 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Knowledge Improves Agentic LLM Workflows
Nov 10, 2025Large language models (LLMs) often struggle when performing agentic tasks without substantial tool support, prom-pt engineering, or fine tuning. Despite research showing that domain-dependent, procedural knowledge can dramatically increase planning efficiency, little work evaluates its potential for improving LLM performance on agentic tasks that may require implicit planning. We formalize, implement, and evaluate an agentic LLM workflow that leverages procedural knowledge in the form of a hierarchical task network (HTN). Empirical results of our implementation show that hand-coded HTNs can dramatically improve LLM performance on agentic tasks, and using HTNs can boost a 20b or 70b parameter LLM to outperform a much larger 120b parameter LLM baseline. Furthermore, LLM-created HTNs improve overall performance, though less so. The results suggest that leveraging expertise--from humans, documents, or LLMs--to curate procedural knowledge will become another important tool for improving LLM workflows.
HTN Plan Repair Algorithms Compared: Strengths and Weaknesses of Different Methods
Apr 22, 2025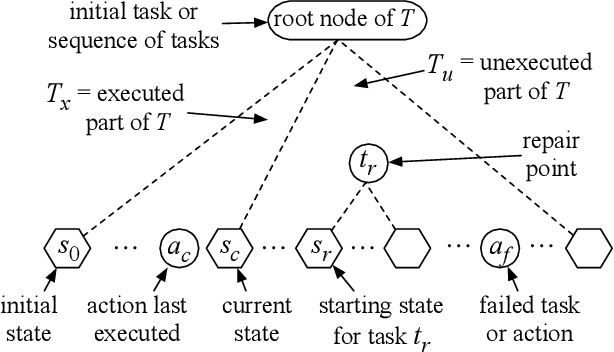

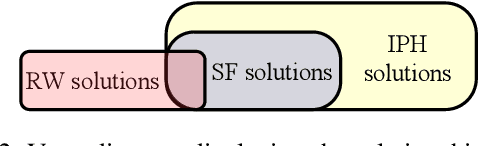

This paper provides theoretical and empirical comparisons of three recent hierarchical plan repair algorithms: SHOPFixer, IPyHOPPER, and Rewrite. Our theoretical results show that the three algorithms correspond to three different definitions of the plan repair problem, leading to differences in the algorithms' search spaces, the repair problems they can solve, and the kinds of repairs they can make. Understanding these distinctions is important when choosing a repair method for any given application. Building on the theoretical results, we evaluate the algorithms empirically in a series of benchmark planning problems. Our empirical results provide more detailed insight into the runtime repair performance of these systems and the coverage of the repair problems solved, based on algorithmic properties such as replanning, chronological backtracking, and backjumping over plan trees.
Automating Curriculum Learning for Reinforcement Learning using a Skill-Based Bayesian Network
Feb 21, 2025



A major challenge for reinforcement learning is automatically generating curricula to reduce training time or improve performance in some target task. We introduce SEBNs (Skill-Environment Bayesian Networks) which model a probabilistic relationship between a set of skills, a set of goals that relate to the reward structure, and a set of environment features to predict policy performance on (possibly unseen) tasks. We develop an algorithm that uses the inferred estimates of agent success from SEBN to weigh the possible next tasks by expected improvement. We evaluate the benefit of the resulting curriculum on three environments: a discrete gridworld, continuous control, and simulated robotics. The results show that curricula constructed using SEBN frequently outperform other baselines.
Composing Option Sequences by Adaptation: Initial Results
Sep 12, 2024



Robot manipulation in real-world settings often requires adapting the robot's behavior to the current situation, such as by changing the sequences in which policies execute to achieve the desired task. Problematically, however, we show that composing a novel sequence of five deep RL options to perform a pick-and-place task is unlikely to successfully complete, even if their initiation and termination conditions align. We propose a framework to determine whether sequences will succeed a priori, and examine three approaches that adapt options to sequence successfully if they will not. Crucially, our adaptation methods consider the actual subset of points that the option is trained from or where it ends: (1) trains the second option to start where the first ends; (2) trains the first option to reach the centroid of where the second starts; and (3) trains the first option to reach the median of where the second starts. Our results show that our framework and adaptation methods have promise in adapting options to work in novel sequences.
Towards Online Safety Corrections for Robotic Manipulation Policies
Sep 12, 2024Recent successes in applying reinforcement learning (RL) for robotics has shown it is a viable approach for constructing robotic controllers. However, RL controllers can produce many collisions in environments where new obstacles appear during execution. This poses a problem in safety-critical settings. We present a hybrid approach, called iKinQP-RL, that uses an Inverse Kinematics Quadratic Programming (iKinQP) controller to correct actions proposed by an RL policy at runtime. This ensures safe execution in the presence of new obstacles not present during training. Preliminary experiments illustrate our iKinQP-RL framework completely eliminates collisions with new obstacles while maintaining a high task success rate.
Automatically Learning HTN Methods from Landmarks
Apr 09, 2024Hierarchical Task Network (HTN) planning usually requires a domain engineer to provide manual input about how to decompose a planning problem. Even HTN-MAKER, a well-known method-learning algorithm, requires a domain engineer to annotate the tasks with information about what to learn. We introduce CURRICULAMA, an HTN method learning algorithm that completely automates the learning process. It uses landmark analysis to compose annotated tasks and leverages curriculum learning to order the learning of methods from simpler to more complex. This eliminates the need for manual input, resolving a core issue with HTN-MAKER. We prove CURRICULAMA's soundness, and show experimentally that it has a substantially similar convergence rate in learning a complete set of methods to HTN-MAKER.
Goal-Oriented End-User Programming of Robots
Mar 20, 2024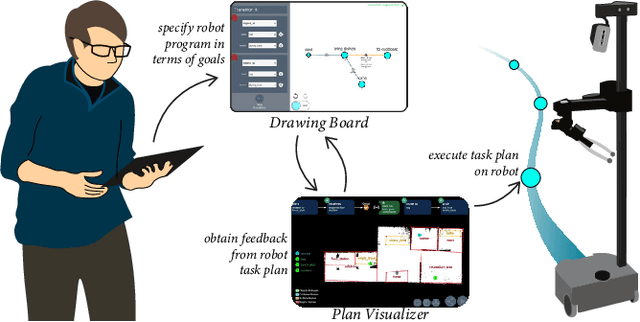
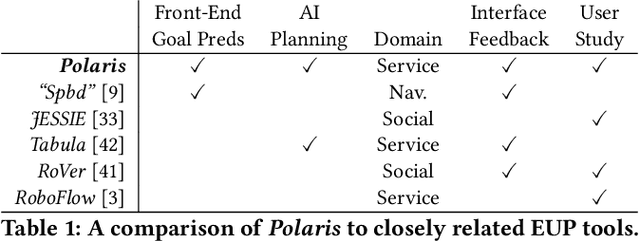

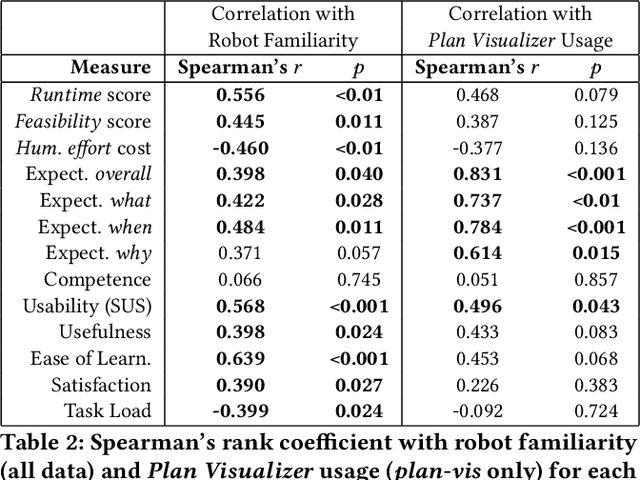
End-user programming (EUP) tools must balance user control with the robot's ability to plan and act autonomously. Many existing task-oriented EUP tools enforce a specific level of control, e.g., by requiring that users hand-craft detailed sequences of actions, rather than offering users the flexibility to choose the level of task detail they wish to express. We thereby created a novel EUP system, Polaris, that in contrast to most existing EUP tools, uses goal predicates as the fundamental building block of programs. Users can thereby express high-level robot objectives or lower-level checkpoints at their choosing, while an off-the-shelf task planner fills in any remaining program detail. To ensure that goal-specified programs adhere to user expectations of robot behavior, Polaris is equipped with a Plan Visualizer that exposes the planner's output to the user before runtime. In what follows, we describe our design of Polaris and its evaluation with 32 human participants. Our results support the Plan Visualizer's ability to help users craft higher-quality programs. Furthermore, there are strong associations between user perception of the robot and Plan Visualizer usage, and evidence that robot familiarity has a key role in shaping user experience.
Considerations for End-User Development in the Caregiving Domain
Feb 27, 2024
As service robots become more capable of autonomous behaviors, it becomes increasingly important to consider how people communicate with a robot what task it should perform and how to do the task. Accordingly, there has been a rise in attention to end-user development (EUD) interfaces, which enable non-roboticist end users to specify tasks for autonomous robots to perform. However, state-of-the-art EUD interfaces are often constrained through simplified domains or restrictive end-user interaction. Motivated by prior qualitative design work that explores how to integrate a care robot in an assisted living community, we discuss the challenges of EUD in this complex domain. One set of challenges stems from different user-facing representations, e.g., certain tasks may lend themselves better to rule-based trigger-action representations, whereas other tasks may be easier to specify via sequences of actions. The other stems from considering the needs of multiple stakeholders, e.g., caregivers and residents of the facility may all create tasks for the robot, but the robot may not be able to share information about all tasks with all residents due to privacy concerns. We present scenarios that illustrate these challenges and also discuss possible solutions.
New Horizons: Pioneering Pharmaceutical R&D with Generative AI from lab to the clinic -- an industry perspective
Dec 19, 2023The rapid advance of generative AI is reshaping the strategic vision for R&D across industries. The unique challenges of pharmaceutical R&D will see applications of generative AI deliver value along the entire value chain from early discovery to regulatory approval. This perspective reviews these challenges and takes a three-horizon approach to explore the generative AI applications already delivering impact, the disruptive opportunities which are just around the corner, and the longer-term transformation which will shape the future of the industry. Selected applications are reviewed for their potential to drive increase productivity, accelerate timelines, improve the quality of research, data and decision making, and support a sustainable future for the industry. Recommendations are given for Pharma R&D leaders developing a generative AI strategy today which will lay the groundwork for getting real value from the technology and safeguarding future growth. Generative AI is today providing new, efficient routes to accessing and combining organisational data to drive productivity. Next, this impact will reach clinical development, enhancing the patient experience, driving operational efficiency, and unlocking digital innovation to better tackle the future burden of disease. Looking to the furthest horizon, rapid acquisition of rich multi-omics data, which capture the 'language of life', in combination with next generation AI technologies will allow organisations to close the loop around phases of the pipeline through rapid, automated generation and testing of hypotheses from bench to bedside. This provides a vision for the future of R&D with sustainability at the core, with reduced timescales and reduced dependency on resources, while offering new hope to patients to treat the untreatable and ultimately cure diseases.
Understanding CNN Fragility When Learning With Imbalanced Data
Oct 17, 2022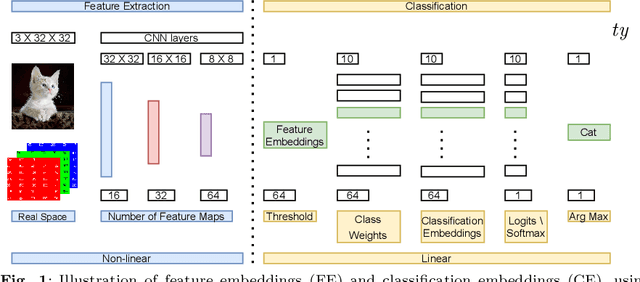
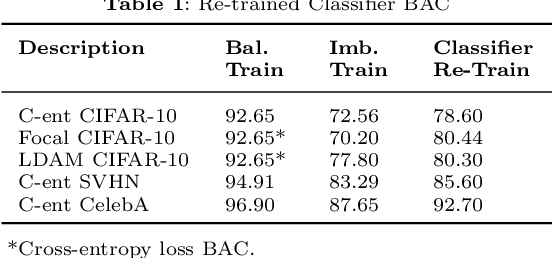
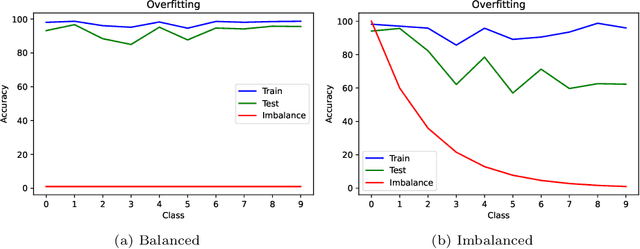
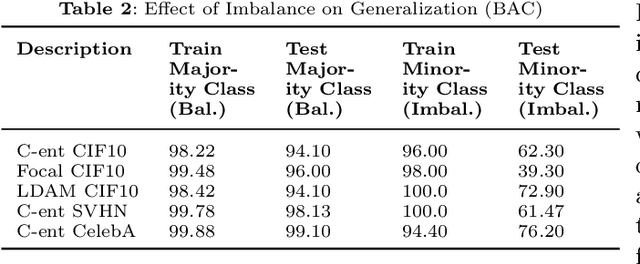
Convolutional neural networks (CNNs) have achieved impressive results on imbalanced image data, but they still have difficulty generalizing to minority classes and their decisions are difficult to interpret. These problems are related because the method by which CNNs generalize to minority classes, which requires improvement, is wrapped in a blackbox. To demystify CNN decisions on imbalanced data, we focus on their latent features. Although CNNs embed the pattern knowledge learned from a training set in model parameters, the effect of this knowledge is contained in feature and classification embeddings (FE and CE). These embeddings can be extracted from a trained model and their global, class properties (e.g., frequency, magnitude and identity) can be analyzed. We find that important information regarding the ability of a neural network to generalize to minority classes resides in the class top-K CE and FE. We show that a CNN learns a limited number of class top-K CE per category, and that their number and magnitudes vary based on whether the same class is balanced or imbalanced. This calls into question whether a CNN has learned intrinsic class features, or merely frequently occurring ones that happen to exist in the sampled class distribution. We also hypothesize that latent class diversity is as important as the number of class examples, which has important implications for re-sampling and cost-sensitive methods. These methods generally focus on rebalancing model weights, class numbers and margins; instead of diversifying class latent features through augmentation. We also demonstrate that a CNN has difficulty generalizing to test data if the magnitude of its top-K latent features do not match the training set. We use three popular image datasets and two cost-sensitive algorithms commonly employed in imbalanced learning for our experiments.