 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
Paper and Code

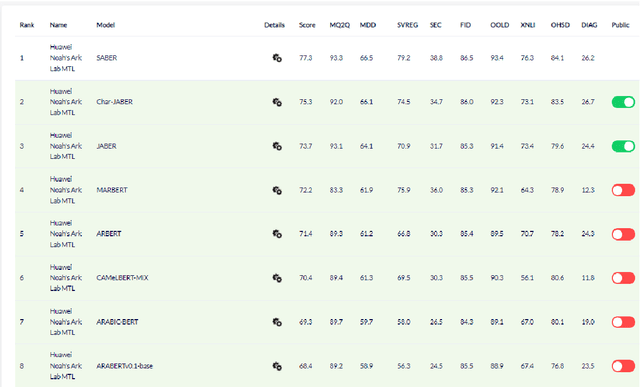

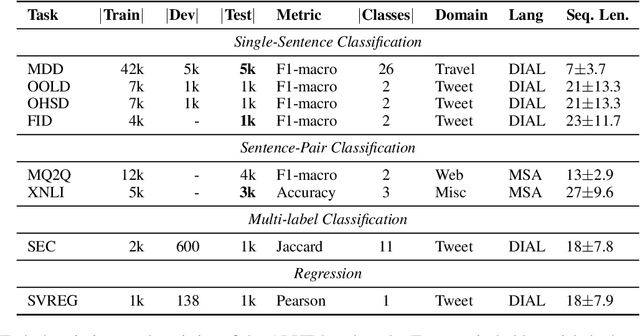
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.