 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
Jun 17, 2026Unified Multimodal Modeling aims to integrate visual understanding and generation within a single system. However, existing approaches typically rely on two disparate visual tokenizers, which splits the representation space and hinders truly unified modeling. We propose UniAR, a unified autoregressive framework where a single discrete visual tokenizer serves as the key bridge between understanding and generation, enabling a shared context in which the model can directly interpret its own generated visual tokens without additional re-encoding. UniAR adapts a pretrained vision encoder with multi-level feature fusion and a lookup-free bitwise quantization scheme, preserving both high-level semantics and low-level details while scaling the effective visual vocabulary at minimal cost. Building on this, the unified autoregressive model adopts parallel-bitwise-prediction to jointly predict spatially grouped, multi-level visual codes, substantially reducing visual sequence length and accelerating generation. Finally, a diffusion-based visual decoder operates on discrete visual tokens to decode high-fidelity images. Through large-scale pre-training, followed by supervised fine-tuning and reinforcement learning, UniAR achieves state-of-the-art performance on image generation and image editing while remaining competitive on multimodal understanding benchmarks. The project page is available at https://sharelab-sii.github.io/uniar-web.
Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
Jun 10, 2026Spatial reasoning from egocentric videos is inherently challenging because the observable evidence is constrained by the camera trajectory. Existing methods rely on single-turn inference, forcing models to resolve geometric ambiguity through semantic priors rather than verifiable evidence. We argue that spatial reasoning should be revisitable: conclusions formed under limited evidence should remain open to revision when complementary viewpoints become available. Building on this insight, we propose Reason, then Re-reason (ReRe), a training-free, inference-time framework with two phases: in the Reason Phase, an MLLM forms a spatial hypothesis from the original video; in the Re-reason Phase, it verifies or revises the hypothesis by observing a synthesized novel-view video. To enable effective cross-view revisiting, we design a Geometry-to-Video pipeline that renders strategically complementary novel views from predicted 3D geometry. These views feature an elevated, oblique perspective with scene-spanning coverage, while preserving the MLLM's native video interface without architectural modifications. Extensive evaluations on VSI-Bench and STI-Bench demonstrate that ReRe substantially boosts open-source MLLMs to rival proprietary state-of-the-art performance. Project page: https://zhenjiemao.github.io/ReRe/
GenMask: Adapting DiT for Segmentation via Direct Mask
Mar 25, 2026Recent approaches for segmentation have leveraged pretrained generative models as feature extractors, treating segmentation as a downstream adaptation task via indirect feature retrieval. This implicit use suffers from a fundamental misalignment in representation. It also depends heavily on indirect feature extraction pipelines, which complicate the workflow and limit adaptation. In this paper, we argue that instead of indirect adaptation, segmentation tasks should be trained directly in a generative manner. We identify a key obstacle to this unified formulation: VAE latents of binary masks are sharply distributed, noise robust, and linearly separable, distinct from natural image latents. To bridge this gap, we introduce timesteps sampling strategy for binary masks that emphasizes extreme noise levels for segmentation and moderate noise for image generation, enabling harmonious joint training. We present GenMask, a DiT trains to generate black-and-white segmentation masks as well as colorful images in RGB space under the original generative objective. GenMask preserves the original DiT architecture while removing the need of feature extraction pipelines tailored for segmentation tasks. Empirically, GenMask attains state-of-the-art performance on referring and reasoning segmentation benchmarks and ablations quantify the contribution of each component.
ReMamber: Referring Image Segmentation with Mamba Twister
Mar 26, 2024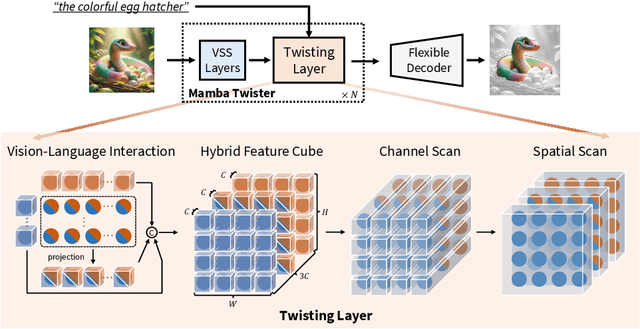
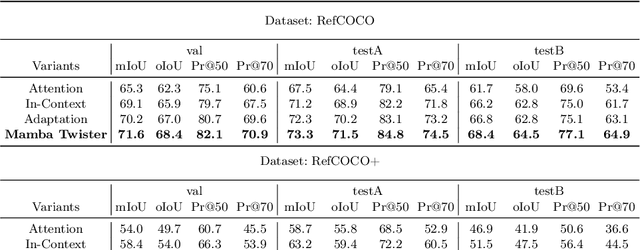
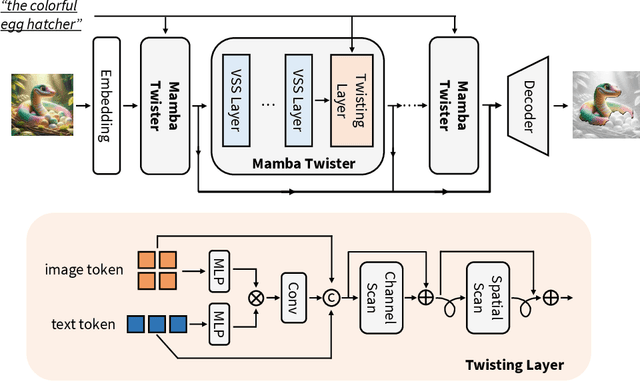
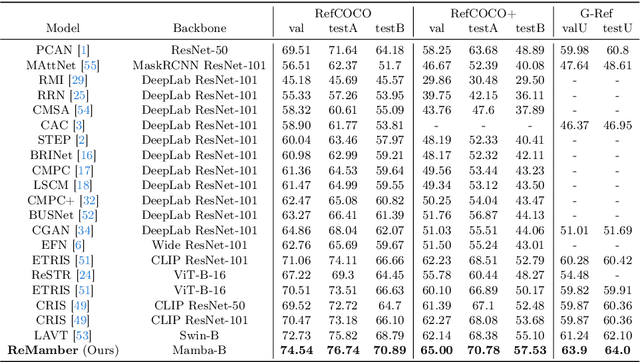
Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it resource-consuming in capturing long-range visual-language dependencies. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose ReMamber, a novel RIS architecture that integrates the power of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve the state-of-the-art on three challenging benchmarks. Moreover, we conduct thorough analyses of ReMamber and discuss other fusion designs using Mamba. These provide valuable perspectives for future research.
Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation
Aug 31, 2023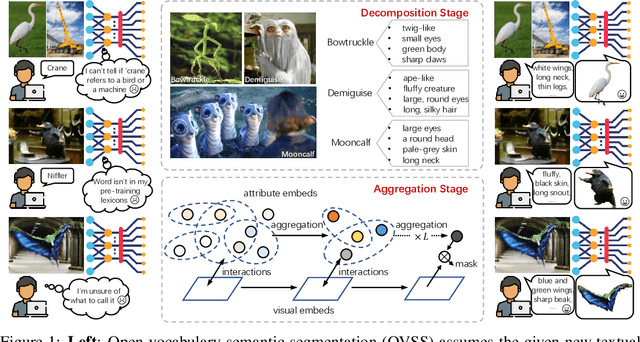


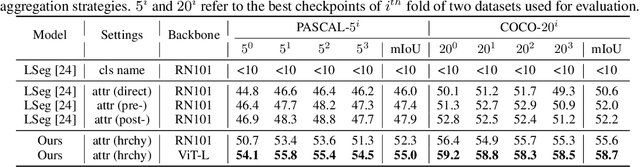
Open-vocabulary semantic segmentation is a challenging task that requires segmenting novel object categories at inference time. Recent works explore vision-language pre-training to handle this task, but suffer from unrealistic assumptions in practical scenarios, i.e., low-quality textual category names. For example, this paradigm assumes that new textual categories will be accurately and completely provided, and exist in lexicons during pre-training. However, exceptions often happen when meet with ambiguity for brief or incomplete names, new words that are not present in the pre-trained lexicons, and difficult-to-describe categories for users. To address these issues, this work proposes a novel decomposition-aggregation framework, inspired by human cognition in understanding new concepts. Specifically, in the decomposition stage, we decouple class names into diverse attribute descriptions to enrich semantic contexts. Two attribute construction strategies are designed: using large language models for common categories, and involving manually labelling for human-invented categories. In the aggregation stage, we group diverse attributes into an integrated global description, to form a discriminative classifier that distinguishes the target object from others. One hierarchical aggregation is further designed to achieve multi-level alignment and deep fusion between vision and text. The final result is obtained by computing the embedding similarity between aggregated attributes and images. To evaluate the effectiveness, we annotate three datasets with attribute descriptions, and conduct extensive experiments and ablation studies. The results show the superior performance of attribute decomposition-aggregation.
Multi-Modal Prototypes for Open-Set Semantic Segmentation
Jul 05, 2023In semantic segmentation, adapting a visual system to novel object categories at inference time has always been both valuable and challenging. To enable such generalization, existing methods rely on either providing several support examples as visual cues or class names as textual cues. Through the development is relatively optimistic, these two lines have been studied in isolation, neglecting the complementary intrinsic of low-level visual and high-level language information. In this paper, we define a unified setting termed as open-set semantic segmentation (O3S), which aims to learn seen and unseen semantics from both visual examples and textual names. Our pipeline extracts multi-modal prototypes for segmentation task, by first single modal self-enhancement and aggregation, then multi-modal complementary fusion. To be specific, we aggregate visual features into several tokens as visual prototypes, and enhance the class name with detailed descriptions for textual prototype generation. The two modalities are then fused to generate multi-modal prototypes for final segmentation. On both \pascal and \coco datasets, we conduct extensive experiments to evaluate the framework effectiveness. State-of-the-art results are achieved even on more detailed part-segmentation, Pascal-Animals, by only training on coarse-grained datasets. Thorough ablation studies are performed to dissect each component, both quantitatively and qualitatively.
DiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Mar 17, 2023
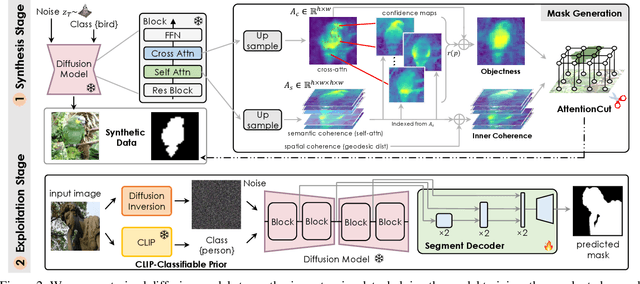


Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.
Open-vocabulary Semantic Segmentation with Frozen Vision-Language Models
Oct 27, 2022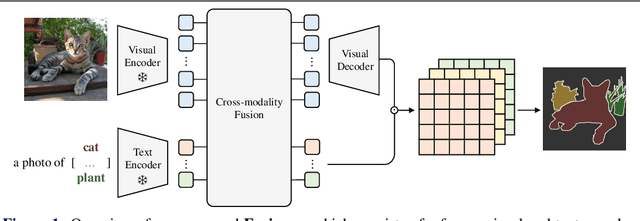
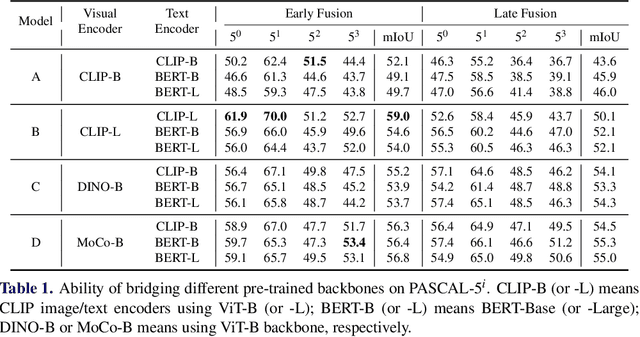
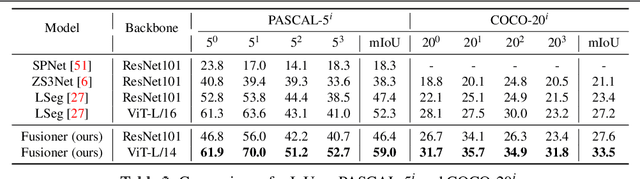
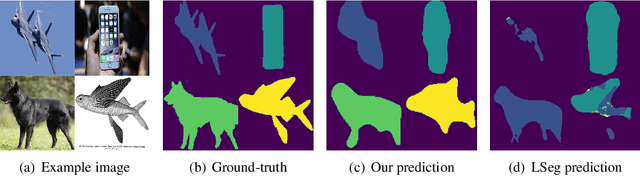
When trained at a sufficient scale, self-supervised learning has exhibited a notable ability to solve a wide range of visual or language understanding tasks. In this paper, we investigate simple, yet effective approaches for adapting the pre-trained foundation models to the downstream task of interest, namely, open-vocabulary semantic segmentation. To this end, we make the following contributions: (i) we introduce Fusioner, with a lightweight, transformer-based fusion module, that pairs the frozen visual representation with language concept through a handful of image segmentation data. As a consequence, the model gains the capability of zero-shot transfer to segment novel categories; (ii) without loss of generality, we experiment on a broad range of self-supervised models that have been pre-trained with different schemes, e.g. visual-only models (MoCo v3, DINO), language-only models (BERT), visual-language model (CLIP), and show that, the proposed fusion approach is effective to any pair of visual and language models, even those pre-trained on a corpus of uni-modal data; (iii) we conduct thorough ablation studies to analyze the critical components in our proposed Fusioner, while evaluating on standard benchmarks, e.g. PASCAL-5i and COCO-20i , it surpasses existing state-of-the-art models by a large margin, despite only being trained on frozen visual and language features; (iv) to measure the model's robustness on learning visual-language correspondence, we further evaluate on synthetic dataset, named Mosaic-4, where images are constructed by mosaicking the samples from FSS-1000. Fusioner demonstrates superior performance over previous models.
Transforming the Interactive Segmentation for Medical Imaging
Aug 20, 2022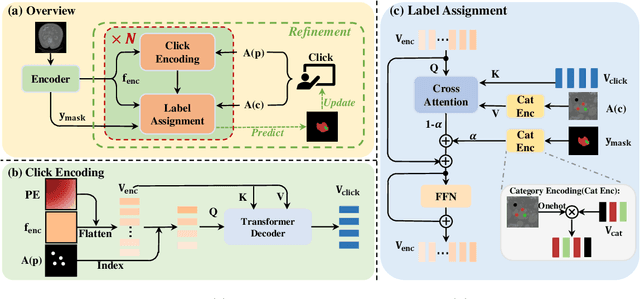
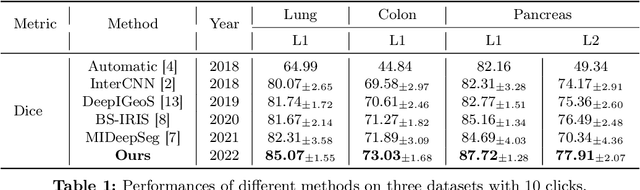
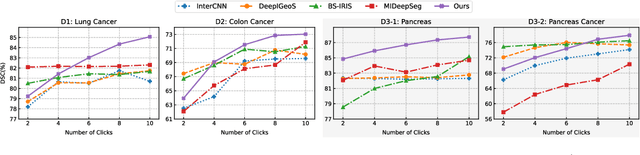

The goal of this paper is to interactively refine the automatic segmentation on challenging structures that fall behind human performance, either due to the scarcity of available annotations or the difficulty nature of the problem itself, for example, on segmenting cancer or small organs. Specifically, we propose a novel Transformer-based architecture for Interactive Segmentation (TIS), that treats the refinement task as a procedure for grouping pixels with similar features to those clicks given by the end users. Our proposed architecture is composed of Transformer Decoder variants, which naturally fulfills feature comparison with the attention mechanisms. In contrast to existing approaches, our proposed TIS is not limited to binary segmentations, and allows the user to edit masks for arbitrary number of categories. To validate the proposed approach, we conduct extensive experiments on three challenging datasets and demonstrate superior performance over the existing state-of-the-art methods. The project page is: https://wtliu7.github.io/tis/.