 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Drifting Data Streams on a Budget: Combining Active Learning with Self-Labeling
Dec 21, 2021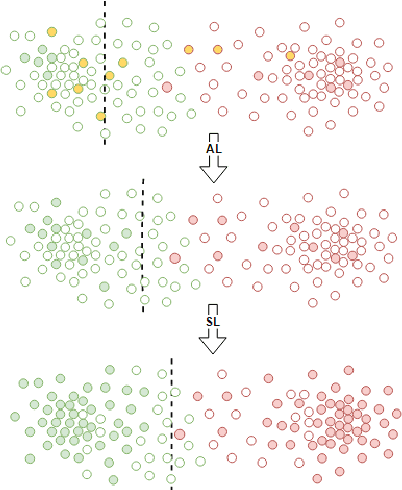
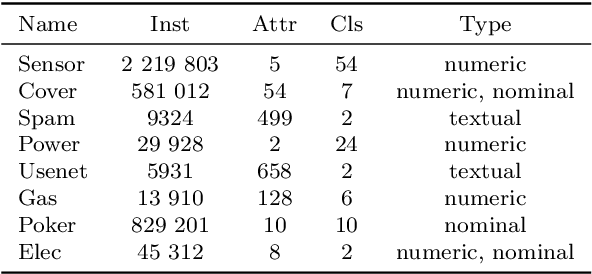
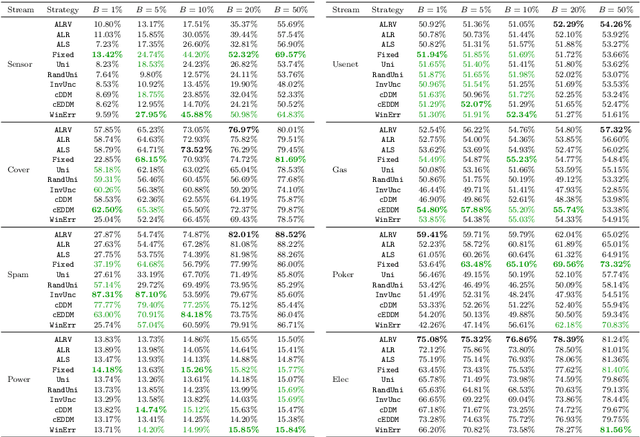
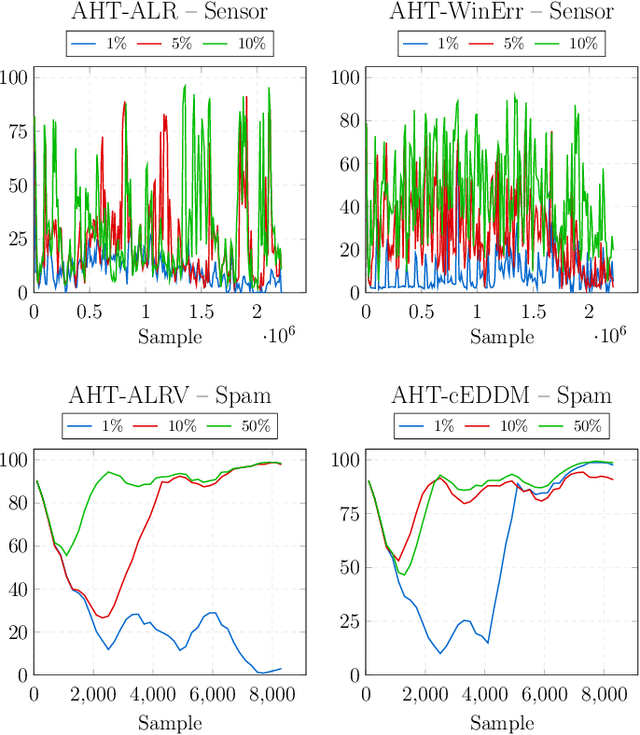
Mining data streams poses a number of challenges, including the continuous and non-stationary nature of data, the massive volume of information to be processed and constraints put on the computational resources. While there is a number of supervised solutions proposed for this problem in the literature, most of them assume that access to the ground truth (in form of class labels) is unlimited and such information can be instantly utilized when updating the learning system. This is far from being realistic, as one must consider the underlying cost of acquiring labels. Therefore, solutions that can reduce the requirements for ground truth in streaming scenarios are required. In this paper, we propose a novel framework for mining drifting data streams on a budget, by combining information coming from active learning and self-labeling. We introduce several strategies that can take advantage of both intelligent instance selection and semi-supervised procedures, while taking into account the potential presence of concept drift. Such a hybrid approach allows for efficient exploration and exploitation of streaming data structures within realistic labeling budgets. Since our framework works as a wrapper, it may be applied with different learning algorithms. Experimental study, carried out on a diverse set of real-world data streams with various types of concept drift, proves the usefulness of the proposed strategies when dealing with highly limited access to class labels. The presented hybrid approach is especially feasible when one cannot increase a budget for labeling or replace an inefficient classifier. We deliver a set of recommendations regarding areas of applicability for our strategies.
Class-Incremental Experience Replay for Continual Learning under Concept Drift
Apr 24, 2021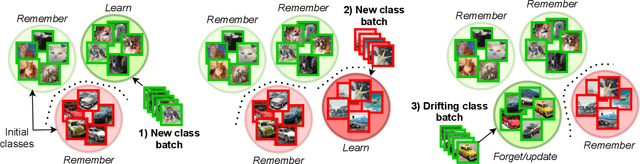
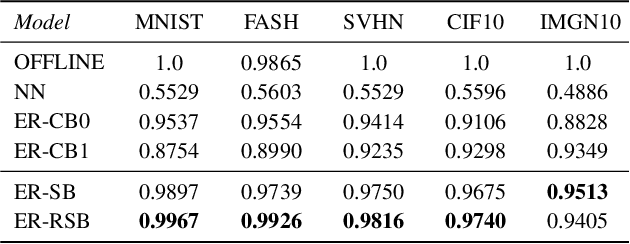

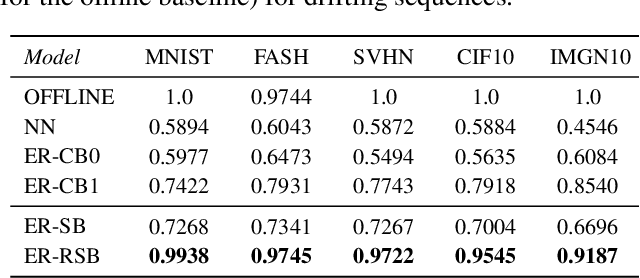
Modern machine learning systems need to be able to cope with constantly arriving and changing data. Two main areas of research dealing with such scenarios are continual learning and data stream mining. Continual learning focuses on accumulating knowledge and avoiding forgetting, assuming information once learned should be stored. Data stream mining focuses on adaptation to concept drift and discarding outdated information, assuming that only the most recent data is relevant. While these two areas are mainly being developed in separation, they offer complementary views on the problem of learning from dynamic data. There is a need for unifying them, by offering architectures capable of both learning and storing new information, as well as revisiting and adapting to changes in previously seen concepts. We propose a novel continual learning approach that can handle both tasks. Our experience replay method is fueled by a centroid-driven memory storing diverse instances of incrementally arriving classes. This is enhanced with a reactive subspace buffer that tracks concept drift occurrences in previously seen classes and adapts clusters accordingly. The proposed architecture is thus capable of both remembering valid and forgetting outdated information, offering a holistic framework for continual learning under concept drift.
Concept Drift Detection from Multi-Class Imbalanced Data Streams
Apr 20, 2021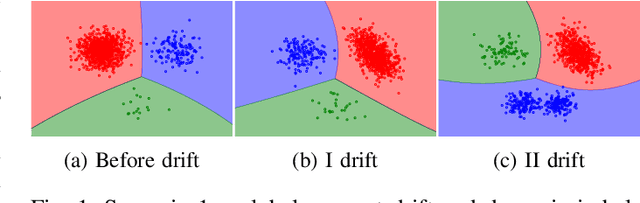

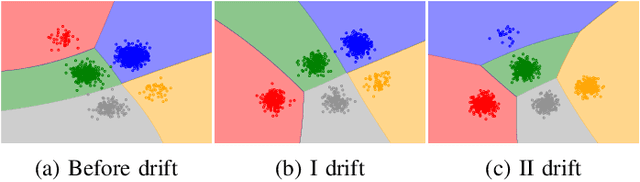
Continual learning from data streams is among the most important topics in contemporary machine learning. One of the biggest challenges in this domain lies in creating algorithms that can continuously adapt to arriving data. However, previously learned knowledge may become outdated, as streams evolve over time. This phenomenon is known as concept drift and must be detected to facilitate efficient adaptation of the learning model. While there exists a plethora of drift detectors, all of them assume that we are dealing with roughly balanced classes. In the case of imbalanced data streams, those detectors will be biased towards the majority classes, ignoring changes happening in the minority ones. Furthermore, class imbalance may evolve over time and classes may change their roles (majority becoming minority and vice versa). This is especially challenging in the multi-class setting, where relationships among classes become complex. In this paper, we propose a detailed taxonomy of challenges posed by concept drift in multi-class imbalanced data streams, as well as a novel trainable concept drift detector based on Restricted Boltzmann Machine. It is capable of monitoring multiple classes at once and using reconstruction error to detect changes in each of them independently. Our detector utilizes a skew-insensitive loss function that allows it to handle multiple imbalanced distributions. Due to its trainable nature, it is capable of following changes in a stream and evolving class roles, as well as it can deal with local concept drift occurring in minority classes. Extensive experimental study on multi-class drifting data streams, enriched with a detailed analysis of the impact of local drifts and changing imbalance ratios, confirms the high efficacy of our approach.
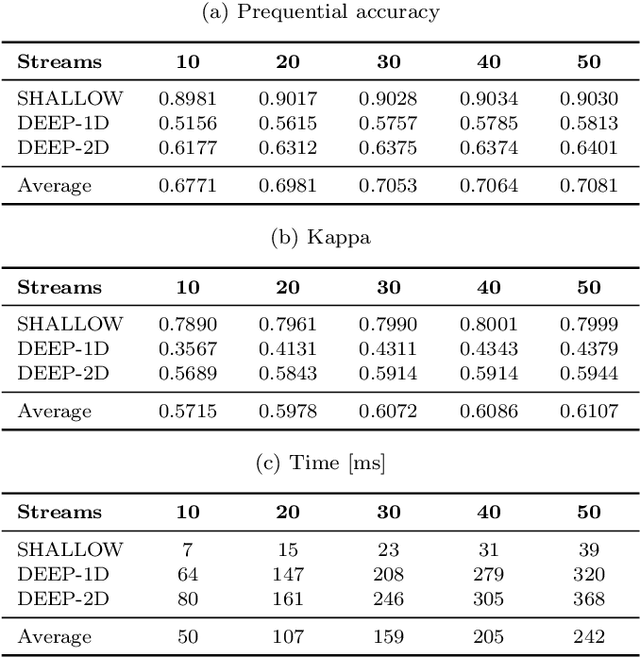
Adaptive Deep Forest for Online Learning from Drifting Data Streams
Oct 14, 2020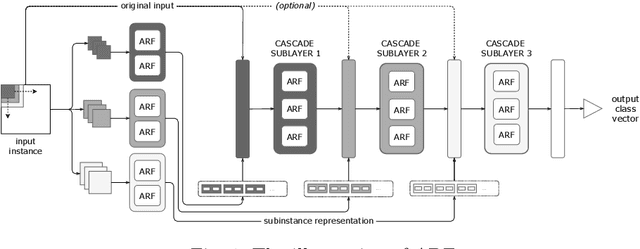
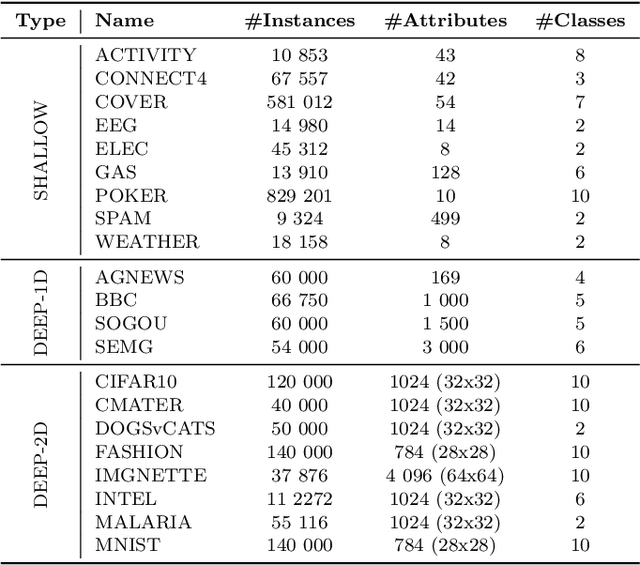
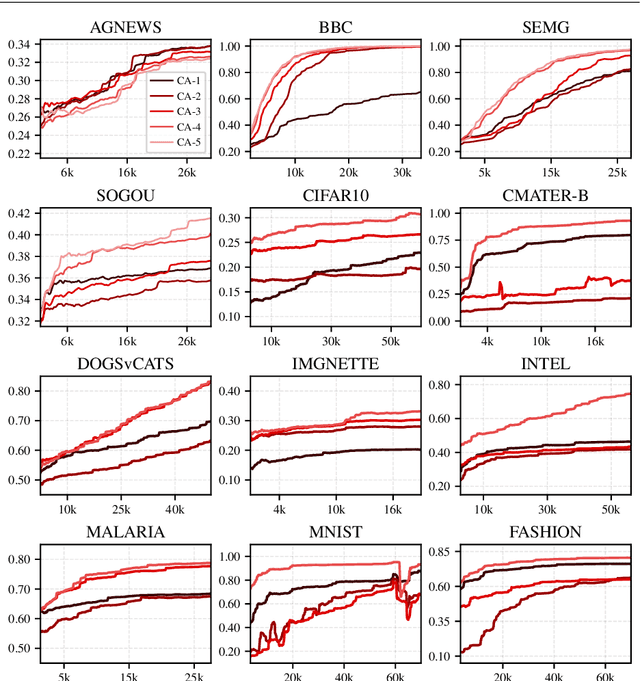
Learning from data streams is among the most vital fields of contemporary data mining. The online analysis of information coming from those potentially unbounded data sources allows for designing reactive up-to-date models capable of adjusting themselves to continuous flows of data. While a plethora of shallow methods have been proposed for simpler low-dimensional streaming problems, almost none of them addressed the issue of learning from complex contextual data, such as images or texts. The former is represented mainly by adaptive decision trees that have been proven to be very efficient in streaming scenarios. The latter has been predominantly addressed by offline deep learning. In this work, we attempt to bridge the gap between these two worlds and propose Adaptive Deep Forest (ADF) - a natural combination of the successful tree-based streaming classifiers with deep forest, which represents an interesting alternative idea for learning from contextual data. The conducted experiments show that the deep forest approach can be effectively transformed into an online algorithm, forming a model that outperforms all state-of-the-art shallow adaptive classifiers, especially for high-dimensional complex streams.
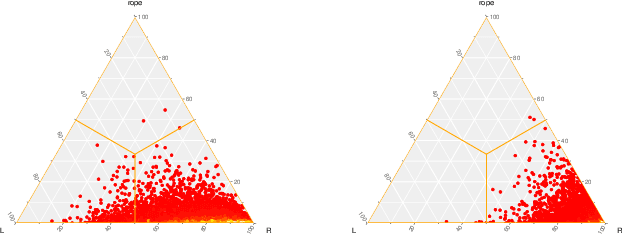
Adversarial Concept Drift Detection under Poisoning Attacks for Robust Data Stream Mining
Sep 20, 2020
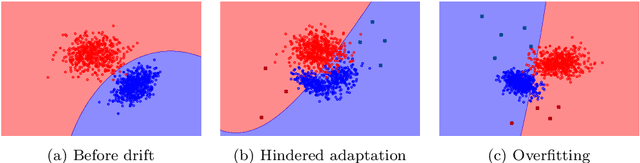
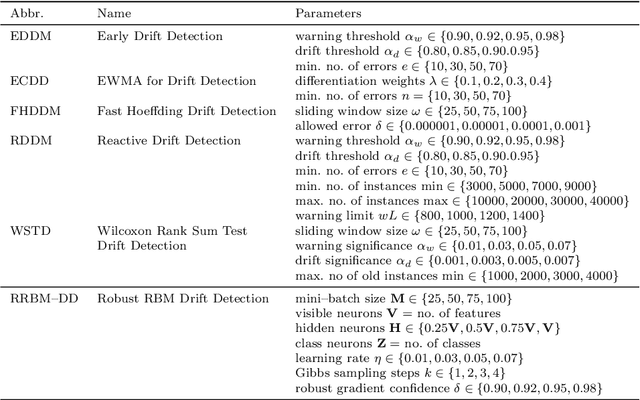
Continuous learning from streaming data is among the most challenging topics in the contemporary machine learning. In this domain, learning algorithms must not only be able to handle massive volumes of rapidly arriving data, but also adapt themselves to potential emerging changes. The phenomenon of the evolving nature of data streams is known as concept drift. While there is a plethora of methods designed for detecting its occurrence, all of them assume that the drift is connected with underlying changes in the source of data. However, one must consider the possibility of a malicious injection of false data that simulates a concept drift. This adversarial setting assumes a poisoning attack that may be conducted in order to damage the underlying classification system by forcing adaptation to false data. Existing drift detectors are not capable of differentiating between real and adversarial concept drift. In this paper, we propose a framework for robust concept drift detection in the presence of adversarial and poisoning attacks. We introduce the taxonomy for two types of adversarial concept drifts, as well as a robust trainable drift detector. It is based on the augmented Restricted Boltzmann Machine with improved gradient computation and energy function. We also introduce Relative Loss of Robustness - a novel measure for evaluating the performance of concept drift detectors under poisoning attacks. Extensive computational experiments, conducted on both fully and sparsely labeled data streams, prove the high robustness and efficacy of the proposed drift detection framework in adversarial scenarios.
Instance exploitation for learning temporary concepts from sparsely labeled drifting data streams
Sep 20, 2020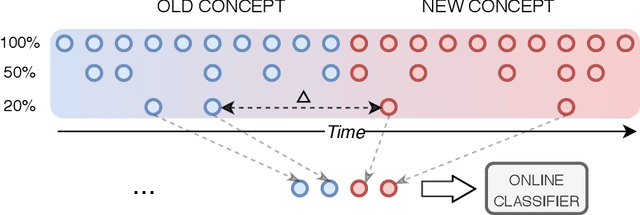
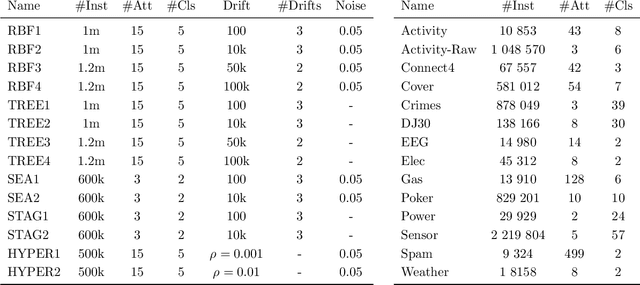
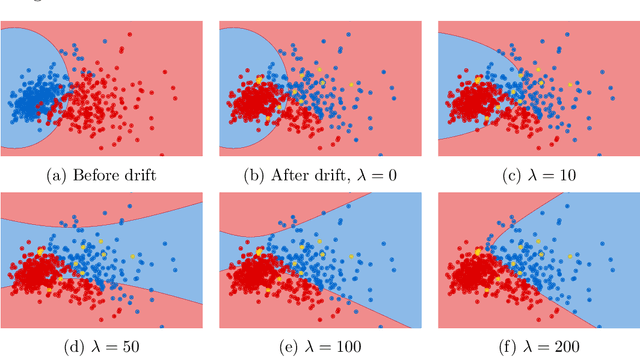

Continual learning from streaming data sources becomes more and more popular due to the increasing number of online tools and systems. Dealing with dynamic and everlasting problems poses new challenges for which traditional batch-based offline algorithms turn out to be insufficient in terms of computational time and predictive performance. One of the most crucial limitations is that we cannot assume having access to a finite and complete data set - we always have to be ready for new data that may complement our model. This poses a critical problem of providing labels for potentially unbounded streams. In the real world, we are forced to deal with very strict budget limitations, therefore, we will most likely face the scarcity of annotated instances, which are essential in supervised learning. In our work, we emphasize this problem and propose a novel instance exploitation technique. We show that when: (i) data is characterized by temporary non-stationary concepts, and (ii) there are very few labels spanned across a long time horizon, it is actually better to risk overfitting and adapt models more aggressively by exploiting the only labeled instances we have, instead of sticking to a standard learning mode and suffering from severe underfitting. We present different strategies and configurations for our methods, as well as an ensemble algorithm that attempts to maintain a sweet spot between risky and normal adaptation. Finally, we conduct a complex in-depth comparative analysis of our methods, using state-of-the-art streaming algorithms relevant to the given problem.