 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Smart, Not Hard: Difficulty Adaptive Reasoning for Large Audio Language Models
Sep 26, 2025Large Audio Language Models (LALMs), powered by the chain-of-thought (CoT) paradigm, have shown remarkable reasoning capabilities. Intuitively, different problems often require varying depths of reasoning. While some methods can determine whether to reason for a given problem, they typically lack a fine-grained mechanism to modulate how much to reason. This often results in a ``one-size-fits-all'' reasoning depth, which generates redundant overthinking for simple questions while failing to allocate sufficient thought to complex ones. In this paper, we conduct an in-depth analysis of LALMs and find that an effective and efficient LALM should reason smartly by adapting its reasoning depth to the problem's complexity. To achieve this, we propose a difficulty-adaptive reasoning method for LALMs. Specifically, we propose a reward function that dynamically links reasoning length to the model's perceived problem difficulty. This reward encourages shorter, concise reasoning for easy tasks and more elaborate, in-depth reasoning for complex ones. Extensive experiments demonstrate that our method is both effective and efficient, simultaneously improving task performance and significantly reducing the average reasoning length. Further analysis on reasoning structure paradigm offers valuable insights for future work.
JiuZhang3.0: Efficiently Improving Mathematical Reasoning by Training Small Data Synthesis Models
May 23, 2024Mathematical reasoning is an important capability of large language models~(LLMs) for real-world applications. To enhance this capability, existing work either collects large-scale math-related texts for pre-training, or relies on stronger LLMs (\eg GPT-4) to synthesize massive math problems. Both types of work generally lead to large costs in training or synthesis. To reduce the cost, based on open-source available texts, we propose an efficient way that trains a small LLM for math problem synthesis, to efficiently generate sufficient high-quality pre-training data. To achieve it, we create a dataset using GPT-4 to distill its data synthesis capability into the small LLM. Concretely, we craft a set of prompts based on human education stages to guide GPT-4, to synthesize problems covering diverse math knowledge and difficulty levels. Besides, we adopt the gradient-based influence estimation method to select the most valuable math-related texts. The both are fed into GPT-4 for creating the knowledge distillation dataset to train the small LLM. We leverage it to synthesize 6 million math problems for pre-training our JiuZhang3.0 model, which only needs to invoke GPT-4 API 9.3k times and pre-train on 4.6B data. Experimental results have shown that JiuZhang3.0 achieves state-of-the-art performance on several mathematical reasoning datasets, under both natural language reasoning and tool manipulation settings. Our code and data will be publicly released in \url{https://github.com/RUCAIBox/JiuZhang3.0}.
Spelling Error Correction Using a Nested RNN Model and Pseudo Training Data
Nov 01, 2018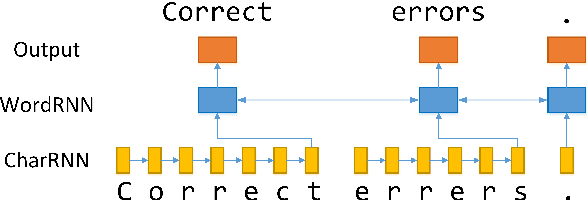

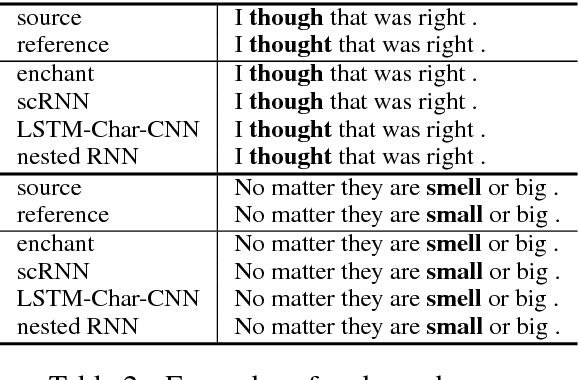
We propose a nested recurrent neural network (nested RNN) model for English spelling error correction and generate pseudo data based on phonetic similarity to train it. The model fuses orthographic information and context as a whole and is trained in an end-to-end fashion. This avoids feature engineering and does not rely on a noisy channel model as in traditional methods. Experiments show that the proposed method is superior to existing systems in correcting spelling errors.