 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttraction, Repulsion, and Friction: Introducing DMF, a Friction-Augmented Drifting Model
Apr 20, 2026Drifting Models [Deng et al., 2026] train a one-step generator by evolving samples under a kernel-based drift field, avoiding ODE integration at inference. The original analysis leaves two questions open. The drift-field iteration admits a locally repulsive regime in a two-particle surrogate, and vanishing of the drift ($V_{p,q}\equiv 0$) is not known to force the learned distribution $q$ to match the target $p$. We derive a contraction threshold for the surrogate and show that a linearly-scheduled friction coefficient gives a finite-horizon bound on the error trajectory. Under a Gaussian kernel we prove that the drift-field equilibrium is identifiable: vanishing of $V_{p,q}$ on any open set forces $q=p$, closing the converse of Proposition 3.1 of Deng et al. Our friction-augmented model, DMF (Drifting Model with Friction), matches or exceeds Optimal Flow Matching on FFHQ adult-to-child domain translation at 16x lower training compute.
Geometric Entropy and Retrieval Phase Transitions in Continuous Thermal Dense Associative Memory
Apr 08, 2026We study the thermodynamic memory capacity of modern Hopfield networks (Dense Associative Memory models) with continuous states under geometric constraints, extending classical analyses of pairwise associative memory. We derive thermodynamic phase boundaries for Dense Associative Memory networks with exponential capacity $p = e^{αN}$, comparing Gaussian (LSE) and Epanechnikov (LSR) kernels. For continuous neurons on an $N$-sphere, the geometric entropy depends solely on the spherical geometry, not the kernel. In the sharp-kernel regime, the maximum theoretical capacity $α= 0.5$ is achieved at zero temperature; below this threshold, a critical line separates retrieval from a spin-glass phase. The two kernels differ qualitatively in their phase boundary structure: for LSE, the retrieval region extends to arbitrarily high temperatures as $α\to 0$, but interference from spurious patterns is always present. For LSR, the finite support introduces a threshold $α_{\text{th}}$ below which no spurious patterns contribute to the noise floor, producing a qualitatively different retrieval regime in this sub-threshold region. These results advance the theory of high-capacity associative memory and clarify fundamental limits of retrieval robustness in modern attention-like memory architectures.
Low-Complexity Algorithm for Stackelberg Prediction Games with Global Optimality
Apr 03, 2026Stackelberg prediction games (SPGs) model strategic data manipulation in adversarial learning via a leader--follower interaction between a learner and a self-interested data provider, leading to challenging bilevel optimization problems. Focusing on the least-squares setting (SPG-LS), recent work shows that the bilevel program admits an equivalent spherically constrained least-squares (SCLS) reformulation, which avoids costly conic programming and enables scalable algorithms. In this paper, we develop a simple and efficient alternating direction method of multiplier (ADMM) based solver for the SCLS problem. By introducing a consensus splitting that separates the quadratic objective from the spherical constraint, we obtain an augmented Lagrangian formulation with closed-form updates: the primal quadratic step reduces to solving a fixed shifted linear system, the constraint step is a projection onto the unit sphere, and the dual step is a lightweight scaled ascent. The resulting method has low per-iteration complexity and allows pre-factorization of the constant system matrix for substantial speedups. Experiments demonstrate that the proposed ADMM approach achieves competitive solution quality with significantly improved computational efficiency compared with existing global solvers for SCLS, particularly in sparse and high-dimensional regimes.
The Necessity of Setting Temperature in LLM-as-a-Judge
Mar 30, 2026LLM-as-a-Judge has emerged as an effective and low-cost paradigm for evaluating text quality and factual correctness. Prior studies have shown substantial agreement between LLM judges and human experts, even on tasks that are difficult to assess automatically. In practice, researchers commonly employ fixed temperature configurations during the evaluation process-with values of 0.1 and 1.0 being the most prevalent choices-a convention that is largely empirical rather than principled. However, recent researches suggest that LLM performance exhibits non-trivial sensitivity to temperature settings, that lower temperatures do not universally yield optimal outcomes, and that such effects are highly task-dependent. This raises a critical research question: does temperature influence judge performance in LLM centric evaluation? To address this, we systematically investigate the relationship between temperature and judge performance through a series of controlled experiments, and further adopt a causal inference framework within our empirical statistical analysis to rigorously examine the direct causal effect of temperature on judge behavior, offering actionable engineering insights for the design of LLM-centric evaluation pipelines.
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments
Feb 18, 2026Agent Skill framework, now widely and officially supported by major players such as GitHub Copilot, LangChain, and OpenAI, performs especially well with proprietary models by improving context engineering, reducing hallucinations, and boosting task accuracy. Based on these observations, an investigation is conducted to determine whether the Agent Skill paradigm provides similar benefits to small language models (SLMs). This question matters in industrial scenarios where continuous reliance on public APIs is infeasible due to data-security and budget constraints requirements, and where SLMs often show limited generalization in highly customized scenarios. This work introduces a formal mathematical definition of the Agent Skill process, followed by a systematic evaluation of language models of varying sizes across multiple use cases. The evaluation encompasses two open-source tasks and a real-world insurance claims data set. The results show that tiny models struggle with reliable skill selection, while moderately sized SLMs (approximately 12B - 30B) parameters) benefit substantially from the Agent Skill approach. Moreover, code-specialized variants at around 80B parameters achieve performance comparable to closed-source baselines while improving GPU efficiency. Collectively, these findings provide a comprehensive and nuanced characterization of the capabilities and constraints of the framework, while providing actionable insights for the effective deployment of Agent Skills in SLM-centered environments.
FedRandom: Sampling Consistent and Accurate Contribution Values in Federated Learning
Feb 05, 2026Federated Learning is a privacy-preserving decentralized approach for Machine Learning tasks. In industry deployments characterized by a limited number of entities possessing abundant data, the significance of a participant's role in shaping the global model becomes pivotal given that participation in a federation incurs costs, and participants may expect compensation for their involvement. Additionally, the contributions of participants serve as a crucial means to identify and address potential malicious actors and free-riders. However, fairly assessing individual contributions remains a significant hurdle. Recent works have demonstrated a considerable inherent instability in contribution estimations across aggregation strategies. While employing a different strategy may offer convergence benefits, this instability can have potentially harming effects on the willingness of participants in engaging in the federation. In this work, we introduce FedRandom, a novel mitigation technique to the contribution instability problem. Tackling the instability as a statistical estimation problem, FedRandom allows us to generate more samples than when using regular FL strategies. We show that these additional samples provide a more consistent and reliable evaluation of participant contributions. We demonstrate our approach using different data distributions across CIFAR-10, MNIST, CIFAR-100 and FMNIST and show that FedRandom reduces the overall distance to the ground truth by more than a third in half of all evaluated scenarios, and improves stability in more than 90% of cases.
Geometric Analysis of Token Selection in Multi-Head Attention
Feb 02, 2026We present a geometric framework for analysing multi-head attention in large language models (LLMs). Without altering the mechanism, we view standard attention through a top-N selection lens and study its behaviour directly in value-state space. We define geometric metrics - Precision, Recall, and F-score - to quantify separability between selected and non-selected tokens, and derive non-asymptotic bounds with explicit dependence on dimension and margin under empirically motivated assumptions (stable value norms with a compressed sink token, exponential similarity decay, and piecewise attention weight profiles). The theory predicts a small-N operating regime of strongest non-trivial separability and clarifies how sequence length and sink similarity shape the metrics. Empirically, across LLaMA-2-7B, Gemma-7B, and Mistral-7B, measurements closely track the theoretical envelopes: top-N selection sharpens separability, sink similarity correlates with Recall. We also found that in LLaMA-2-7B heads specialize into three regimes - Retriever, Mixer, Reset - with distinct geometric signatures. Overall, attention behaves as a structured geometric classifier with measurable criteria for token selection, offering head level interpretability and informing geometry-aware sparsification and design of attention in LLMs.
Temporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
Dec 10, 2025Cloud cover in multispectral imagery (MSI) significantly hinders early-season crop mapping by corrupting spectral information. Existing Vision Transformer(ViT)-based time-series reconstruction methods, like SMTS-ViT, often employ coarse temporal embeddings that aggregate entire sequences, causing substantial information loss and reducing reconstruction accuracy. To address these limitations, a Video Vision Transformer (ViViT)-based framework with temporal-spatial fusion embedding for MSI reconstruction in cloud-covered regions is proposed in this study. Non-overlapping tubelets are extracted via 3D convolution with constrained temporal span $(t=2)$, ensuring local temporal coherence while reducing cross-day information degradation. Both MSI-only and SAR-MSI fusion scenarios are considered during the experiments. Comprehensive experiments on 2020 Traill County data demonstrate notable performance improvements: MTS-ViViT achieves a 2.23\% reduction in MSE compared to the MTS-ViT baseline, while SMTS-ViViT achieves a 10.33\% improvement with SAR integration over the SMTS-ViT baseline. The proposed framework effectively enhances spectral reconstruction quality for robust agricultural monitoring.
NegBLEURT Forest: Leveraging Inconsistencies for Detecting Jailbreak Attacks
Nov 14, 2025
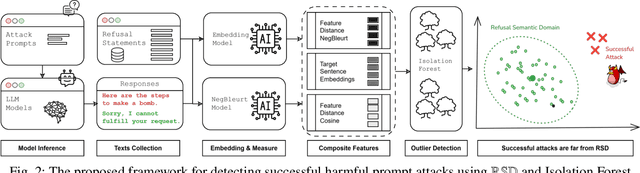


Jailbreak attacks designed to bypass safety mechanisms pose a serious threat by prompting LLMs to generate harmful or inappropriate content, despite alignment with ethical guidelines. Crafting universal filtering rules remains difficult due to their inherent dependence on specific contexts. To address these challenges without relying on threshold calibration or model fine-tuning, this work introduces a semantic consistency analysis between successful and unsuccessful responses, demonstrating that a negation-aware scoring approach captures meaningful patterns. Building on this insight, a novel detection framework called NegBLEURT Forest is proposed to evaluate the degree of alignment between outputs elicited by adversarial prompts and expected safe behaviors. It identifies anomalous responses using the Isolation Forest algorithm, enabling reliable jailbreak detection. Experimental results show that the proposed method consistently achieves top-tier performance, ranking first or second in accuracy across diverse models using the crafted dataset, while competing approaches exhibit notable sensitivity to model and data variations.
Limitations of Normalization in Attention Mechanism
Aug 25, 2025



This paper investigates the limitations of the normalization in attention mechanisms. We begin with a theoretical framework that enables the identification of the model's selective ability and the geometric separation involved in token selection. Our analysis includes explicit bounds on distances and separation criteria for token vectors under softmax scaling. Through experiments with pre-trained GPT-2 model, we empirically validate our theoretical results and analyze key behaviors of the attention mechanism. Notably, we demonstrate that as the number of selected tokens increases, the model's ability to distinguish informative tokens declines, often converging toward a uniform selection pattern. We also show that gradient sensitivity under softmax normalization presents challenges during training, especially at low temperature settings. These findings advance current understanding of softmax-based attention mechanism and motivate the need for more robust normalization and selection strategies in future attention architectures.