 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinority Class Oversampling for Tabular Data with Deep Generative Models
May 07, 2020

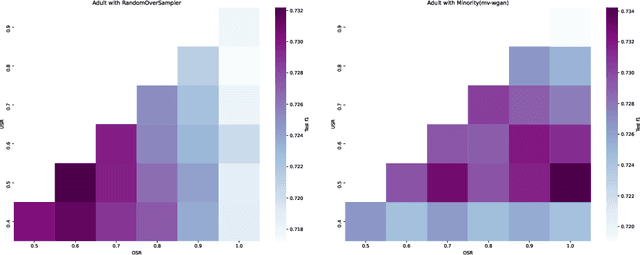

In practice, data scientists are often confronted with imbalanced data. Without accounting for the imbalance, common classifiers perform poorly and standard evaluation metrics mislead the data scientist on the model's performance. A common method to treat imbalanced datasets is under- and oversampling. In this process, samples are either removed from the majority class or synthetic samples are added to the minority class. In this paper, we follow up on recent developments in deep learning. We take proposals of generative adversarial networks, including our own, and study the ability of these approaches to provide realistic samples that improve performance on imbalanced classification tasks via oversampling. Across 160K+ experiments, we show that all of the new methods tend to perform better than simple baseline methods such as SMOTE, but require different under- and oversampling ratios to do so. Our experiments show that the way the method of sampling does not affect quality, but runtime varies widely. We also observe that the improvements in terms of performance metric, while shown to be significant when ranking the methods, often are minor in absolute terms, especially compared to the required effort. Furthermore, we notice that a large part of the improvement is due to undersampling, not oversampling. We make our code and testing framework available.
A Data Science Approach for Honeypot Detection in Ethereum
Oct 03, 2019
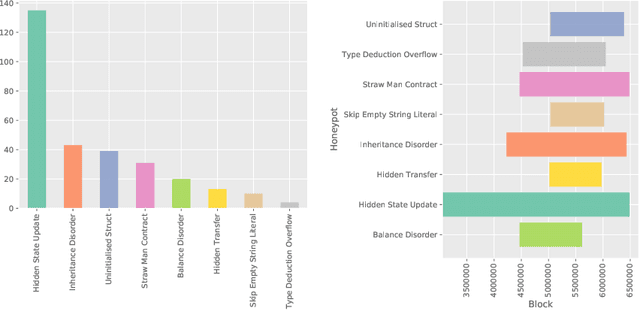
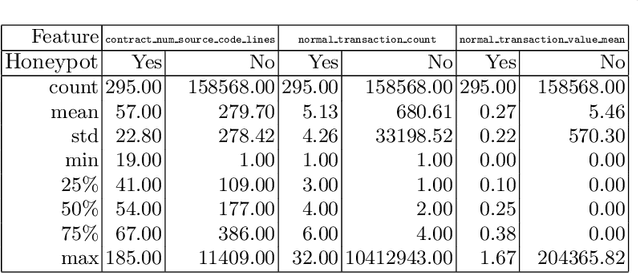

Ethereum smart contracts have recently drawn a considerable amount of attention from the media, the financial industry and academia. With the increase in popularity, malicious users found new opportunities to profit from deceiving newcomers. Consequently, attackers started luring other attackers into contracts that seem to have exploitable flaws, but that actually contain a complex hidden trap that in the end benefits the contract creator. This kind of contracts are known in the blockchain community as Honeypots. A recent study, proposed to investigate this phenomenon by focusing on the contract bytecode using symbolic analysis. In this paper, we present a data science approach based on the contract transaction behavior. We create a partition of all the possible cases of fund movement between the contract creator, the contract, the sender of the transaction and other participants. We calculate the frequency of every case per contract, and extract as well other contract features and transaction aggregated features. We use the collected information to train machine learning models that classify contracts as honeypot or non-honeypots, and also measure how well they perform when classifying unseen honeypot types. We compare our results with the bytecode analysis method using labels from a previous study, and discuss in which cases each solution has advantages over the other.
Generating Multi-Categorical Samples with Generative Adversarial Networks
Jul 04, 2018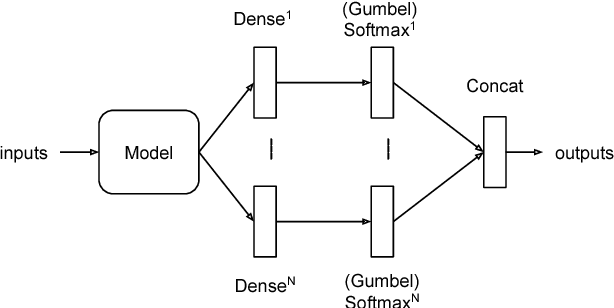


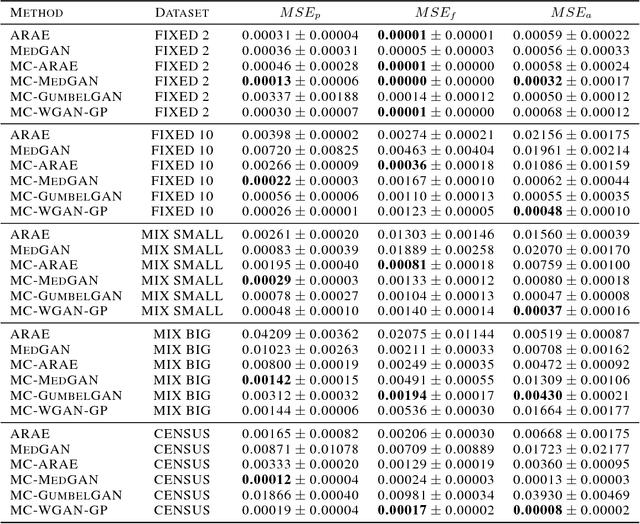
We propose a method to train generative adversarial networks on mutivariate feature vectors representing multiple categorical values. In contrast to the continuous domain, where GAN-based methods have delivered considerable results, GANs struggle to perform equally well on discrete data. We propose and compare several architectures based on multiple (Gumbel) softmax output layers taking into account the structure of the data. We evaluate the performance of our architecture on datasets with different sparsity, number of features, ranges of categorical values, and dependencies among the features. Our proposed architecture and method outperforms existing models.