 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongKey: Keyphrase Extraction for Long Documents
Nov 26, 2024In an era of information overload, manually annotating the vast and growing corpus of documents and scholarly papers is increasingly impractical. Automated keyphrase extraction addresses this challenge by identifying representative terms within texts. However, most existing methods focus on short documents (up to 512 tokens), leaving a gap in processing long-context documents. In this paper, we introduce LongKey, a novel framework for extracting keyphrases from lengthy documents, which uses an encoder-based language model to capture extended text intricacies. LongKey uses a max-pooling embedder to enhance keyphrase candidate representation. Validated on the comprehensive LDKP datasets and six diverse, unseen datasets, LongKey consistently outperforms existing unsupervised and language model-based keyphrase extraction methods. Our findings demonstrate LongKey's versatility and superior performance, marking an advancement in keyphrase extraction for varied text lengths and domains.
Optimizing Neural Architecture Search using Limited GPU Time in a Dynamic Search Space: A Gene Expression Programming Approach
May 15, 2020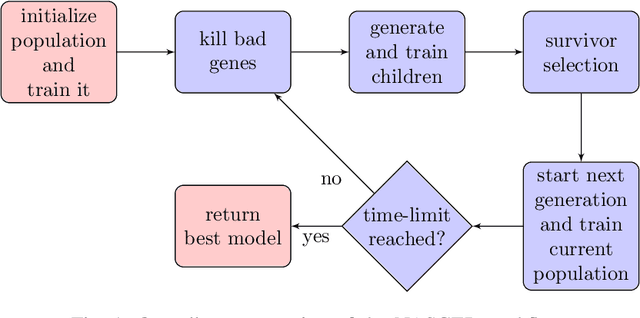
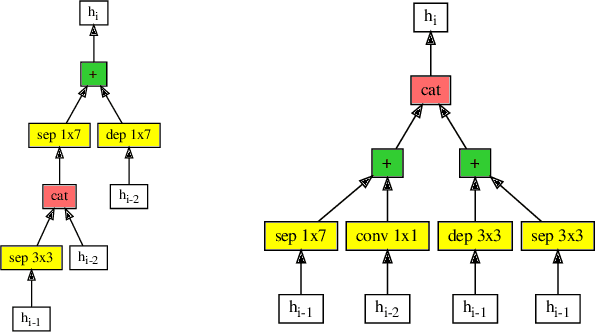

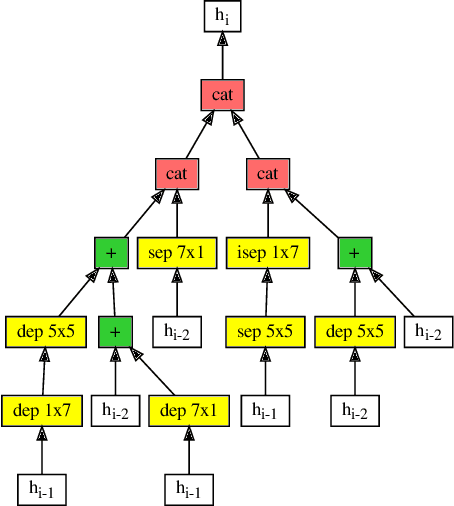
Efficient identification of people and objects, segmentation of regions of interest and extraction of relevant data in images, texts, audios and videos are evolving considerably in these past years, which deep learning methods, combined with recent improvements in computational resources, contributed greatly for this achievement. Although its outstanding potential, development of efficient architectures and modules requires expert knowledge and amount of resource time available. In this paper, we propose an evolutionary-based neural architecture search approach for efficient discovery of convolutional models in a dynamic search space, within only 24 GPU hours. With its efficient search environment and phenotype representation, Gene Expression Programming is adapted for network's cell generation. Despite having limited GPU resource time and broad search space, our proposal achieved similar state-of-the-art to manually-designed convolutional networks and also NAS-generated ones, even beating similar constrained evolutionary-based NAS works. The best cells in different runs achieved stable results, with a mean error of 2.82% in CIFAR-10 dataset (which the best model achieved an error of 2.67%) and 18.83% for CIFAR-100 (best model with 18.16%). For ImageNet in the mobile setting, our best model achieved top-1 and top-5 errors of 29.51% and 10.37%, respectively. Although evolutionary-based NAS works were reported to require a considerable amount of GPU time for architecture search, our approach obtained promising results in little time, encouraging further experiments in evolutionary-based NAS, for search and network representation improvements.