 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Masks for Efficient Image Super-Resolution
Paper and Code
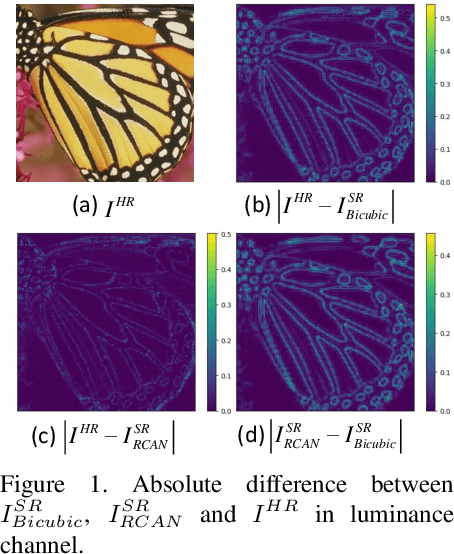
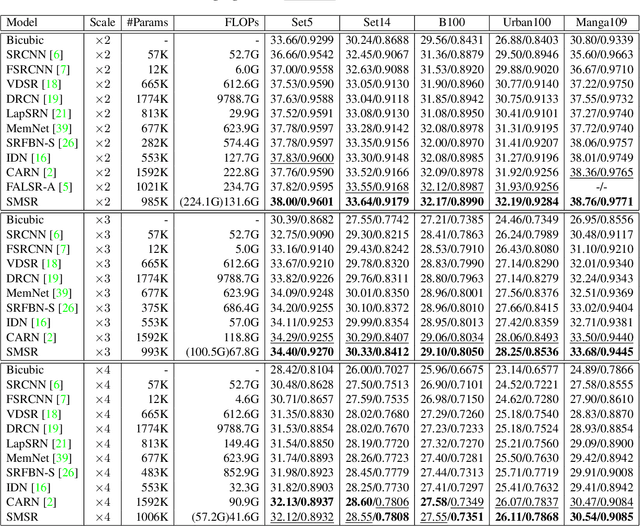
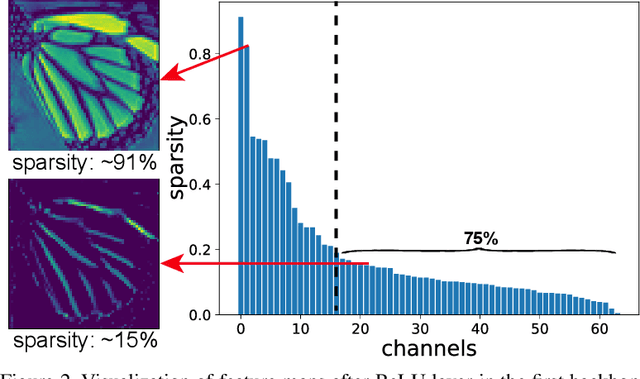

Current CNN-based super-resolution (SR) methods process all locations equally with computational resources being uniformly assigned in space. However, since highfrequency details mainly lie around edges and textures, less computational resources are required for those flat regions. Therefore, existing CNN-based methods involve much redundant computation in flat regions, which increases their computational cost and limits the applications on mobile devices. To address this limitation, we develop an SR network (SMSR) to learn sparse masks to prune redundant computation conditioned on the input image. Within our SMSR, spatial masks learn to identify "important" locations while channel masks learn to mark redundant channels in those "unimportant" regions. Consequently, redundant computation can be accurately located and skipped while maintaining comparable performance. It is demonstrated that our SMSR achieves state-of-the-art performance with 41%/33%/27% FLOPs being reduced for x2/3/4 SR.