 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMamber: Referring Image Segmentation with Mamba Twister
Paper and Code
Mar 26, 2024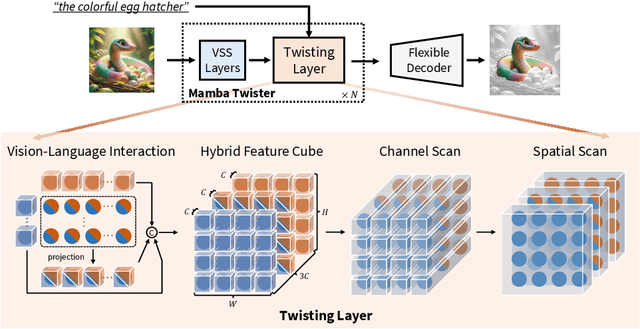
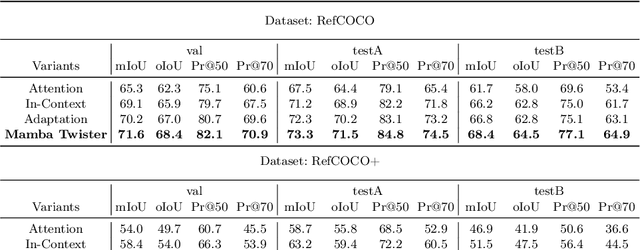
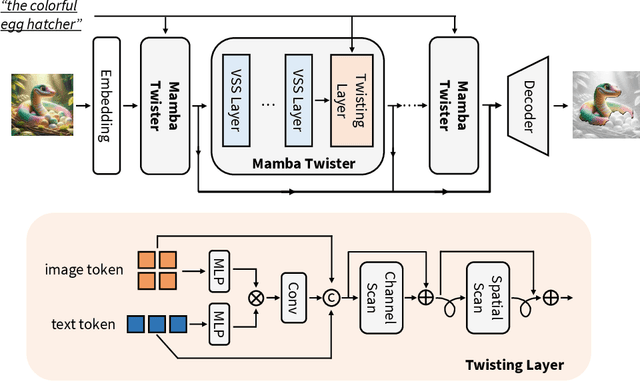
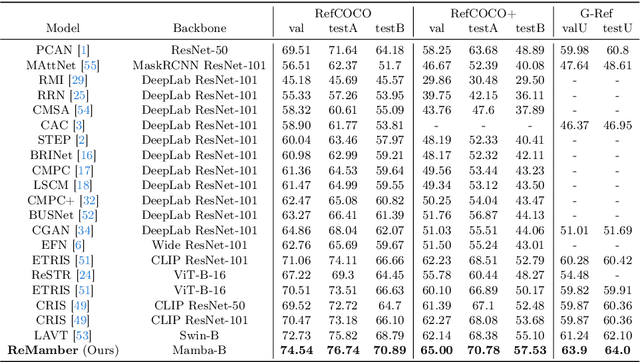
Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it resource-consuming in capturing long-range visual-language dependencies. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose ReMamber, a novel RIS architecture that integrates the power of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve the state-of-the-art on three challenging benchmarks. Moreover, we conduct thorough analyses of ReMamber and discuss other fusion designs using Mamba. These provide valuable perspectives for future research.