 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCR: Geometry-Consistent Routing for Task-Agnostic Continual Anomaly Detection
Jan 08, 2026Feature-based anomaly detection is widely adopted in industrial inspection due to the strong representational power of large pre-trained vision encoders. While most existing methods focus on improving within-category anomaly scoring, practical deployments increasingly require task-agnostic operation under continual category expansion, where the category identity is unknown at test time. In this setting, overall performance is often dominated by expert selection, namely routing an input to an appropriate normality model before any head-specific scoring is applied. However, routing rules that compare head-specific anomaly scores across independently constructed heads are unreliable in practice, as score distributions can differ substantially across categories in scale and tail behavior. We propose GCR, a lightweight mixture-of-experts framework for stabilizing task-agnostic continual anomaly detection through geometry-consistent routing. GCR routes each test image directly in a shared frozen patch-embedding space by minimizing an accumulated nearest-prototype distance to category-specific prototype banks, and then computes anomaly maps only within the routed expert using a standard prototype-based scoring rule. By separating cross-head decision making from within-head anomaly scoring, GCR avoids cross-head score comparability issues without requiring end-to-end representation learning. Experiments on MVTec AD and VisA show that geometry-consistent routing substantially improves routing stability and mitigates continual performance collapse, achieving near-zero forgetting while maintaining competitive detection and localization performance. These results indicate that many failures previously attributed to representation forgetting can instead be explained by decision-rule instability in cross-head routing. Code is available at https://github.com/jw-chae/GCR
ParaLBench: A Large-Scale Benchmark for Computational Paralinguistics over Acoustic Foundation Models
Nov 14, 2024
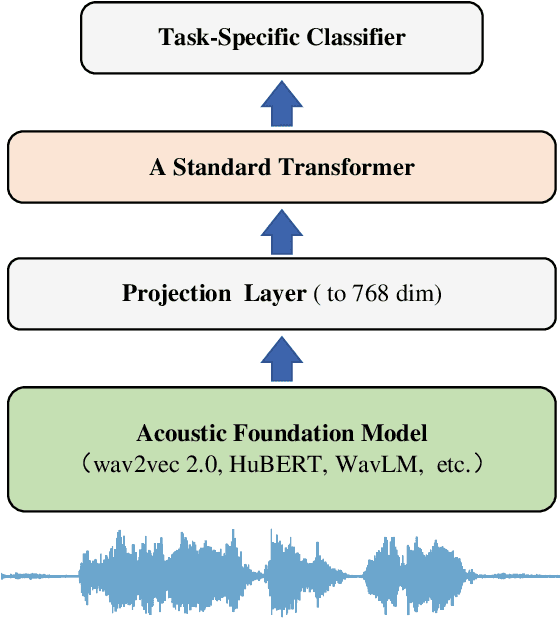
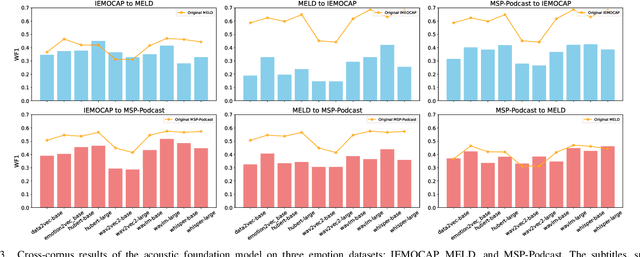
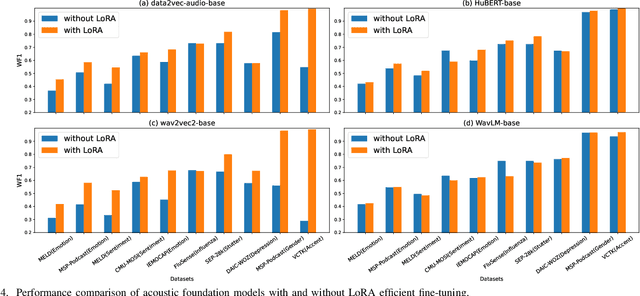
Computational paralinguistics (ComParal) aims to develop algorithms and models to automatically detect, analyze, and interpret non-verbal information from speech communication, e. g., emotion, health state, age, and gender. Despite its rapid progress, it heavily depends on sophisticatedly designed models given specific paralinguistic tasks. Thus, the heterogeneity and diversity of ComParal models largely prevent the realistic implementation of ComParal models. Recently, with the advent of acoustic foundation models because of self-supervised learning, developing more generic models that can efficiently perceive a plethora of paralinguistic information has become an active topic in speech processing. However, it lacks a unified evaluation framework for a fair and consistent performance comparison. To bridge this gap, we conduct a large-scale benchmark, namely ParaLBench, which concentrates on standardizing the evaluation process of diverse paralinguistic tasks, including critical aspects of affective computing such as emotion recognition and emotion dimensions prediction, over different acoustic foundation models. This benchmark contains ten datasets with thirteen distinct paralinguistic tasks, covering short-, medium- and long-term characteristics. Each task is carried out on 14 acoustic foundation models under a unified evaluation framework, which allows for an unbiased methodological comparison and offers a grounded reference for the ComParal community. Based on the insights gained from ParaLBench, we also point out potential research directions, i.e., the cross-corpus generalizability, to propel ComParal research in the future. The code associated with this study will be available to foster the transparency and replicability of this work for succeeding researchers.
Object Detection for Caries or Pit and Fissure Sealing Requirement in Children's First Permanent Molars
Aug 31, 2023Dental caries is one of the most common oral diseases that, if left untreated, can lead to a variety of oral problems. It mainly occurs inside the pits and fissures on the occlusal/buccal/palatal surfaces of molars and children are a high-risk group for pit and fissure caries in permanent molars. Pit and fissure sealing is one of the most effective methods that is widely used in prevention of pit and fissure caries. However, current detection of pits and fissures or caries depends primarily on the experienced dentists, which ordinary parents do not have, and children may miss the remedial treatment without timely detection. To address this issue, we present a method to autodetect caries and pit and fissure sealing requirements using oral photos taken by smartphones. We use the YOLOv5 and YOLOX models and adopt a tiling strategy to reduce information loss during image pre-processing. The best result for YOLOXs model with tiling strategy is 72.3 mAP.5, while the best result without tiling strategy is 71.2. YOLOv5s6 model with/without tiling attains 70.9/67.9 mAP.5, respectively. We deploy the pre-trained network to mobile devices as a WeChat applet, allowing in-home detection by parents or children guardian.
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023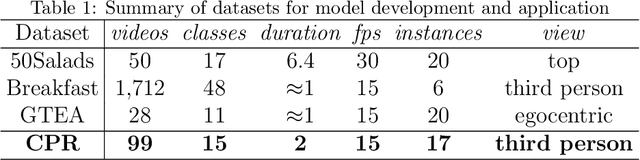
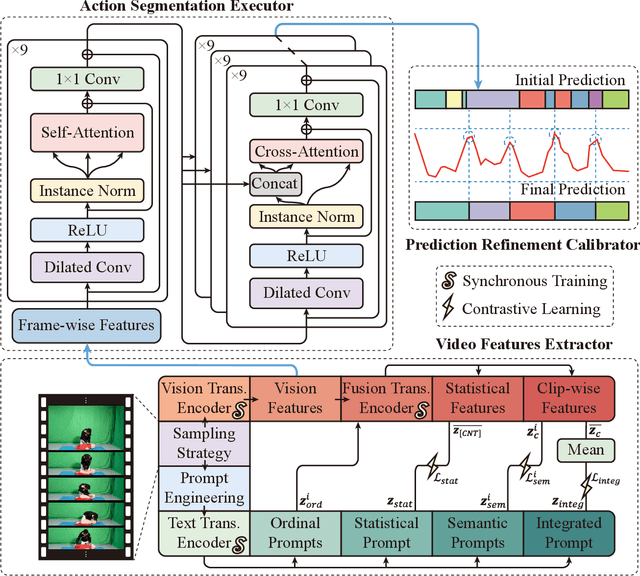
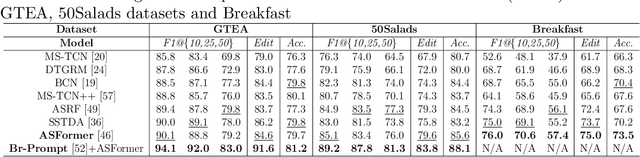

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.