 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Embedding-based Attribution (LEA): Quantifying Source Contributions to Generative Model's Response for Vulnerability Analysis
Jun 12, 2025Security vulnerabilities are rapidly increasing in frequency and complexity, creating a shifting threat landscape that challenges cybersecurity defenses. Large Language Models (LLMs) have been widely adopted for cybersecurity threat analysis. When querying LLMs, dealing with new, unseen vulnerabilities is particularly challenging as it lies outside LLMs' pre-trained distribution. Retrieval-Augmented Generation (RAG) pipelines mitigate the problem by injecting up-to-date authoritative sources into the model context, thus reducing hallucinations and increasing the accuracy in responses. Meanwhile, the deployment of LLMs in security-sensitive environments introduces challenges around trust and safety. This raises a critical open question: How to quantify or attribute the generated response to the retrieved context versus the model's pre-trained knowledge? This work proposes LLM Embedding-based Attribution (LEA) -- a novel, explainable metric to paint a clear picture on the 'percentage of influence' the pre-trained knowledge vs. retrieved content has for each generated response. We apply LEA to assess responses to 100 critical CVEs from the past decade, verifying its effectiveness to quantify the insightfulness for vulnerability analysis. Our development of LEA reveals a progression of independency in hidden states of LLMs: heavy reliance on context in early layers, which enables the derivation of LEA; increased independency in later layers, which sheds light on why scale is essential for LLM's effectiveness. This work provides security analysts a means to audit LLM-assisted workflows, laying the groundwork for transparent, high-assurance deployments of RAG-enhanced LLMs in cybersecurity operations.
ProveRAG: Provenance-Driven Vulnerability Analysis with Automated Retrieval-Augmented LLMs
Oct 22, 2024
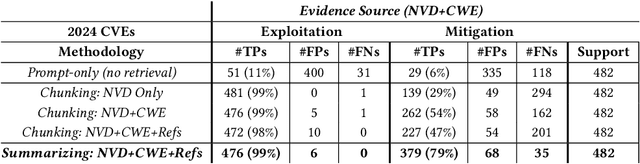
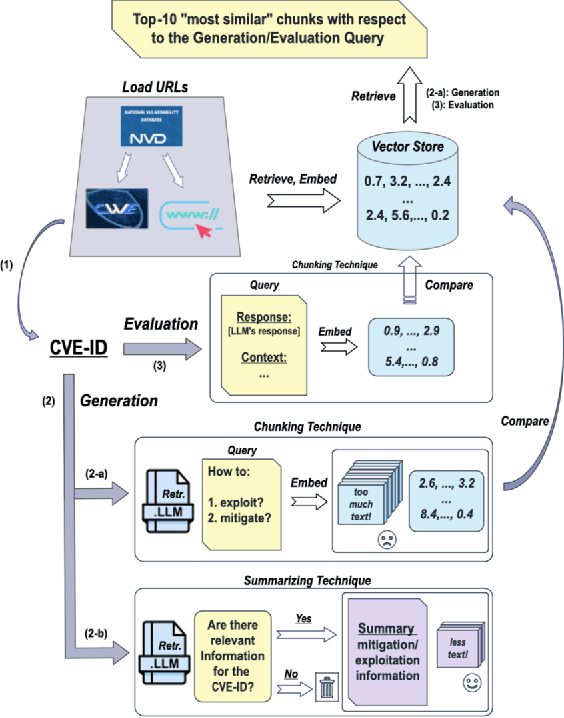

In cybersecurity, security analysts face the challenge of mitigating newly discovered vulnerabilities in real-time, with over 300,000 Common Vulnerabilities and Exposures (CVEs) identified since 1999. The sheer volume of known vulnerabilities complicates the detection of patterns for unknown threats. While LLMs can assist, they often hallucinate and lack alignment with recent threats. Over 25,000 vulnerabilities have been identified so far in 2024, which are introduced after popular LLMs' (e.g., GPT-4) training data cutoff. This raises a major challenge of leveraging LLMs in cybersecurity, where accuracy and up-to-date information are paramount. In this work, we aim to improve the adaptation of LLMs in vulnerability analysis by mimicking how analysts perform such tasks. We propose ProveRAG, an LLM-powered system designed to assist in rapidly analyzing CVEs with automated retrieval augmentation of web data while self-evaluating its responses with verifiable evidence. ProveRAG incorporates a self-critique mechanism to help alleviate omission and hallucination common in the output of LLMs applied in cybersecurity applications. The system cross-references data from verifiable sources (NVD and CWE), giving analysts confidence in the actionable insights provided. Our results indicate that ProveRAG excels in delivering verifiable evidence to the user with over 99% and 97% accuracy in exploitation and mitigation strategies, respectively. This system outperforms direct prompting and chunking retrieval in vulnerability analysis by overcoming temporal and context-window limitations. ProveRAG guides analysts to secure their systems more effectively while documenting the process for future audits.
Advancing TTP Analysis: Harnessing the Power of Encoder-Only and Decoder-Only Language Models with Retrieval Augmented Generation
Jan 12, 2024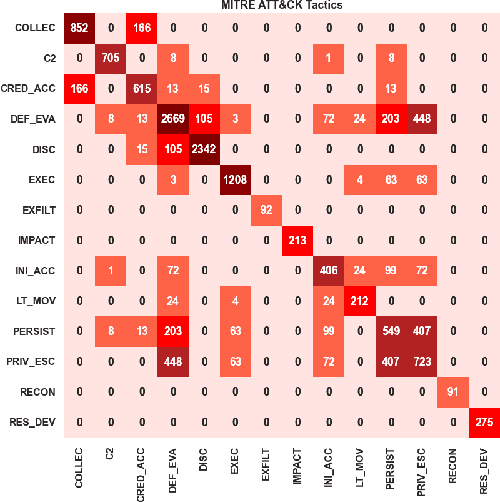
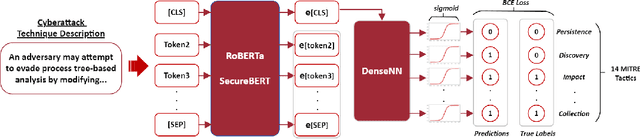
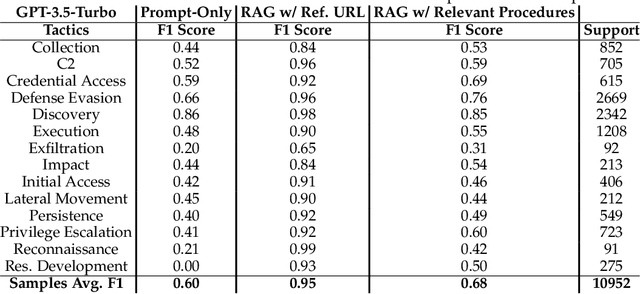

Tactics, Techniques, and Procedures (TTPs) outline the methods attackers use to exploit vulnerabilities. The interpretation of TTPs in the MITRE ATT&CK framework can be challenging for cybersecurity practitioners due to presumed expertise, complex dependencies, and inherent ambiguity. Meanwhile, advancements with Large Language Models (LLMs) have led to recent surge in studies exploring its uses in cybersecurity operations. This leads us to question how well encoder-only (e.g., RoBERTa) and decoder-only (e.g., GPT-3.5) LLMs can comprehend and summarize TTPs to inform analysts of the intended purposes (i.e., tactics) of a cyberattack procedure. The state-of-the-art LLMs have shown to be prone to hallucination by providing inaccurate information, which is problematic in critical domains like cybersecurity. Therefore, we propose the use of Retrieval Augmented Generation (RAG) techniques to extract relevant contexts for each cyberattack procedure for decoder-only LLMs (without fine-tuning). We further contrast such approach against supervised fine-tuning (SFT) of encoder-only LLMs. Our results reveal that both the direct-use of decoder-only LLMs (i.e., its pre-trained knowledge) and the SFT of encoder-only LLMs offer inaccurate interpretation of cyberattack procedures. Significant improvements are shown when RAG is used for decoder-only LLMs, particularly when directly relevant context is found. This study further sheds insights on the limitations and capabilities of using RAG for LLMs in interpreting TTPs.
On the Uses of Large Language Models to Interpret Ambiguous Cyberattack Descriptions
Jun 24, 2023The volume, variety, and velocity of change in vulnerabilities and exploits have made incident threat analysis challenging with human expertise and experience along. The MITRE AT&CK framework employs Tactics, Techniques, and Procedures (TTPs) to describe how and why attackers exploit vulnerabilities. However, a TTP description written by one security professional can be interpreted very differently by another, leading to confusion in cybersecurity operations or even business, policy, and legal decisions. Meanwhile, advancements in AI have led to the increasing use of Natural Language Processing (NLP) algorithms to assist the various tasks in cyber operations. With the rise of Large Language Models (LLMs), NLP tasks have significantly improved because of the LLM's semantic understanding and scalability. This leads us to question how well LLMs can interpret TTP or general cyberattack descriptions. We propose and analyze the direct use of LLMs as well as training BaseLLMs with ATT&CK descriptions to study their capability in predicting ATT&CK tactics. Our results reveal that the BaseLLMs with supervised training provide a more focused and clearer differentiation between the ATT&CK tactics (if such differentiation exists). On the other hand, LLMs offer a broader interpretation of cyberattack techniques. Despite the power of LLMs, inherent ambiguity exists within their predictions. We thus summarize the existing challenges and recommend research directions on LLMs to deal with the inherent ambiguity of TTP descriptions.