 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Network Based on Multi-scale Spatio-temporal Attention for Action Recognition in Videos
Dec 21, 2025Action recognition is a critical task in video understanding, requiring the comprehensive capture of spatio-temporal cues across various scales. However, existing methods often overlook the multi-granularity nature of actions. To address this limitation, we introduce the Context-Aware Network (CAN). CAN consists of two core modules: the Multi-scale Temporal Cue Module (MTCM) and the Group Spatial Cue Module (GSCM). MTCM effectively extracts temporal cues at multiple scales, capturing both fast-changing motion details and overall action flow. GSCM, on the other hand, extracts spatial cues at different scales by grouping feature maps and applying specialized extraction methods to each group. Experiments conducted on five benchmark datasets (Something-Something V1 and V2, Diving48, Kinetics-400, and UCF101) demonstrate the effectiveness of CAN. Our approach achieves competitive performance, outperforming most mainstream methods, with accuracies of 50.4% on Something-Something V1, 63.9% on Something-Something V2, 88.4% on Diving48, 74.9% on Kinetics-400, and 86.9% on UCF101. These results highlight the importance of capturing multi-scale spatio-temporal cues for robust action recognition.
ParaLBench: A Large-Scale Benchmark for Computational Paralinguistics over Acoustic Foundation Models
Nov 14, 2024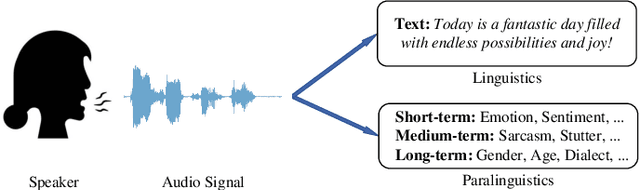
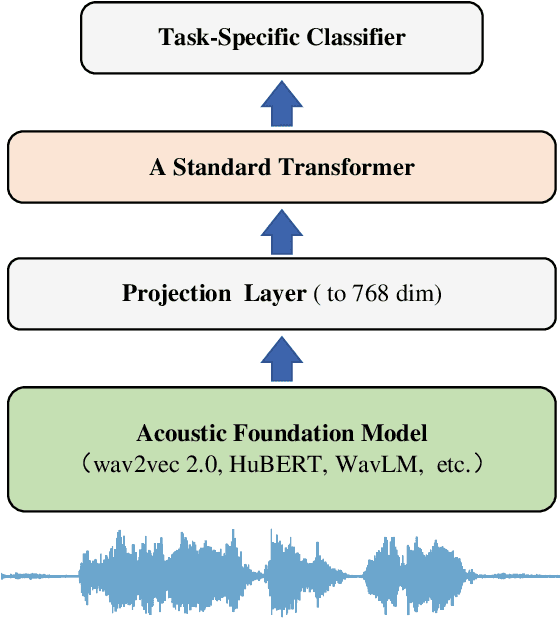
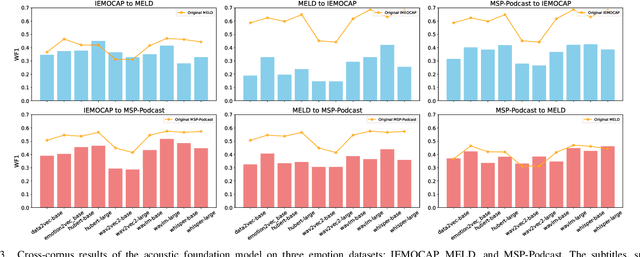
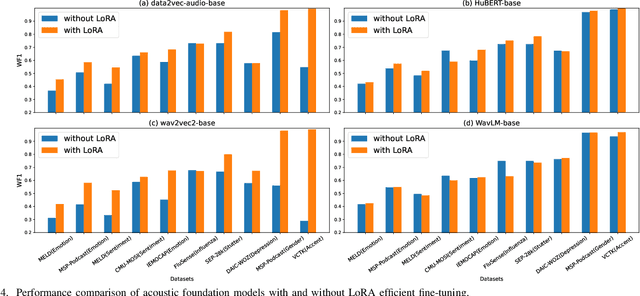
Computational paralinguistics (ComParal) aims to develop algorithms and models to automatically detect, analyze, and interpret non-verbal information from speech communication, e. g., emotion, health state, age, and gender. Despite its rapid progress, it heavily depends on sophisticatedly designed models given specific paralinguistic tasks. Thus, the heterogeneity and diversity of ComParal models largely prevent the realistic implementation of ComParal models. Recently, with the advent of acoustic foundation models because of self-supervised learning, developing more generic models that can efficiently perceive a plethora of paralinguistic information has become an active topic in speech processing. However, it lacks a unified evaluation framework for a fair and consistent performance comparison. To bridge this gap, we conduct a large-scale benchmark, namely ParaLBench, which concentrates on standardizing the evaluation process of diverse paralinguistic tasks, including critical aspects of affective computing such as emotion recognition and emotion dimensions prediction, over different acoustic foundation models. This benchmark contains ten datasets with thirteen distinct paralinguistic tasks, covering short-, medium- and long-term characteristics. Each task is carried out on 14 acoustic foundation models under a unified evaluation framework, which allows for an unbiased methodological comparison and offers a grounded reference for the ComParal community. Based on the insights gained from ParaLBench, we also point out potential research directions, i.e., the cross-corpus generalizability, to propel ComParal research in the future. The code associated with this study will be available to foster the transparency and replicability of this work for succeeding researchers.