallup only needed 3K handpicked people to make an accurate prediction. Generally, biases occur in machine learning whenever the distributions of training set and test set are different. In this work, we provide a review of different sorts of biases in (big) data sets in machine learning. We provide definitions and discussions of the most commonly appearing biases in machine learning: class imbalance and covariate shift. We also show how these biases can be quantified and corrected. This work is an introductory text for both researchers and practitioners to become more aware of this topic and thus to derive more reliable models for their learning problems.
Identifying Irregular Power Usage by Turning Predictions into Holographic Spatial Visualizations
Sep 09, 2017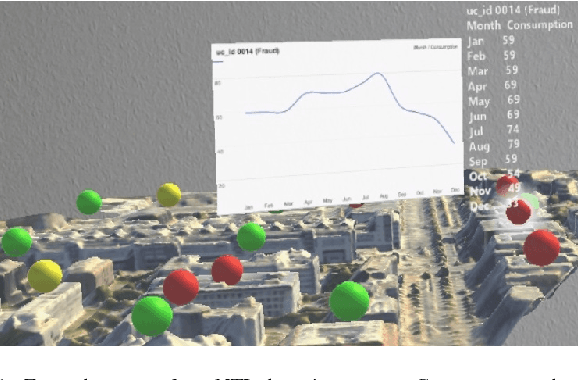
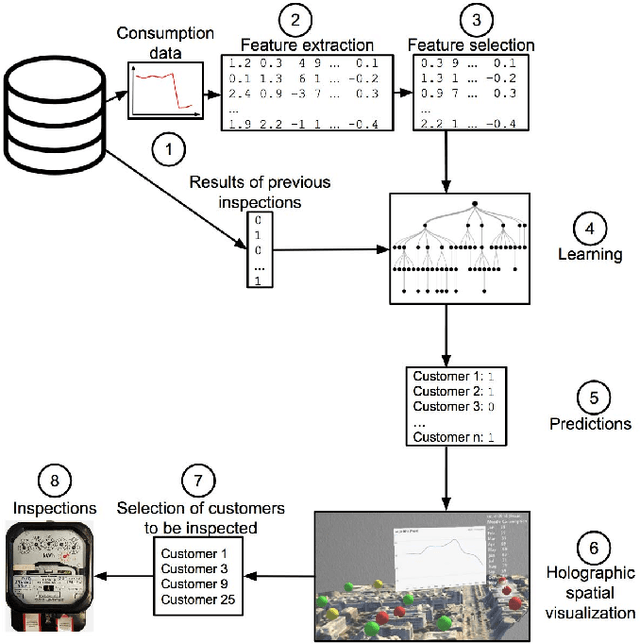

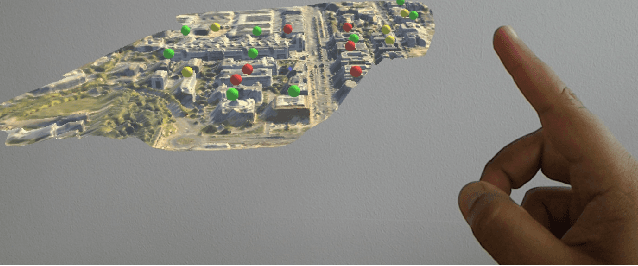
Power grids are critical infrastructure assets that face non-technical losses (NTL) such as electricity theft or faulty meters. NTL may range up to 40% of the total electricity distributed in emerging countries. Industrial NTL detection systems are still largely based on expert knowledge when deciding whether to carry out costly on-site inspections of customers. Electricity providers are reluctant to move to large-scale deployments of automated systems that learn NTL profiles from data due to the latter's propensity to suggest a large number of unnecessary inspections. In this paper, we propose a novel system that combines automated statistical decision making with expert knowledge. First, we propose a machine learning framework that classifies customers into NTL or non-NTL using a variety of features derived from the customers' consumption data. The methodology used is specifically tailored to the level of noise in the data. Second, in order to allow human experts to feed their knowledge in the decision loop, we propose a method for visualizing prediction results at various granularity levels in a spatial hologram. Our approach allows domain experts to put the classification results into the context of the data and to incorporate their knowledge for making the final decisions of which customers to inspect. This work has resulted in appreciable results on a real-world data set of 3.6M customers. Our system is being deployed in a commercial NTL detection software.
Neighborhood Features Help Detecting Non-Technical Losses in Big Data Sets
Jul 25, 2017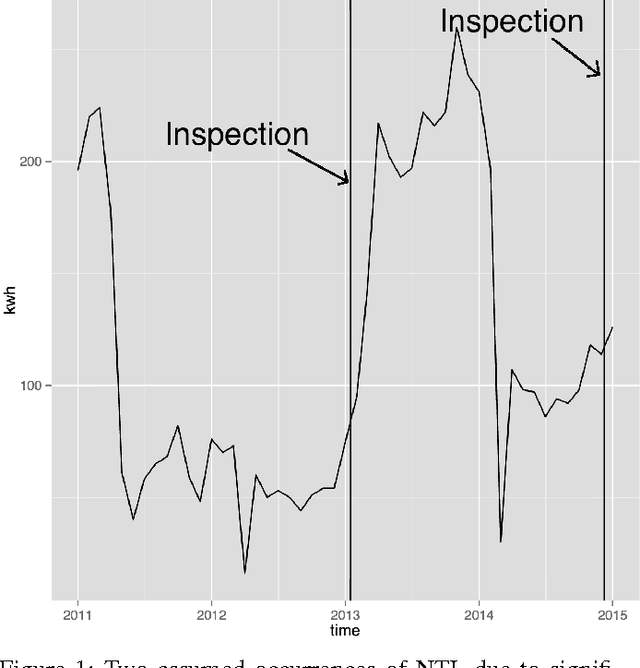
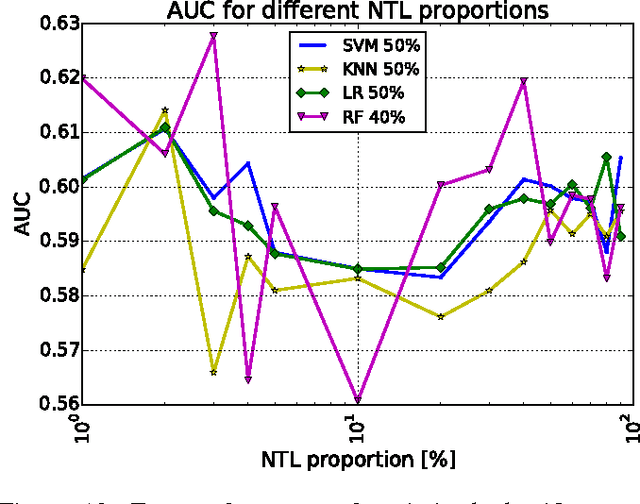
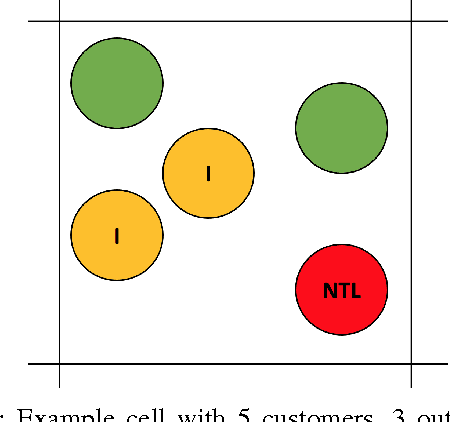
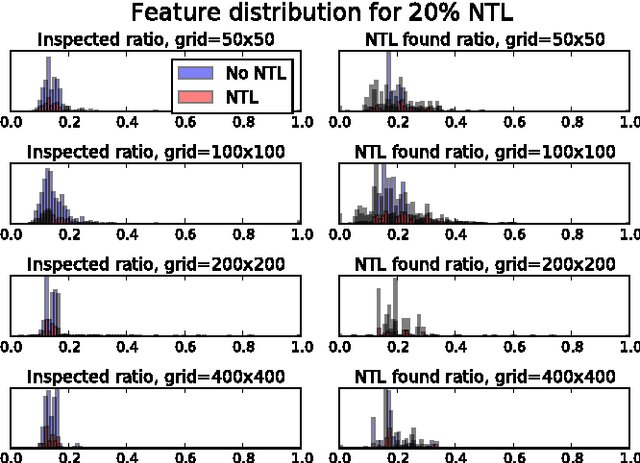
Electricity theft is a major problem around the world in both developed and developing countries and may range up to 40% of the total electricity distributed. More generally, electricity theft belongs to non-technical losses (NTL), which are losses that occur during the distribution of electricity in power grids. In this paper, we build features from the neighborhood of customers. We first split the area in which the customers are located into grids of different sizes. For each grid cell we then compute the proportion of inspected customers and the proportion of NTL found among the inspected customers. We then analyze the distributions of features generated and show why they are useful to predict NTL. In addition, we compute features from the consumption time series of customers. We also use master data features of customers, such as their customer class and voltage of their connection. We compute these features for a Big Data base of 31M meter readings, 700K customers and 400K inspection results. We then use these features to train four machine learning algorithms that are particularly suitable for Big Data sets because of their parallelizable structure: logistic regression, k-nearest neighbors, linear support vector machine and random forest. Using the neighborhood features instead of only analyzing the time series has resulted in appreciable results for Big Data sets for varying NTL proportions of 1%-90%. This work can therefore be deployed to a wide range of different regions around the world.
Is Big Data Sufficient for a Reliable Detection of Non-Technical Losses?
Jul 25, 2017
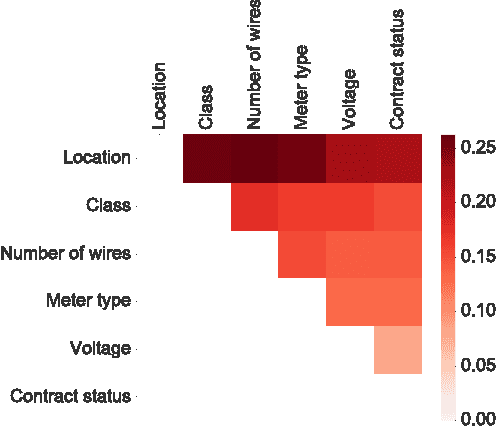
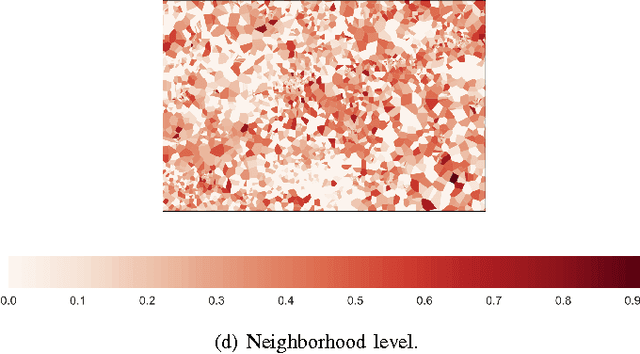
Non-technical losses (NTL) occur during the distribution of electricity in power grids and include, but are not limited to, electricity theft and faulty meters. In emerging countries, they may range up to 40% of the total electricity distributed. In order to detect NTLs, machine learning methods are used that learn irregular consumption patterns from customer data and inspection results. The Big Data paradigm followed in modern machine learning reflects the desire of deriving better conclusions from simply analyzing more data, without the necessity of looking at theory and models. However, the sample of inspected customers may be biased, i.e. it does not represent the population of all customers. As a consequence, machine learning models trained on these inspection results are biased as well and therefore lead to unreliable predictions of whether customers cause NTL or not. In machine learning, this issue is called covariate shift and has not been addressed in the literature on NTL detection yet. In this work, we present a novel framework for quantifying and visualizing covariate shift. We apply it to a commercial data set from Brazil that consists of 3.6M customers and 820K inspection results. We show that some features have a stronger covariate shift than others, making predictions less reliable. In particular, previous inspections were focused on certain neighborhoods or customer classes and that they were not sufficiently spread among the population of customers. This framework is about to be deployed in a commercial product for NTL detection.
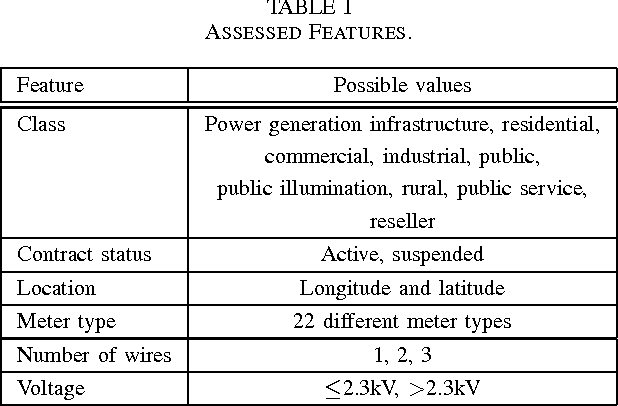
The Challenge of Non-Technical Loss Detection using Artificial Intelligence: A Survey
Jul 25, 2017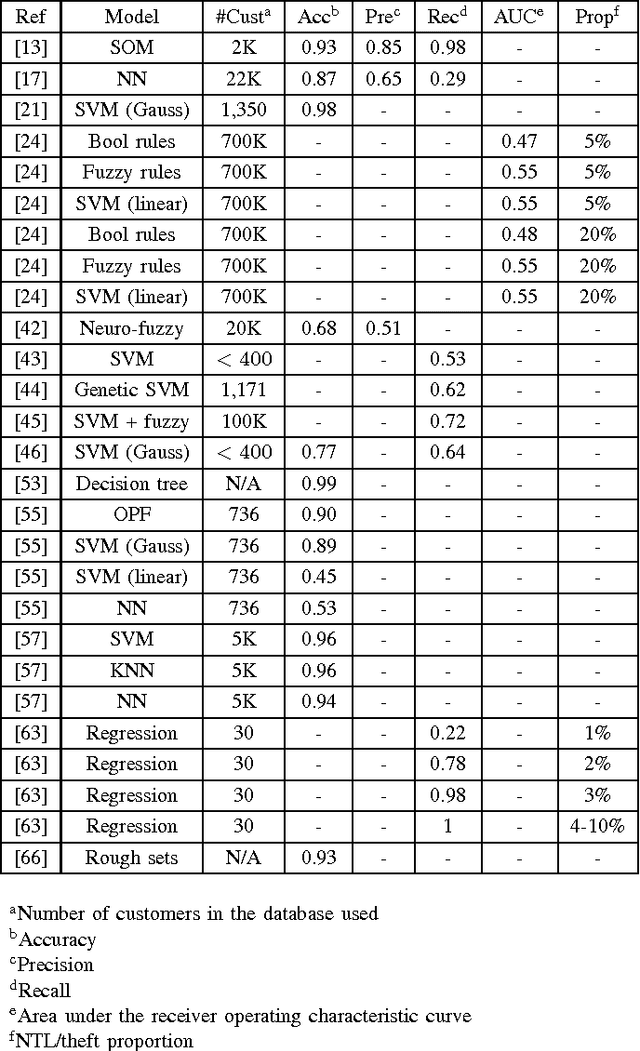
Detection of non-technical losses (NTL) which include electricity theft, faulty meters or billing errors has attracted increasing attention from researchers in electrical engineering and computer science. NTLs cause significant harm to the economy, as in some countries they may range up to 40% of the total electricity distributed. The predominant research direction is employing artificial intelligence to predict whether a customer causes NTL. This paper first provides an overview of how NTLs are defined and their impact on economies, which include loss of revenue and profit of electricity providers and decrease of the stability and reliability of electrical power grids. It then surveys the state-of-the-art research efforts in a up-to-date and comprehensive review of algorithms, features and data sets used. It finally identifies the key scientific and engineering challenges in NTL detection and suggests how they could be addressed in the future.
The Top 10 Topics in Machine Learning Revisited: A Quantitative Meta-Study
Mar 29, 2017
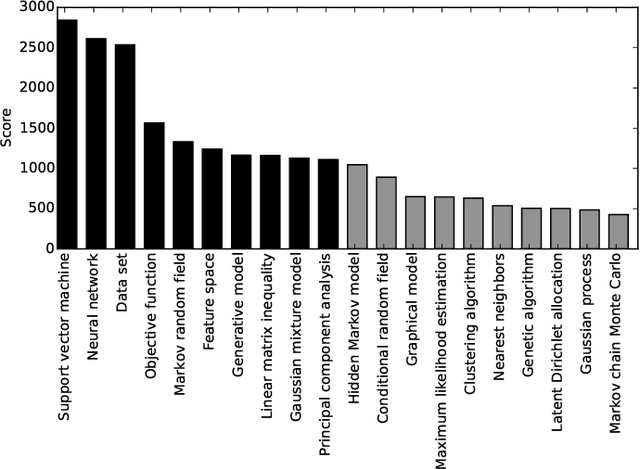
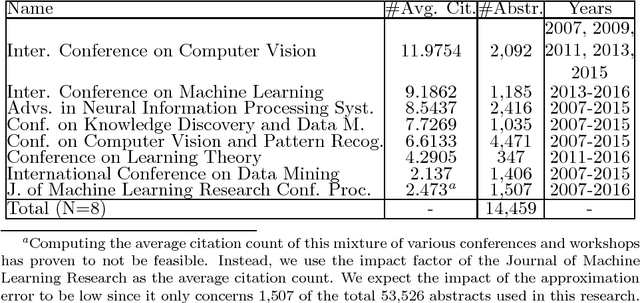
Which topics of machine learning are most commonly addressed in research? This question was initially answered in 2007 by doing a qualitative survey among distinguished researchers. In our study, we revisit this question from a quantitative perspective. Concretely, we collect 54K abstracts of papers published between 2007 and 2016 in leading machine learning journals and conferences. We then use machine learning in order to determine the top 10 topics in machine learning. We not only include models, but provide a holistic view across optimization, data, features, etc. This quantitative approach allows reducing the bias of surveys. It reveals new and up-to-date insights into what the 10 most prolific topics in machine learning research are. This allows researchers to identify popular topics as well as new and rising topics for their research.