 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning For Smile Recognition
Jul 25, 2017


Inspired by recent successes of deep learning in computer vision, we propose a novel application of deep convolutional neural networks to facial expression recognition, in particular smile recognition. A smile recognition test accuracy of 99.45% is achieved for the Denver Intensity of Spontaneous Facial Action (DISFA) database, significantly outperforming existing approaches based on hand-crafted features with accuracies ranging from 65.55% to 79.67%. The novelty of this approach includes a comprehensive model selection of the architecture parameters, allowing to find an appropriate architecture for each expression such as smile. This is feasible because all experiments were run on a Tesla K40c GPU, allowing a speedup of factor 10 over traditional computations on a CPU.
Large-Scale Detection of Non-Technical Losses in Imbalanced Data Sets
Jul 25, 2017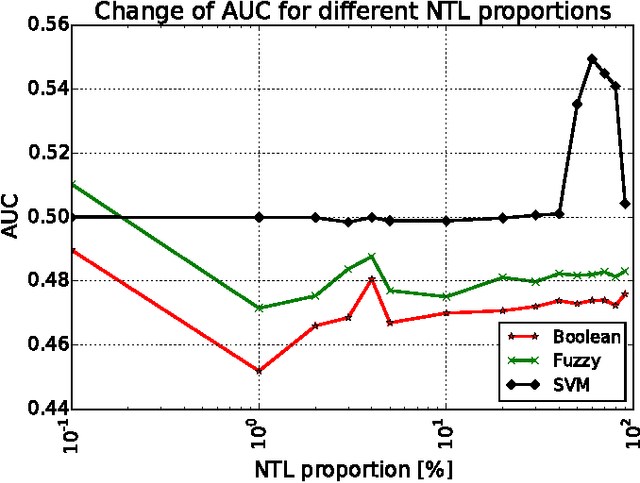
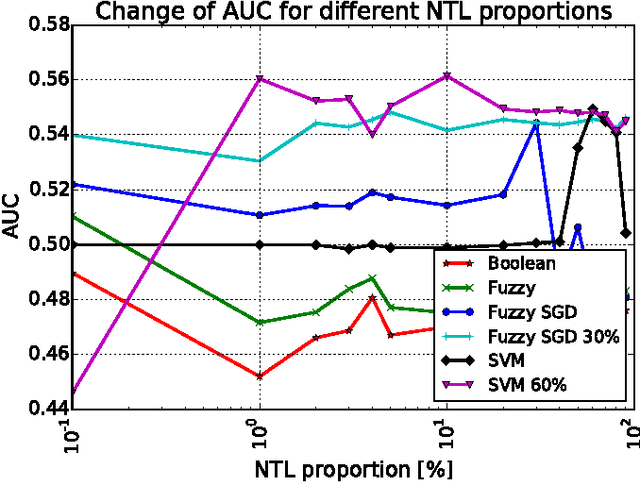
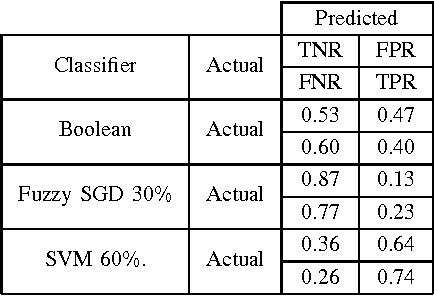
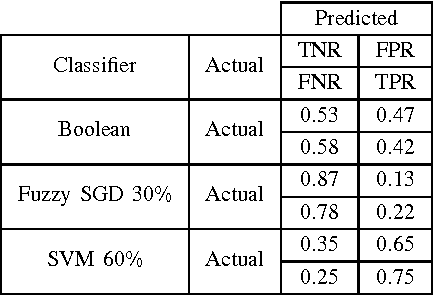
Non-technical losses (NTL) such as electricity theft cause significant harm to our economies, as in some countries they may range up to 40% of the total electricity distributed. Detecting NTLs requires costly on-site inspections. Accurate prediction of NTLs for customers using machine learning is therefore crucial. To date, related research largely ignore that the two classes of regular and non-regular customers are highly imbalanced, that NTL proportions may change and mostly consider small data sets, often not allowing to deploy the results in production. In this paper, we present a comprehensive approach to assess three NTL detection models for different NTL proportions in large real world data sets of 100Ks of customers: Boolean rules, fuzzy logic and Support Vector Machine. This work has resulted in appreciable results that are about to be deployed in a leading industry solution. We believe that the considerations and observations made in this contribution are necessary for future smart meter research in order to report their effectiveness on imbalanced and large real world data sets.
Deep Convolutional Neural Networks for Smile Recognition
Aug 26, 2015

This thesis describes the design and implementation of a smile detector based on deep convolutional neural networks. It starts with a summary of neural networks, the difficulties of training them and new training methods, such as Restricted Boltzmann Machines or autoencoders. It then provides a literature review of convolutional neural networks and recurrent neural networks. In order to select databases for smile recognition, comprehensive statistics of databases popular in the field of facial expression recognition were generated and are summarized in this thesis. It then proposes a model for smile detection, of which the main part is implemented. The experimental results are discussed in this thesis and justified based on a comprehensive model selection performed. All experiments were run on a Tesla K40c GPU benefiting from a speedup of up to factor 10 over the computations on a CPU. A smile detection test accuracy of 99.45% is achieved for the Denver Intensity of Spontaneous Facial Action (DISFA) database, significantly outperforming existing approaches with accuracies ranging from 65.55% to 79.67%. This experiment is re-run under various variations, such as retaining less neutral images or only the low or high intensities, of which the results are extensively compared.
Comparison of Training Methods for Deep Neural Networks
Apr 26, 2015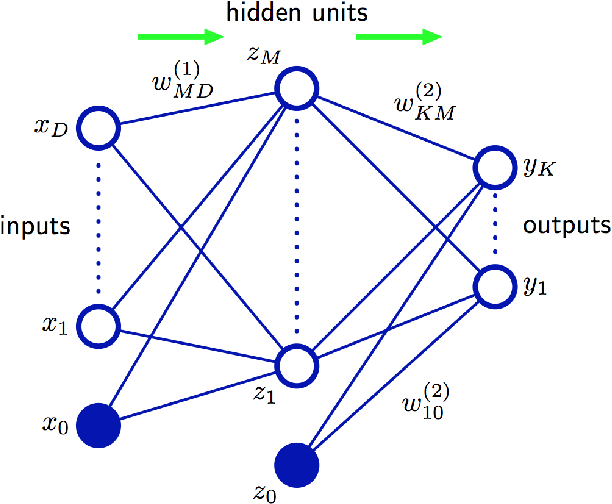
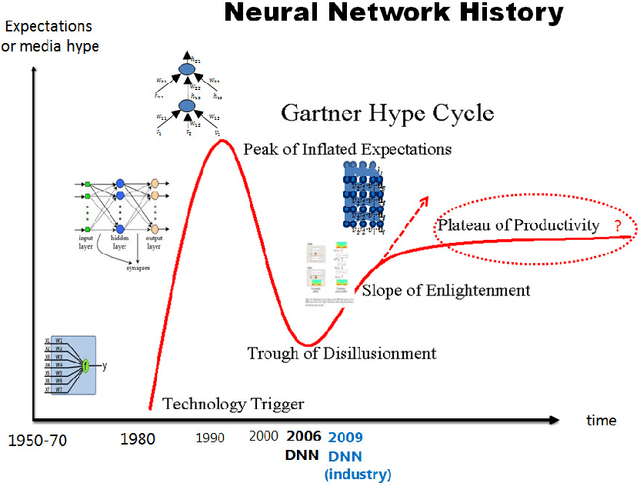
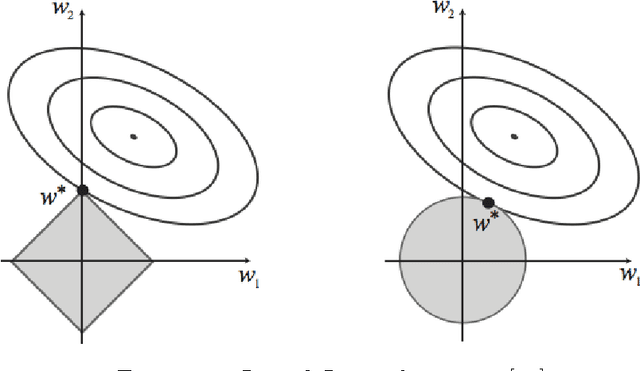
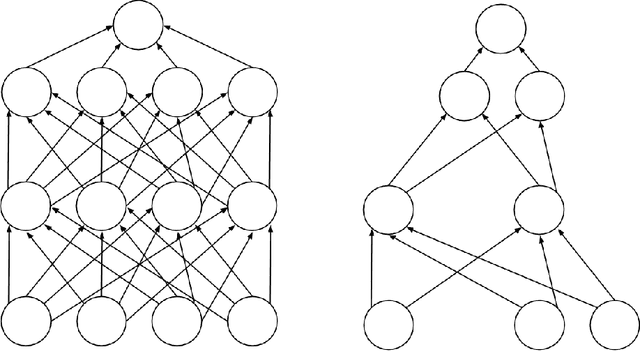
This report describes the difficulties of training neural networks and in particular deep neural networks. It then provides a literature review of training methods for deep neural networks, with a focus on pre-training. It focuses on Deep Belief Networks composed of Restricted Boltzmann Machines and Stacked Autoencoders and provides an outreach on further and alternative approaches. It also includes related practical recommendations from the literature on training them. In the second part, initial experiments using some of the covered methods are performed on two databases. In particular, experiments are performed on the MNIST hand-written digit dataset and on facial emotion data from a Kaggle competition. The results are discussed in the context of results reported in other research papers. An error rate lower than the best contribution to the Kaggle competition is achieved using an optimized Stacked Autoencoder.