 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPool: A Globally Shared Expert Pool for Mixture-of-Experts
May 07, 2026Modern Mixture-of-Experts (MoE) architectures allocate expert capacity through a rigid per-layer rule: each transformer layer owns a separate expert set. This convention couples depth scaling with linear expert-parameter growth and assumes that every layer needs isolated expert capacity. However, recent analyses and our routing probe challenge this allocation rule: replacing a deeper layer's learned top-k router with uniform random routing drops downstream accuracy by only 1.0-1.6 points across multiple production MoE models. Motivated by this redundancy, we propose UniPool, an MoE architecture that treats expert capacity as a global architectural budget by replacing per-layer expert ownership with a single shared pool accessed by independent per-layer routers. To enable stable and balanced training under sharing, we introduce a pool-level auxiliary loss that balances expert utilization across the entire pool, and adopt NormRouter to provide sparse and scale-stable routing into the shared expert pool. Across five LLaMA-architecture model scales (182M, 469M, 650M, 830M, and 978M parameters) trained on 30B tokens from the Pile, UniPool consistently improves validation loss and perplexity over the matched vanilla MoE baselines. Across these scales, UniPool reduces validation loss by up to 0.0386 relative to vanilla MoE. Beyond raw loss improvement, our results identify pool size as an explicit depth-scaling hyperparameter: reduced-pool UniPool variants using only 41.6%-66.7% of the vanilla expert-parameter budget match or outperform layer-wise MoE at the tested scales. This shows that, under a shared-pool design, expert parameters need not grow linearly with depth; they can grow sublinearly while remaining more efficient and effective than vanilla MoE. Further analysis shows that UniPool's benefits compose with finer-grained expert decomposition.
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Scaling Law for Language Models Training Considering Batch Size
Dec 02, 2024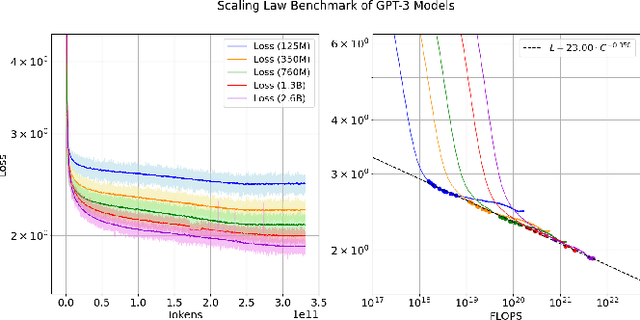
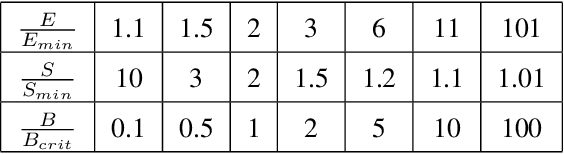

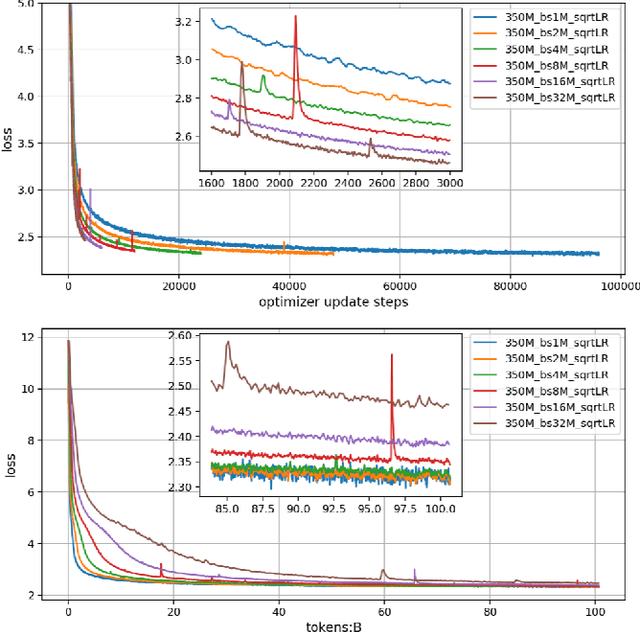
Large language models (LLMs) have made remarkable advances in recent years, with scaling laws playing a critical role in this rapid progress. In this paper, we empirically investigate how a critical hyper-parameter, i.e., the global batch size, influences the LLM training prdocess. We begin by training language models ranging from 125 million to 2.6 billion parameters, using up to 300 billion high-quality tokens. Through these experiments, we establish a basic scaling law on model size and training data amount. We then examine how varying batch sizes and learning rates affect the convergence and generalization of these models. Our analysis yields batch size scaling laws under two different cases: with a fixed compute budget, and with a fixed amount of training data. Extrapolation experiments on models of increasing sizes validate our predicted laws, which provides guidance for optimizing LLM training strategies under specific resource constraints.
ParaLBench: A Large-Scale Benchmark for Computational Paralinguistics over Acoustic Foundation Models
Nov 14, 2024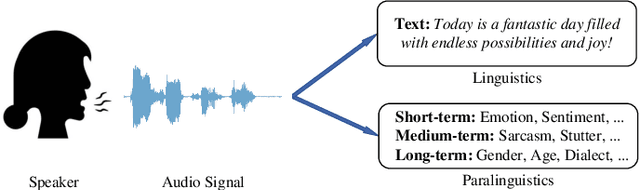
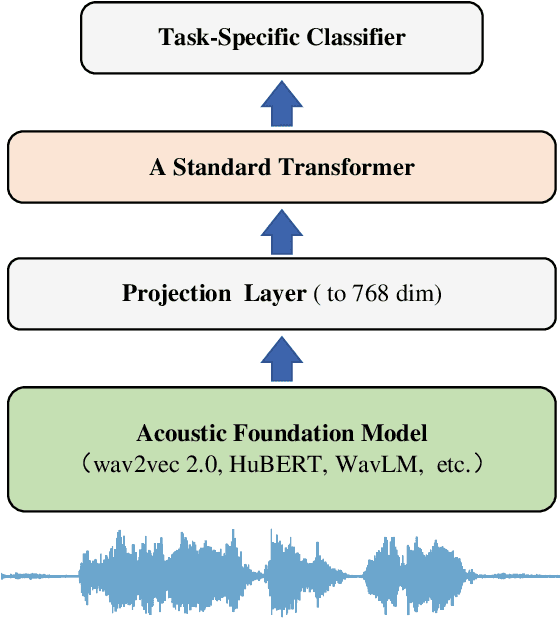
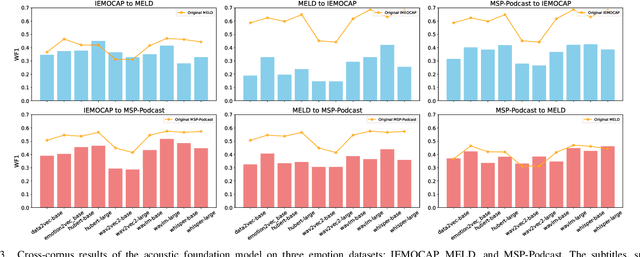
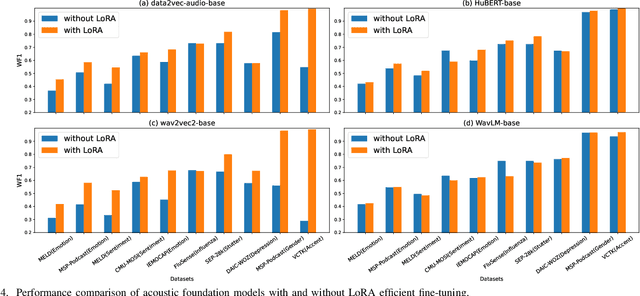
Computational paralinguistics (ComParal) aims to develop algorithms and models to automatically detect, analyze, and interpret non-verbal information from speech communication, e. g., emotion, health state, age, and gender. Despite its rapid progress, it heavily depends on sophisticatedly designed models given specific paralinguistic tasks. Thus, the heterogeneity and diversity of ComParal models largely prevent the realistic implementation of ComParal models. Recently, with the advent of acoustic foundation models because of self-supervised learning, developing more generic models that can efficiently perceive a plethora of paralinguistic information has become an active topic in speech processing. However, it lacks a unified evaluation framework for a fair and consistent performance comparison. To bridge this gap, we conduct a large-scale benchmark, namely ParaLBench, which concentrates on standardizing the evaluation process of diverse paralinguistic tasks, including critical aspects of affective computing such as emotion recognition and emotion dimensions prediction, over different acoustic foundation models. This benchmark contains ten datasets with thirteen distinct paralinguistic tasks, covering short-, medium- and long-term characteristics. Each task is carried out on 14 acoustic foundation models under a unified evaluation framework, which allows for an unbiased methodological comparison and offers a grounded reference for the ComParal community. Based on the insights gained from ParaLBench, we also point out potential research directions, i.e., the cross-corpus generalizability, to propel ComParal research in the future. The code associated with this study will be available to foster the transparency and replicability of this work for succeeding researchers.
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023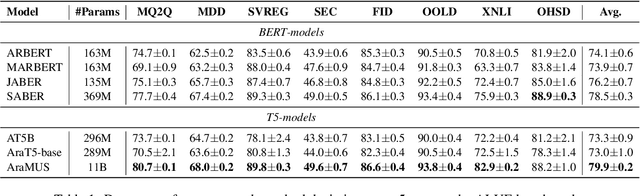



Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
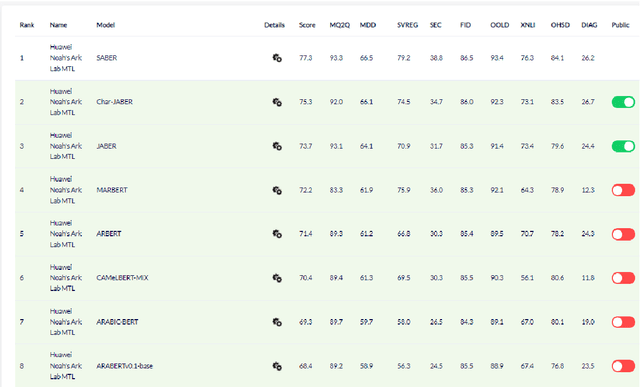

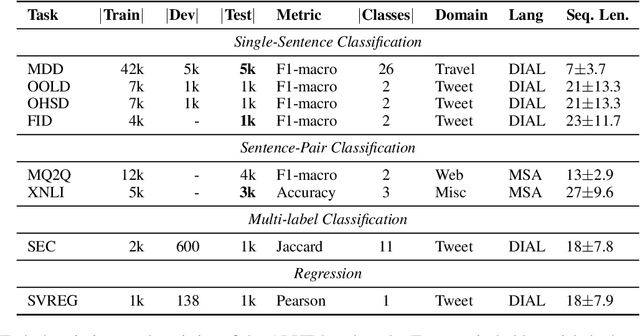
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022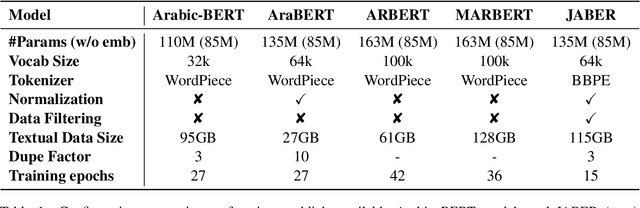
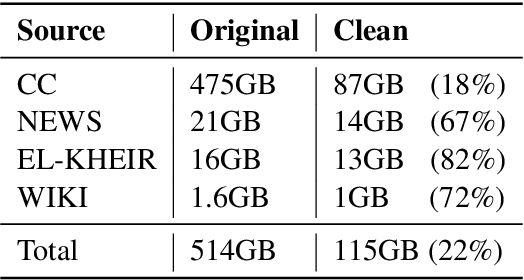
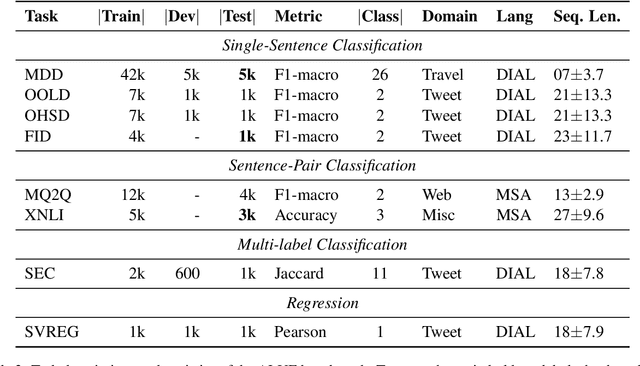
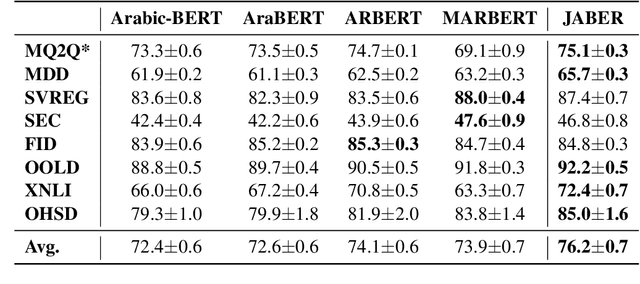
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
ALP-KD: Attention-Based Layer Projection for Knowledge Distillation
Dec 27, 2020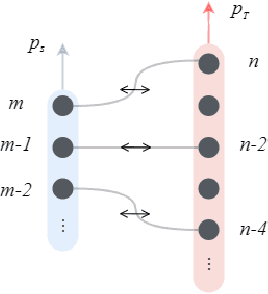
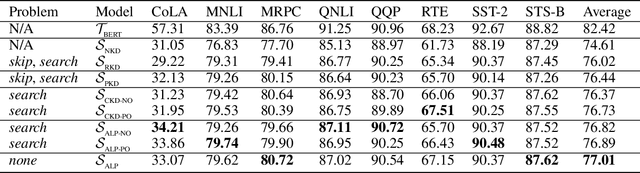
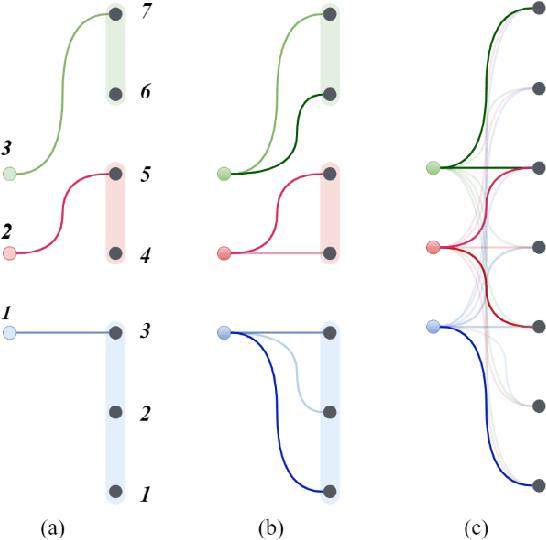
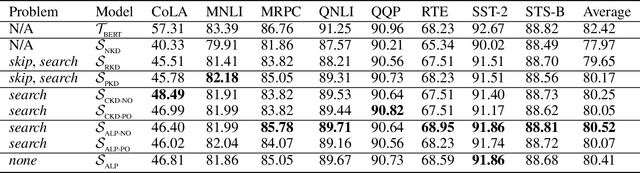
Knowledge distillation is considered as a training and compression strategy in which two neural networks, namely a teacher and a student, are coupled together during training. The teacher network is supposed to be a trustworthy predictor and the student tries to mimic its predictions. Usually, a student with a lighter architecture is selected so we can achieve compression and yet deliver high-quality results. In such a setting, distillation only happens for final predictions whereas the student could also benefit from teacher's supervision for internal components. Motivated by this, we studied the problem of distillation for intermediate layers. Since there might not be a one-to-one alignment between student and teacher layers, existing techniques skip some teacher layers and only distill from a subset of them. This shortcoming directly impacts quality, so we instead propose a combinatorial technique which relies on attention. Our model fuses teacher-side information and takes each layer's significance into consideration, then performs distillation between combined teacher layers and those of the student. Using our technique, we distilled a 12-layer BERT (Devlin et al. 2019) into 6-, 4-, and 2-layer counterparts and evaluated them on GLUE tasks (Wang et al. 2018). Experimental results show that our combinatorial approach is able to outperform other existing techniques.
Why Skip If You Can Combine: A Simple Knowledge Distillation Technique for Intermediate Layers
Oct 06, 2020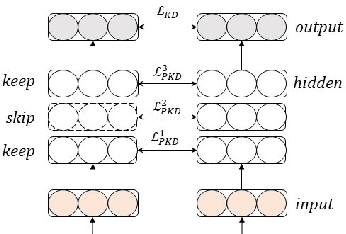
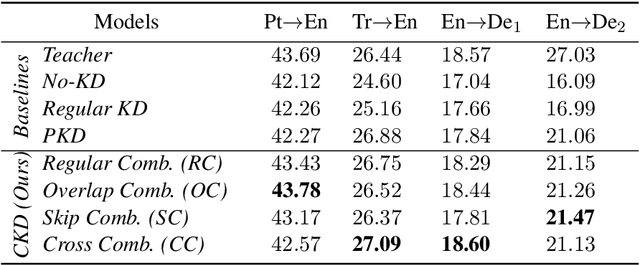
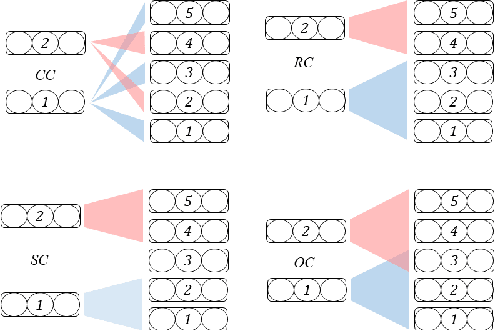
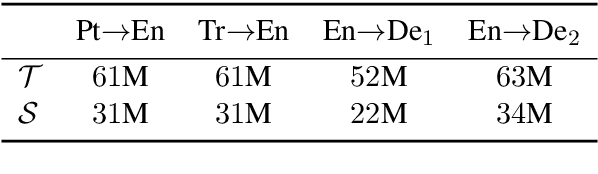
With the growth of computing power neural machine translation (NMT) models also grow accordingly and become better. However, they also become harder to deploy on edge devices due to memory constraints. To cope with this problem, a common practice is to distill knowledge from a large and accurately-trained teacher network (T) into a compact student network (S). Although knowledge distillation (KD) is useful in most cases, our study shows that existing KD techniques might not be suitable enough for deep NMT engines, so we propose a novel alternative. In our model, besides matching T and S predictions we have a combinatorial mechanism to inject layer-level supervision from T to S. In this paper, we target low-resource settings and evaluate our translation engines for Portuguese--English, Turkish--English, and English--German directions. Students trained using our technique have 50% fewer parameters and can still deliver comparable results to those of 12-layer teachers.