 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Road Object Importance Estimation: A New Dataset and A Model with Multi-Fold Top-Down Guidance
Paper and Code
Nov 26, 2024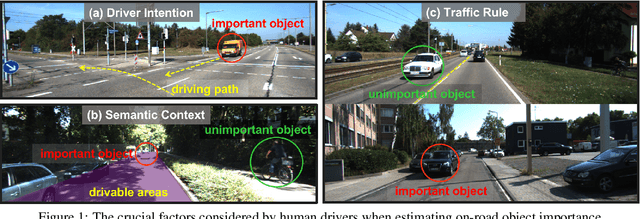

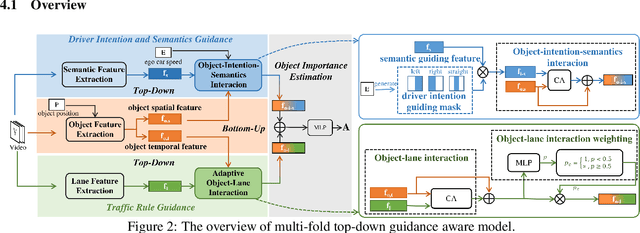
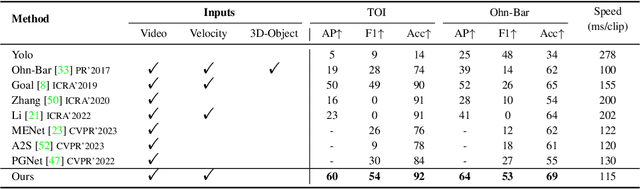
This paper addresses the problem of on-road object importance estimation, which utilizes video sequences captured from the driver's perspective as the input. Although this problem is significant for safer and smarter driving systems, the exploration of this problem remains limited. On one hand, publicly-available large-scale datasets are scarce in the community. To address this dilemma, this paper contributes a new large-scale dataset named Traffic Object Importance (TOI). On the other hand, existing methods often only consider either bottom-up feature or single-fold guidance, leading to limitations in handling highly dynamic and diverse traffic scenarios. Different from existing methods, this paper proposes a model that integrates multi-fold top-down guidance with the bottom-up feature. Specifically, three kinds of top-down guidance factors (ie, driver intention, semantic context, and traffic rule) are integrated into our model. These factors are important for object importance estimation, but none of the existing methods simultaneously consider them. To our knowledge, this paper proposes the first on-road object importance estimation model that fuses multi-fold top-down guidance factors with bottom-up feature. Extensive experiments demonstrate that our model outperforms state-of-the-art methods by large margins, achieving 23.1% Average Precision (AP) improvement compared with the recently proposed model (ie, Goal).