 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexFringe: Modeling Software Behavior by Learning Probabilistic Automata
Mar 28, 2022



We present the efficient implementations of probabilistic deterministic finite automaton learning methods available in FlexFringe. These implement well-known strategies for state-merging including several modifications to improve their performance in practice. We show experimentally that these algorithms obtain competitive results and significant improvements over a default implementation. We also demonstrate how to use FlexFringe to learn interpretable models from software logs and use these for anomaly detection. Although less interpretable, we show that learning smaller more convoluted models improves the performance of FlexFringe on anomaly detection, outperforming an existing solution based on neural nets.
Minority Class Oversampling for Tabular Data with Deep Generative Models
May 07, 2020

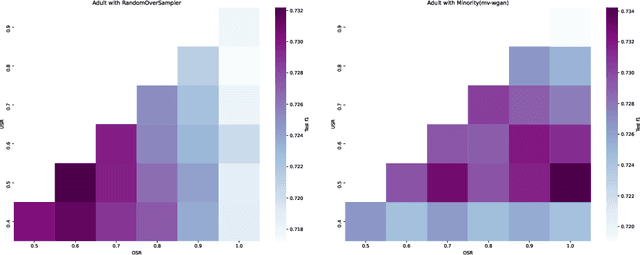

In practice, data scientists are often confronted with imbalanced data. Without accounting for the imbalance, common classifiers perform poorly and standard evaluation metrics mislead the data scientist on the model's performance. A common method to treat imbalanced datasets is under- and oversampling. In this process, samples are either removed from the majority class or synthetic samples are added to the minority class. In this paper, we follow up on recent developments in deep learning. We take proposals of generative adversarial networks, including our own, and study the ability of these approaches to provide realistic samples that improve performance on imbalanced classification tasks via oversampling. Across 160K+ experiments, we show that all of the new methods tend to perform better than simple baseline methods such as SMOTE, but require different under- and oversampling ratios to do so. Our experiments show that the way the method of sampling does not affect quality, but runtime varies widely. We also observe that the improvements in terms of performance metric, while shown to be significant when ranking the methods, often are minor in absolute terms, especially compared to the required effort. Furthermore, we notice that a large part of the improvement is due to undersampling, not oversampling. We make our code and testing framework available.
Generating Multi-Categorical Samples with Generative Adversarial Networks
Jul 04, 2018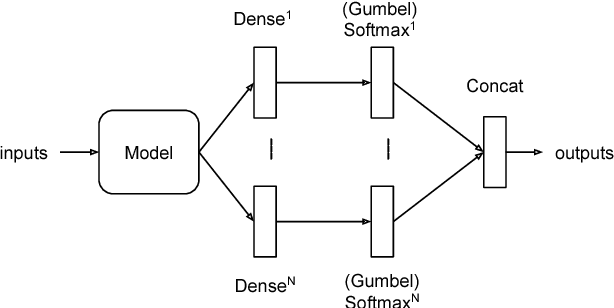


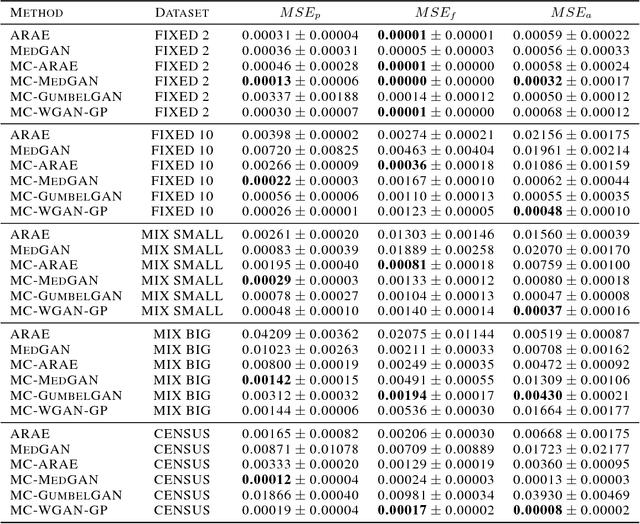
We propose a method to train generative adversarial networks on mutivariate feature vectors representing multiple categorical values. In contrast to the continuous domain, where GAN-based methods have delivered considerable results, GANs struggle to perform equally well on discrete data. We propose and compare several architectures based on multiple (Gumbel) softmax output layers taking into account the structure of the data. We evaluate the performance of our architecture on datasets with different sparsity, number of features, ranges of categorical values, and dependencies among the features. Our proposed architecture and method outperforms existing models.