 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance exploitation for learning temporary concepts from sparsely labeled drifting data streams
Paper and Code
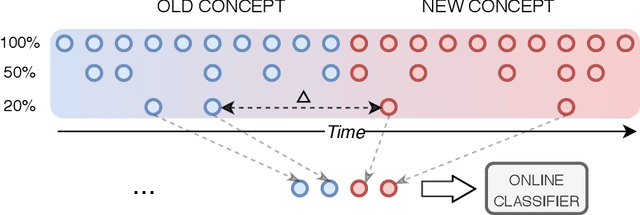
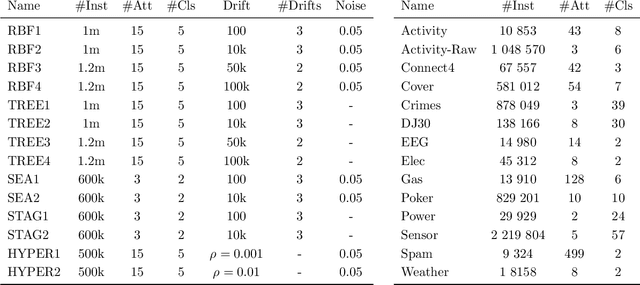
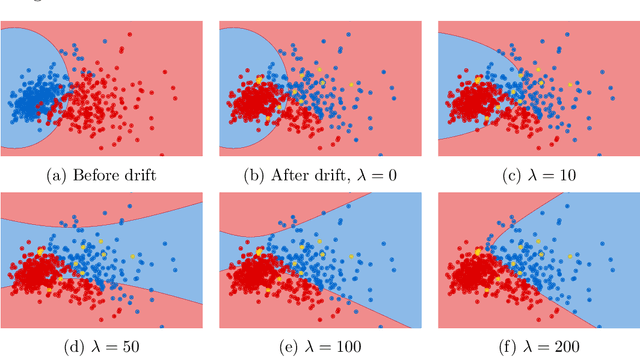

Continual learning from streaming data sources becomes more and more popular due to the increasing number of online tools and systems. Dealing with dynamic and everlasting problems poses new challenges for which traditional batch-based offline algorithms turn out to be insufficient in terms of computational time and predictive performance. One of the most crucial limitations is that we cannot assume having access to a finite and complete data set - we always have to be ready for new data that may complement our model. This poses a critical problem of providing labels for potentially unbounded streams. In the real world, we are forced to deal with very strict budget limitations, therefore, we will most likely face the scarcity of annotated instances, which are essential in supervised learning. In our work, we emphasize this problem and propose a novel instance exploitation technique. We show that when: (i) data is characterized by temporary non-stationary concepts, and (ii) there are very few labels spanned across a long time horizon, it is actually better to risk overfitting and adapt models more aggressively by exploiting the only labeled instances we have, instead of sticking to a standard learning mode and suffering from severe underfitting. We present different strategies and configurations for our methods, as well as an ensemble algorithm that attempts to maintain a sweet spot between risky and normal adaptation. Finally, we conduct a complex in-depth comparative analysis of our methods, using state-of-the-art streaming algorithms relevant to the given problem.