Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJABER and SABER: Junior and Senior Arabic BERt
Paper and Code
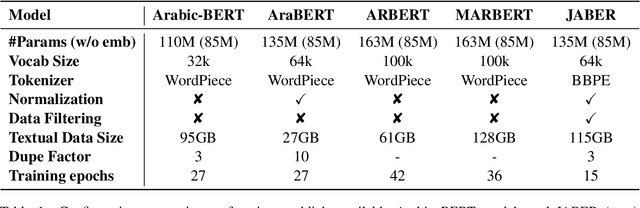
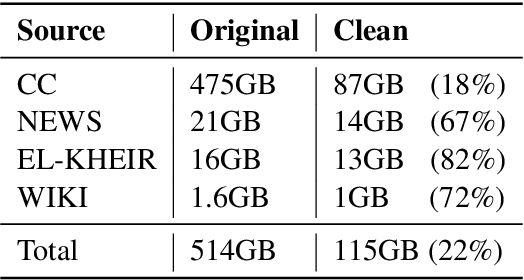
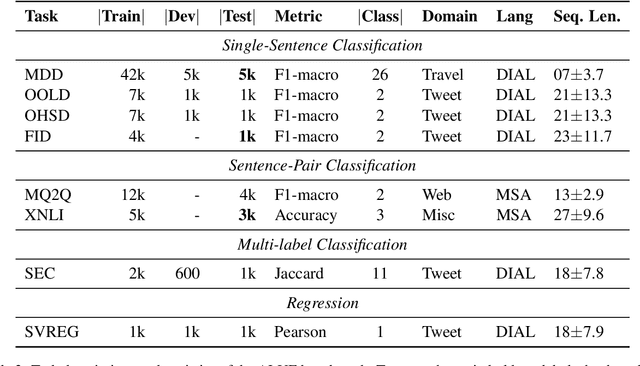
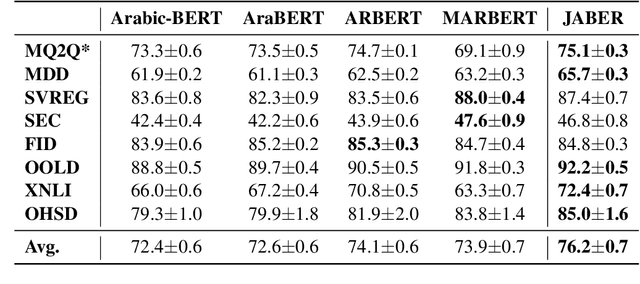
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
* Technical Report; v2: add SABER and CAMeLBERT evaluation; v3: fix
minor typos and grammatical errors
View paper on